 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability and Transparency-Driven Detection and Transformation of Textual Adversarial Examples (IT-DT)
Paper and Code
Jul 03, 2023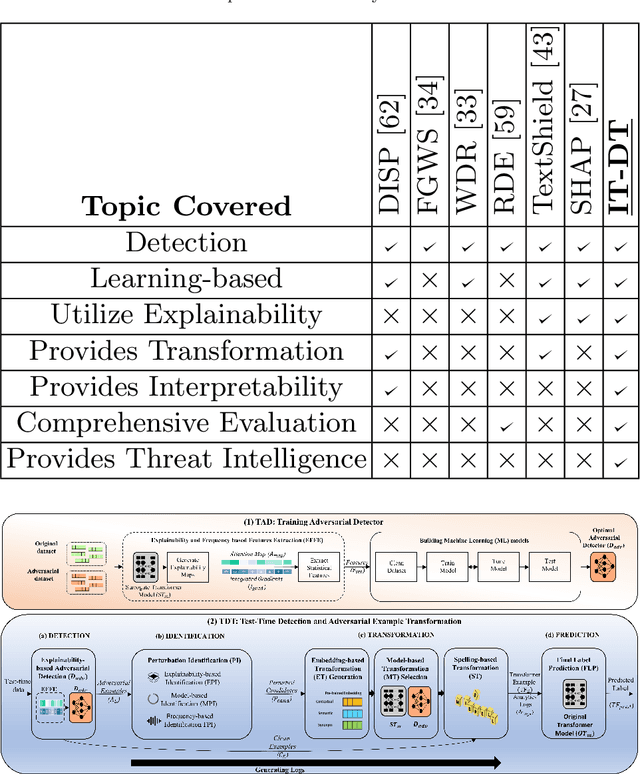



Transformer-based text classifiers like BERT, Roberta, T5, and GPT-3 have shown impressive performance in NLP. However, their vulnerability to adversarial examples poses a security risk. Existing defense methods lack interpretability, making it hard to understand adversarial classifications and identify model vulnerabilities. To address this, we propose the Interpretability and Transparency-Driven Detection and Transformation (IT-DT) framework. It focuses on interpretability and transparency in detecting and transforming textual adversarial examples. IT-DT utilizes techniques like attention maps, integrated gradients, and model feedback for interpretability during detection. This helps identify salient features and perturbed words contributing to adversarial classifications. In the transformation phase, IT-DT uses pre-trained embeddings and model feedback to generate optimal replacements for perturbed words. By finding suitable substitutions, we aim to convert adversarial examples into non-adversarial counterparts that align with the model's intended behavior while preserving the text's meaning. Transparency is emphasized through human expert involvement. Experts review and provide feedback on detection and transformation results, enhancing decision-making, especially in complex scenarios. The framework generates insights and threat intelligence empowering analysts to identify vulnerabilities and improve model robustness. Comprehensive experiments demonstrate the effectiveness of IT-DT in detecting and transforming adversarial examples. The approach enhances interpretability, provides transparency, and enables accurate identification and successful transformation of adversarial inputs. By combining technical analysis and human expertise, IT-DT significantly improves the resilience and trustworthiness of transformer-based text classifiers against adversarial attacks.