 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Interpretability and Transparency-Driven Detection and Transformation of Textual Adversarial Examples (IT-DT)
Jul 03, 2023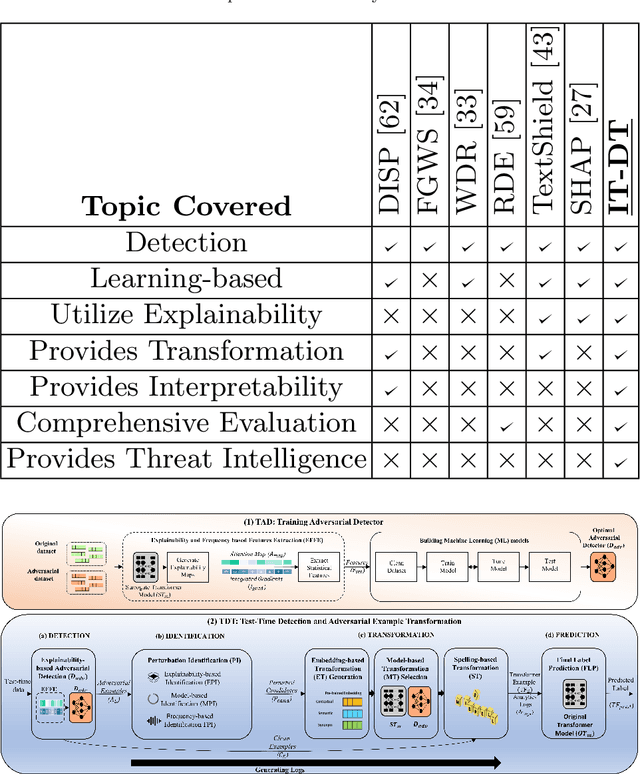



Transformer-based text classifiers like BERT, Roberta, T5, and GPT-3 have shown impressive performance in NLP. However, their vulnerability to adversarial examples poses a security risk. Existing defense methods lack interpretability, making it hard to understand adversarial classifications and identify model vulnerabilities. To address this, we propose the Interpretability and Transparency-Driven Detection and Transformation (IT-DT) framework. It focuses on interpretability and transparency in detecting and transforming textual adversarial examples. IT-DT utilizes techniques like attention maps, integrated gradients, and model feedback for interpretability during detection. This helps identify salient features and perturbed words contributing to adversarial classifications. In the transformation phase, IT-DT uses pre-trained embeddings and model feedback to generate optimal replacements for perturbed words. By finding suitable substitutions, we aim to convert adversarial examples into non-adversarial counterparts that align with the model's intended behavior while preserving the text's meaning. Transparency is emphasized through human expert involvement. Experts review and provide feedback on detection and transformation results, enhancing decision-making, especially in complex scenarios. The framework generates insights and threat intelligence empowering analysts to identify vulnerabilities and improve model robustness. Comprehensive experiments demonstrate the effectiveness of IT-DT in detecting and transforming adversarial examples. The approach enhances interpretability, provides transparency, and enables accurate identification and successful transformation of adversarial inputs. By combining technical analysis and human expertise, IT-DT significantly improves the resilience and trustworthiness of transformer-based text classifiers against adversarial attacks.
ReinforceBug: A Framework to Generate Adversarial Textual Examples
Mar 11, 2021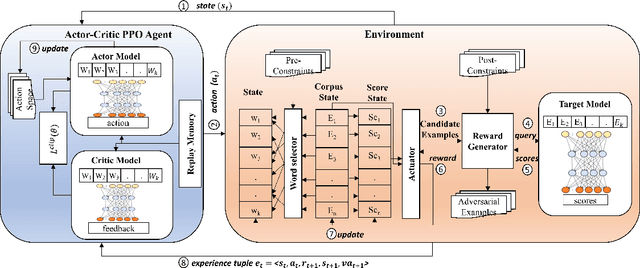
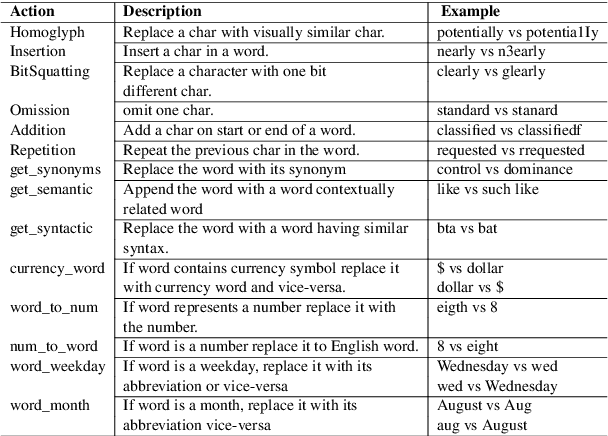


Adversarial Examples (AEs) generated by perturbing original training examples are useful in improving the robustness of Deep Learning (DL) based models. Most prior works, generate AEs that are either unconscionable due to lexical errors or semantically or functionally deviant from original examples. In this paper, we present ReinforceBug, a reinforcement learning framework, that learns a policy that is transferable on unseen datasets and generates utility-preserving and transferable (on other models) AEs. Our results show that our method is on average 10% more successful as compared to the state-of-the-art attack TextFooler. Moreover, the target models have on average 73.64% confidence in the wrong prediction, the generated AEs preserve the functional equivalence and semantic similarity (83.38% ) to their original counterparts, and are transferable on other models with an average success rate of 46%.
Machine Learning for Detecting Data Exfiltration
Dec 17, 2020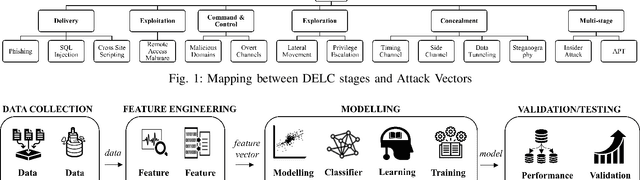

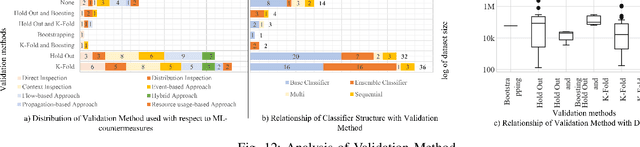
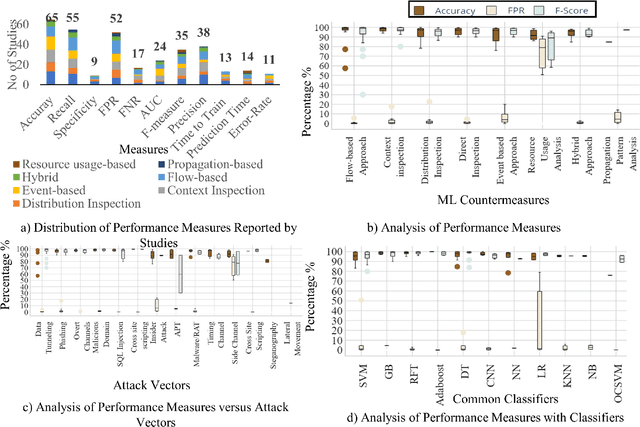
Context: Research at the intersection of cybersecurity, Machine Learning (ML), and Software Engineering (SE) has recently taken significant steps in proposing countermeasures for detecting sophisticated data exfiltration attacks. It is important to systematically review and synthesize the ML-based data exfiltration countermeasures for building a body of knowledge on this important topic. Objective: This paper aims at systematically reviewing ML-based data exfiltration countermeasures to identify and classify ML approaches, feature engineering techniques, evaluation datasets, and performance metrics used for these countermeasures. This review also aims at identifying gaps in research on ML-based data exfiltration countermeasures. Method: We used a Systematic Literature Review (SLR) method to select and review {92} papers. Results: The review has enabled us to (a) classify the ML approaches used in the countermeasures into data-driven, and behaviour-driven approaches, (b) categorize features into six types: behavioural, content-based, statistical, syntactical, spatial and temporal, (c) classify the evaluation datasets into simulated, synthesized, and real datasets and (d) identify 11 performance measures used by these studies. Conclusion: We conclude that: (i) the integration of data-driven and behaviour-driven approaches should be explored; (ii) There is a need of developing high quality and large size evaluation datasets; (iii) Incremental ML model training should be incorporated in countermeasures; (iv) resilience to adversarial learning should be considered and explored during the development of countermeasures to avoid poisoning attacks; and (v) the use of automated feature engineering should be encouraged for efficiently detecting data exfiltration attacks.
An Evasion Attack against ML-based Phishing URL Detectors
May 18, 2020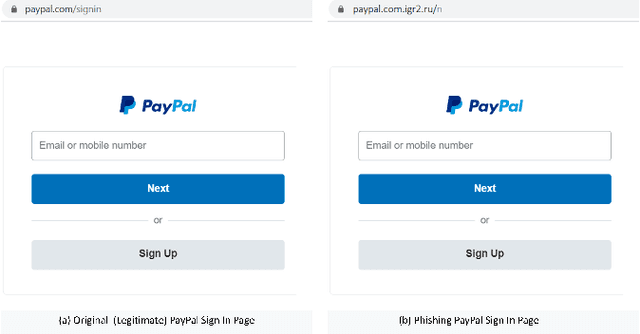

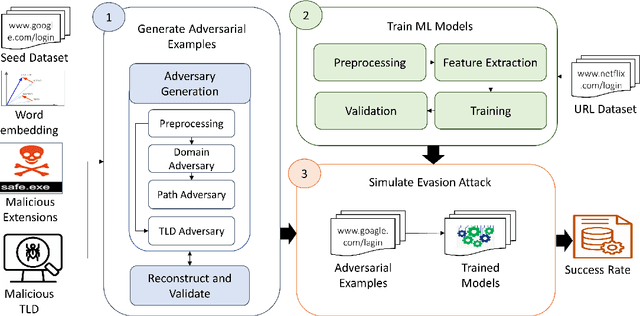
Background: Over the year, Machine Learning Phishing URL classification (MLPU) systems have gained tremendous popularity to detect phishing URLs proactively. Despite this vogue, the security vulnerabilities of MLPUs remain mostly unknown. Aim: To address this concern, we conduct a study to understand the test time security vulnerabilities of the state-of-the-art MLPU systems, aiming at providing guidelines for the future development of these systems. Method: In this paper, we propose an evasion attack framework against MLPU systems. To achieve this, we first develop an algorithm to generate adversarial phishing URLs. We then reproduce 41 MLPU systems and record their baseline performance. Finally, we simulate an evasion attack to evaluate these MLPU systems against our generated adversarial URLs. Results: In comparison to previous works, our attack is: (i) effective as it evades all the models with an average success rate of 66% and 85% for famous (such as Netflix, Google) and less popular phishing targets (e.g., Wish, JBHIFI, Officeworks) respectively; (ii) realistic as it requires only 23ms to produce a new adversarial URL variant that is available for registration with a median cost of only $11.99/year. We also found that popular online services such as Google SafeBrowsing and VirusTotal are unable to detect these URLs. (iii) We find that Adversarial training (successful defence against evasion attack) does not significantly improve the robustness of these systems as it decreases the success rate of our attack by only 6% on average for all the models. (iv) Further, we identify the security vulnerabilities of the considered MLPU systems. Our findings lead to promising directions for future research. Conclusion: Our study not only illustrate vulnerabilities in MLPU systems but also highlights implications for future study towards assessing and improving these systems.