 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforceBug: A Framework to Generate Adversarial Textual Examples
Paper and Code
Mar 11, 2021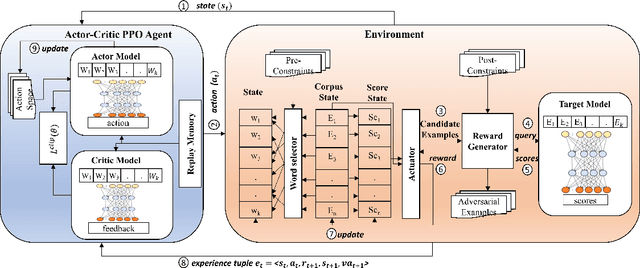
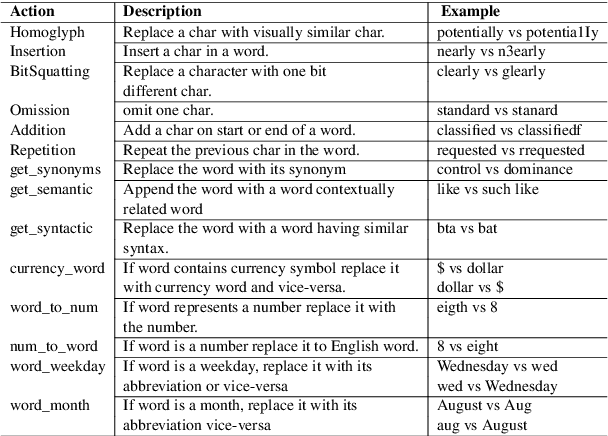


Adversarial Examples (AEs) generated by perturbing original training examples are useful in improving the robustness of Deep Learning (DL) based models. Most prior works, generate AEs that are either unconscionable due to lexical errors or semantically or functionally deviant from original examples. In this paper, we present ReinforceBug, a reinforcement learning framework, that learns a policy that is transferable on unseen datasets and generates utility-preserving and transferable (on other models) AEs. Our results show that our method is on average 10% more successful as compared to the state-of-the-art attack TextFooler. Moreover, the target models have on average 73.64% confidence in the wrong prediction, the generated AEs preserve the functional equivalence and semantic similarity (83.38% ) to their original counterparts, and are transferable on other models with an average success rate of 46%.