 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fuzzy Based Model to Identify Printed Sinhala Characters
Dec 24, 2014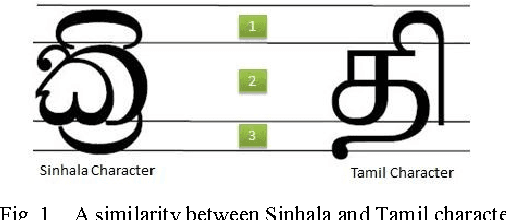
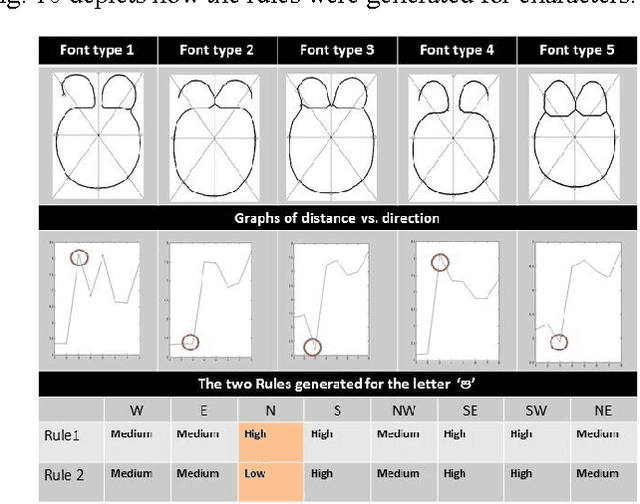
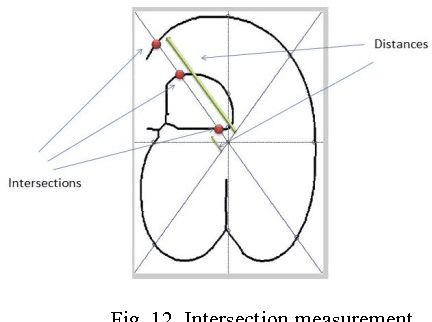
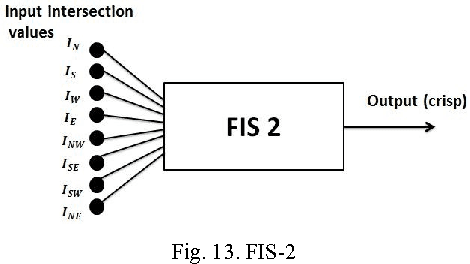
Character recognition techniques for printed documents are widely used for English language. However, the systems that are implemented to recognize Asian languages struggle to increase the accuracy of recognition. Among other Asian languages (such as Arabic, Tamil, Chinese), Sinhala characters are unique, mainly because they are round in shape. This unique feature makes it a challenge to extend the prevailing techniques to improve recognition of Sinhala characters. Therefore, a little attention has been given to improve the accuracy of Sinhala character recognition. A novel method, which makes use of this unique feature, could be advantageous over other methods. This paper describes the use of a fuzzy inference system to recognize Sinhala characters. Feature extraction is mainly focused on distance and intersection measurements in different directions from the center of the letter making use of the round shape of characters. The results showed an overall accuracy of 90.7% for 140 instances of letters tested, much better than similar systems.