 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiler: Profile-Based Model to Detect Phishing Emails
Aug 18, 2022
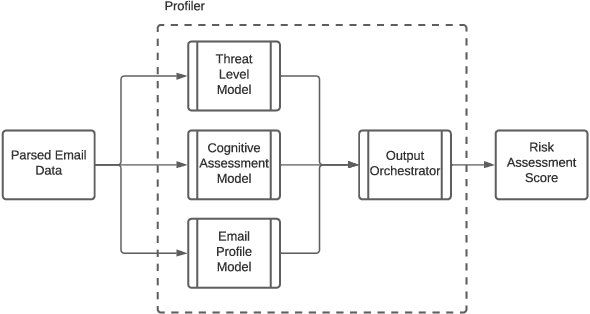
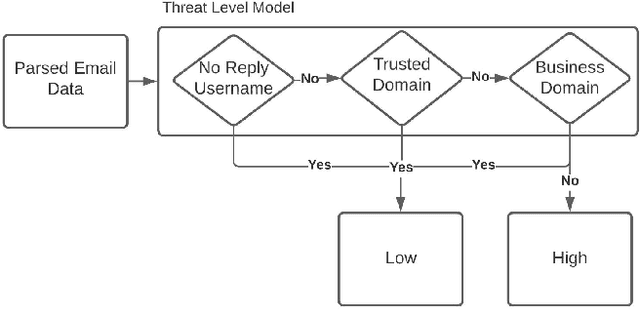
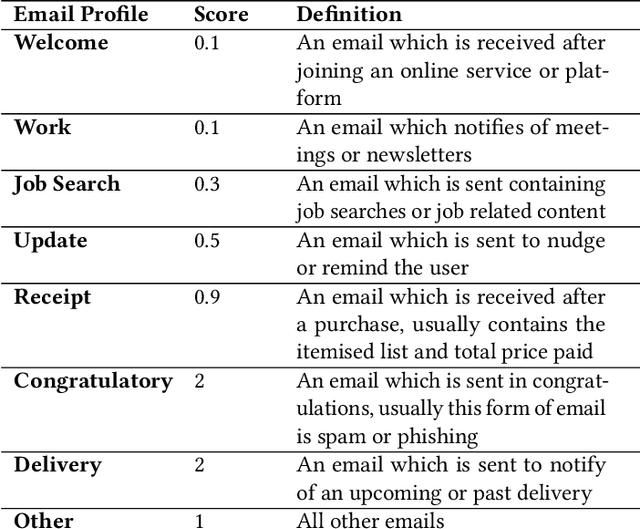
Email phishing has become more prevalent and grows more sophisticated over time. To combat this rise, many machine learning (ML) algorithms for detecting phishing emails have been developed. However, due to the limited email data sets on which these algorithms train, they are not adept at recognising varied attacks and, thus, suffer from concept drift; attackers can introduce small changes in the statistical characteristics of their emails or websites to successfully bypass detection. Over time, a gap develops between the reported accuracy from literature and the algorithm's actual effectiveness in the real world. This realises itself in frequent false positive and false negative classifications. To this end, we propose a multidimensional risk assessment of emails to reduce the feasibility of an attacker adapting their email and avoiding detection. This horizontal approach to email phishing detection profiles an incoming email on its main features. We develop a risk assessment framework that includes three models which analyse an email's (1) threat level, (2) cognitive manipulation, and (3) email type, which we combine to return the final risk assessment score. The Profiler does not require large data sets to train on to be effective and its analysis of varied email features reduces the impact of concept drift. Our Profiler can be used in conjunction with ML approaches, to reduce their misclassifications or as a labeller for large email data sets in the training stage. We evaluate the efficacy of the Profiler against a machine learning ensemble using state-of-the-art ML algorithms on a data set of 9000 legitimate and 900 phishing emails from a large Australian research organisation. Our results indicate that the Profiler's mitigates the impact of concept drift, and delivers 30% less false positive and 25% less false negative email classifications over the ML ensemble's approach.
* 12 pages
Towards Web Phishing Detection Limitations and Mitigation
Apr 03, 2022



Web phishing remains a serious cyber threat responsible for most data breaches. Machine Learning (ML)-based anti-phishing detectors are seen as an effective countermeasure, and are increasingly adopted by web-browsers and software products. However, with an average of 10K phishing links reported per hour to platforms such as PhishTank and VirusTotal (VT), the deficiencies of such ML-based solutions are laid bare. We first explore how phishing sites bypass ML-based detection with a deep dive into 13K phishing pages targeting major brands such as Facebook. Results show successful evasion is caused by: (1) use of benign services to obscure phishing URLs; (2) high similarity between the HTML structures of phishing and benign pages; (3) hiding the ultimate phishing content within Javascript and running such scripts only on the client; (4) looking beyond typical credentials and credit cards for new content such as IDs and documents; (5) hiding phishing content until after human interaction. We attribute the root cause to the dependency of ML-based models on the vertical feature space (webpage content). These solutions rely only on what phishers present within the page itself. Thus, we propose Anti-SubtlePhish, a more resilient model based on logistic regression. The key augmentation is the inclusion of a horizontal feature space, which examines correlation variables between the final render of suspicious pages against what trusted services have recorded (e.g., PageRank). To defeat (1) and (2), we correlate information between WHOIS, PageRank, and page analytics. To combat (3), (4) and (5), we correlate features after rendering the page. Experiments with 100K phishing/benign sites show promising accuracy (98.8%). We also obtained 100% accuracy against 0-day phishing pages that were manually crafted, comparing well to the 0% recorded by VT vendors over the first four days.
Characterizing Malicious URL Campaigns
Aug 29, 2021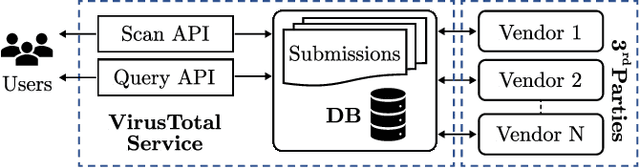

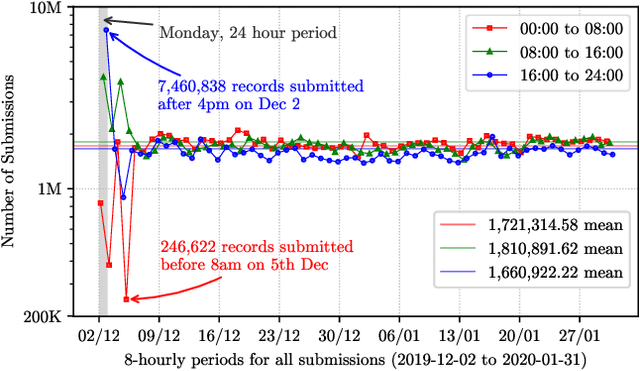
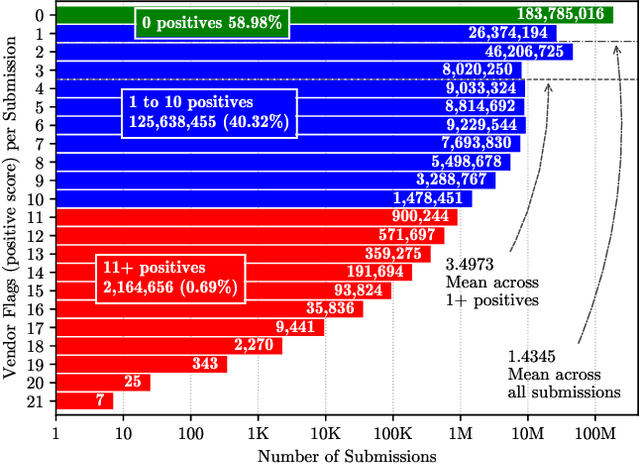
URLs are central to a myriad of cyber-security threats, from phishing to the distribution of malware. Their inherent ease of use and familiarity is continuously abused by attackers to evade defences and deceive end-users. Seemingly dissimilar URLs are being used in an organized way to perform phishing attacks and distribute malware. We refer to such behaviours as campaigns, with the hypothesis being that attacks are often coordinated to maximize success rates and develop evasion tactics. The aim is to gain better insights into campaigns, bolster our grasp of their characteristics, and thus aid the community devise more robust solutions. To this end, we performed extensive research and analysis into 311M records containing 77M unique real-world URLs that were submitted to VirusTotal from Dec 2019 to Jan 2020. From this dataset, 2.6M suspicious campaigns were identified based on their attached metadata, of which 77,810 were doubly verified as malicious. Using the 38.1M records and 9.9M URLs within these malicious campaigns, we provide varied insights such as their targeted victim brands as well as URL sizes and heterogeneity. Some surprising findings were observed, such as detection rates falling to just 13.27% for campaigns that employ more than 100 unique URLs. The paper concludes with several case-studies that illustrate the common malicious techniques employed by attackers to imperil users and circumvent defences.
ReinforceBug: A Framework to Generate Adversarial Textual Examples
Mar 11, 2021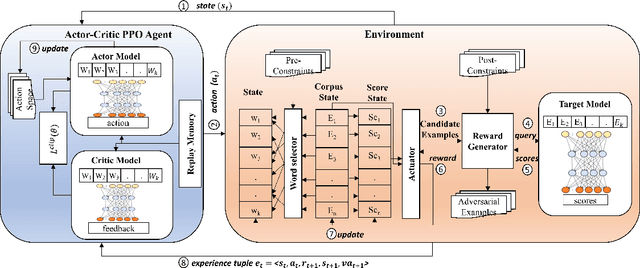
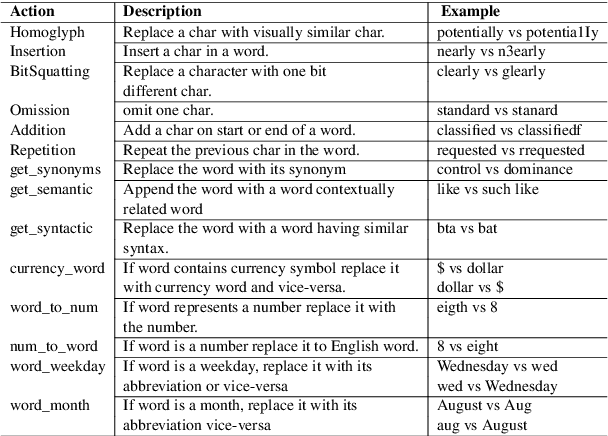


Adversarial Examples (AEs) generated by perturbing original training examples are useful in improving the robustness of Deep Learning (DL) based models. Most prior works, generate AEs that are either unconscionable due to lexical errors or semantically or functionally deviant from original examples. In this paper, we present ReinforceBug, a reinforcement learning framework, that learns a policy that is transferable on unseen datasets and generates utility-preserving and transferable (on other models) AEs. Our results show that our method is on average 10% more successful as compared to the state-of-the-art attack TextFooler. Moreover, the target models have on average 73.64% confidence in the wrong prediction, the generated AEs preserve the functional equivalence and semantic similarity (83.38% ) to their original counterparts, and are transferable on other models with an average success rate of 46%.
Machine Learning for Detecting Data Exfiltration
Dec 17, 2020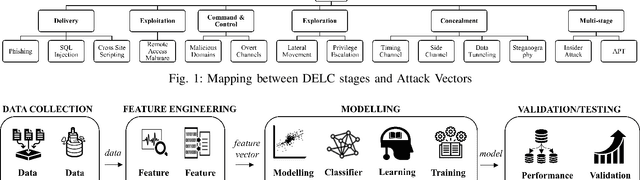

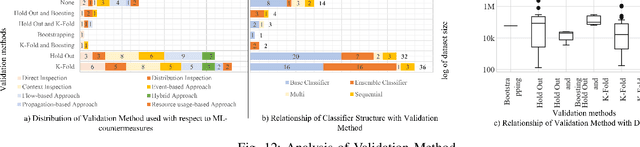
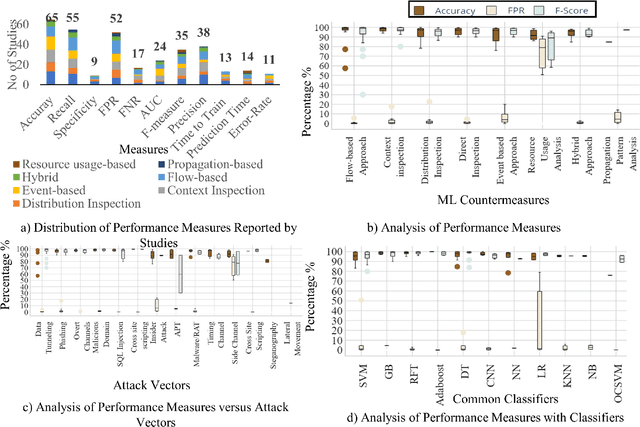
Context: Research at the intersection of cybersecurity, Machine Learning (ML), and Software Engineering (SE) has recently taken significant steps in proposing countermeasures for detecting sophisticated data exfiltration attacks. It is important to systematically review and synthesize the ML-based data exfiltration countermeasures for building a body of knowledge on this important topic. Objective: This paper aims at systematically reviewing ML-based data exfiltration countermeasures to identify and classify ML approaches, feature engineering techniques, evaluation datasets, and performance metrics used for these countermeasures. This review also aims at identifying gaps in research on ML-based data exfiltration countermeasures. Method: We used a Systematic Literature Review (SLR) method to select and review {92} papers. Results: The review has enabled us to (a) classify the ML approaches used in the countermeasures into data-driven, and behaviour-driven approaches, (b) categorize features into six types: behavioural, content-based, statistical, syntactical, spatial and temporal, (c) classify the evaluation datasets into simulated, synthesized, and real datasets and (d) identify 11 performance measures used by these studies. Conclusion: We conclude that: (i) the integration of data-driven and behaviour-driven approaches should be explored; (ii) There is a need of developing high quality and large size evaluation datasets; (iii) Incremental ML model training should be incorporated in countermeasures; (iv) resilience to adversarial learning should be considered and explored during the development of countermeasures to avoid poisoning attacks; and (v) the use of automated feature engineering should be encouraged for efficiently detecting data exfiltration attacks.
An Evasion Attack against ML-based Phishing URL Detectors
May 18, 2020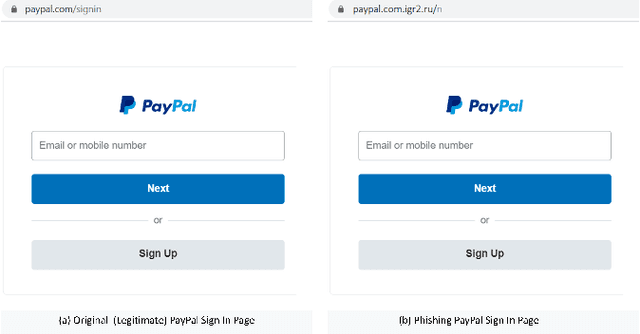

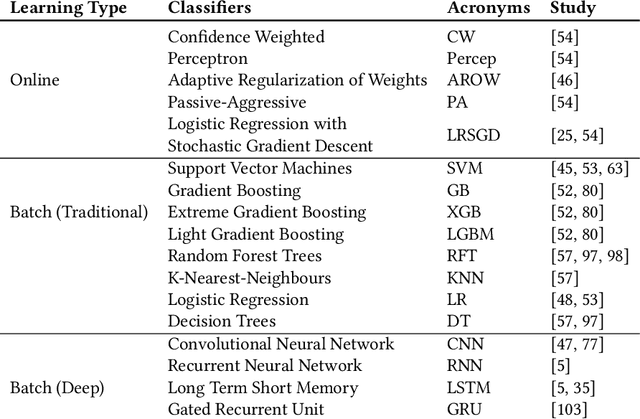
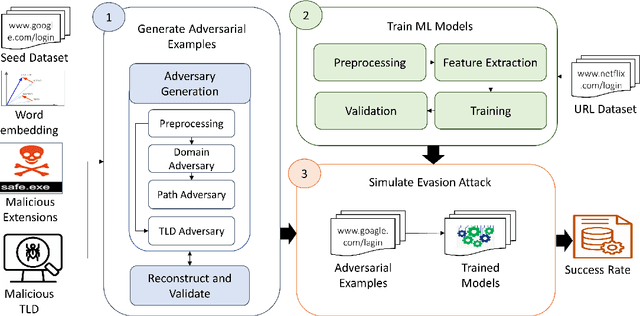
Background: Over the year, Machine Learning Phishing URL classification (MLPU) systems have gained tremendous popularity to detect phishing URLs proactively. Despite this vogue, the security vulnerabilities of MLPUs remain mostly unknown. Aim: To address this concern, we conduct a study to understand the test time security vulnerabilities of the state-of-the-art MLPU systems, aiming at providing guidelines for the future development of these systems. Method: In this paper, we propose an evasion attack framework against MLPU systems. To achieve this, we first develop an algorithm to generate adversarial phishing URLs. We then reproduce 41 MLPU systems and record their baseline performance. Finally, we simulate an evasion attack to evaluate these MLPU systems against our generated adversarial URLs. Results: In comparison to previous works, our attack is: (i) effective as it evades all the models with an average success rate of 66% and 85% for famous (such as Netflix, Google) and less popular phishing targets (e.g., Wish, JBHIFI, Officeworks) respectively; (ii) realistic as it requires only 23ms to produce a new adversarial URL variant that is available for registration with a median cost of only $11.99/year. We also found that popular online services such as Google SafeBrowsing and VirusTotal are unable to detect these URLs. (iii) We find that Adversarial training (successful defence against evasion attack) does not significantly improve the robustness of these systems as it decreases the success rate of our attack by only 6% on average for all the models. (iv) Further, we identify the security vulnerabilities of the considered MLPU systems. Our findings lead to promising directions for future research. Conclusion: Our study not only illustrate vulnerabilities in MLPU systems but also highlights implications for future study towards assessing and improving these systems.