 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiler: Profile-Based Model to Detect Phishing Emails
Aug 18, 2022
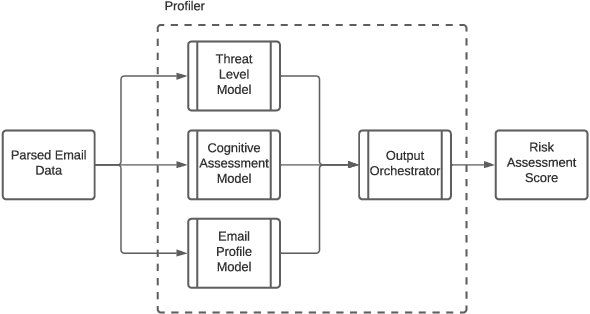
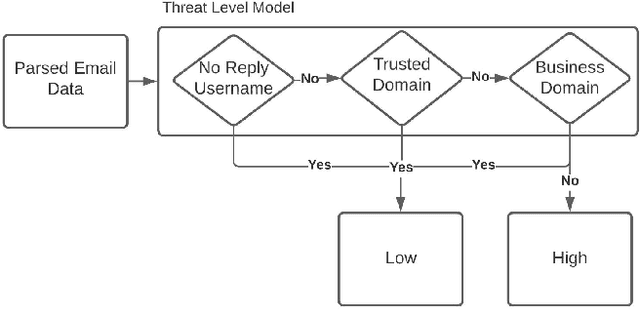
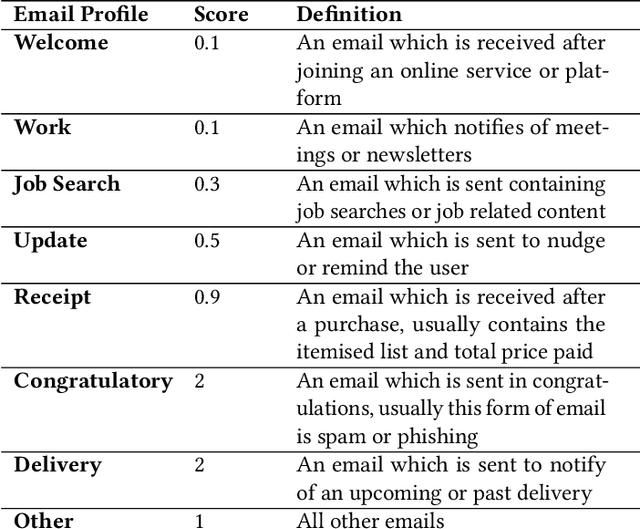
Email phishing has become more prevalent and grows more sophisticated over time. To combat this rise, many machine learning (ML) algorithms for detecting phishing emails have been developed. However, due to the limited email data sets on which these algorithms train, they are not adept at recognising varied attacks and, thus, suffer from concept drift; attackers can introduce small changes in the statistical characteristics of their emails or websites to successfully bypass detection. Over time, a gap develops between the reported accuracy from literature and the algorithm's actual effectiveness in the real world. This realises itself in frequent false positive and false negative classifications. To this end, we propose a multidimensional risk assessment of emails to reduce the feasibility of an attacker adapting their email and avoiding detection. This horizontal approach to email phishing detection profiles an incoming email on its main features. We develop a risk assessment framework that includes three models which analyse an email's (1) threat level, (2) cognitive manipulation, and (3) email type, which we combine to return the final risk assessment score. The Profiler does not require large data sets to train on to be effective and its analysis of varied email features reduces the impact of concept drift. Our Profiler can be used in conjunction with ML approaches, to reduce their misclassifications or as a labeller for large email data sets in the training stage. We evaluate the efficacy of the Profiler against a machine learning ensemble using state-of-the-art ML algorithms on a data set of 9000 legitimate and 900 phishing emails from a large Australian research organisation. Our results indicate that the Profiler's mitigates the impact of concept drift, and delivers 30% less false positive and 25% less false negative email classifications over the ML ensemble's approach.
* 12 pages