 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fuzzy Based Model to Identify Printed Sinhala Characters
Dec 24, 2014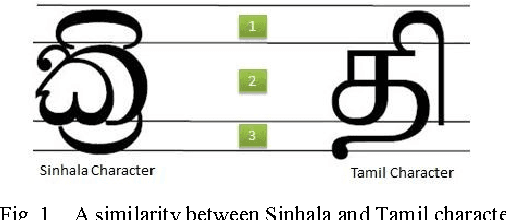
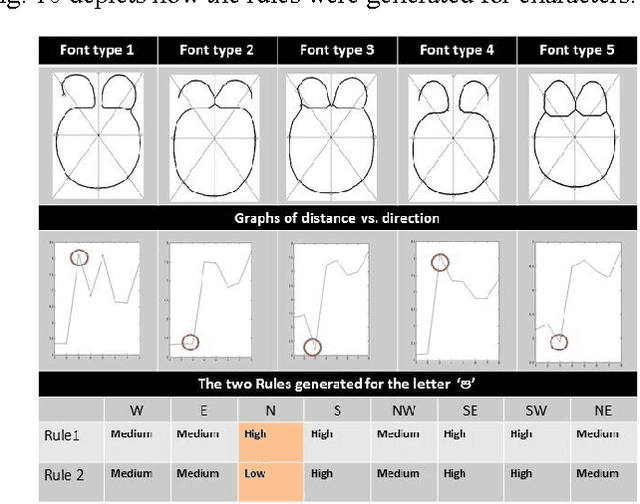
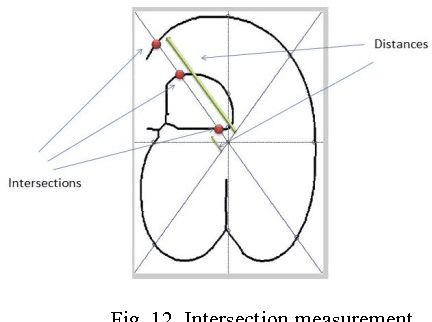
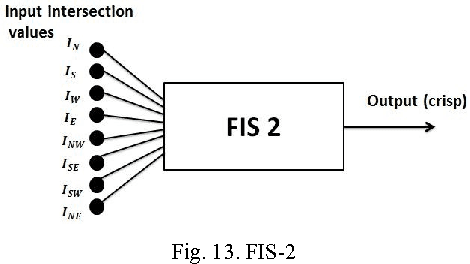
Character recognition techniques for printed documents are widely used for English language. However, the systems that are implemented to recognize Asian languages struggle to increase the accuracy of recognition. Among other Asian languages (such as Arabic, Tamil, Chinese), Sinhala characters are unique, mainly because they are round in shape. This unique feature makes it a challenge to extend the prevailing techniques to improve recognition of Sinhala characters. Therefore, a little attention has been given to improve the accuracy of Sinhala character recognition. A novel method, which makes use of this unique feature, could be advantageous over other methods. This paper describes the use of a fuzzy inference system to recognize Sinhala characters. Feature extraction is mainly focused on distance and intersection measurements in different directions from the center of the letter making use of the round shape of characters. The results showed an overall accuracy of 90.7% for 140 instances of letters tested, much better than similar systems.
Authorship detection of SMS messages using unigrams
Mar 06, 2014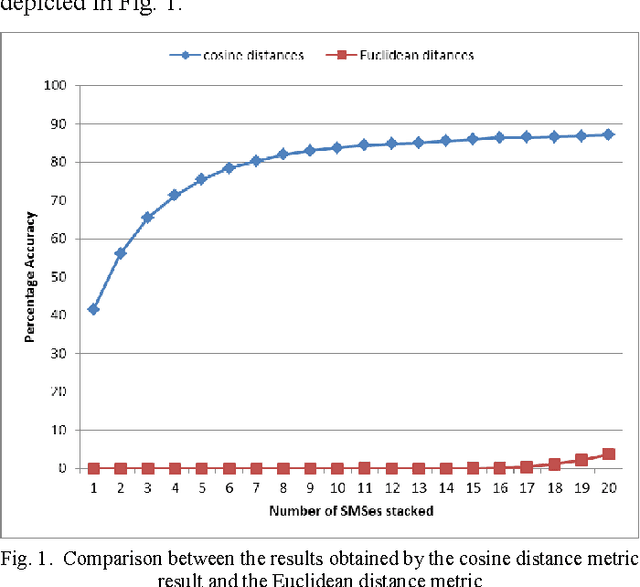
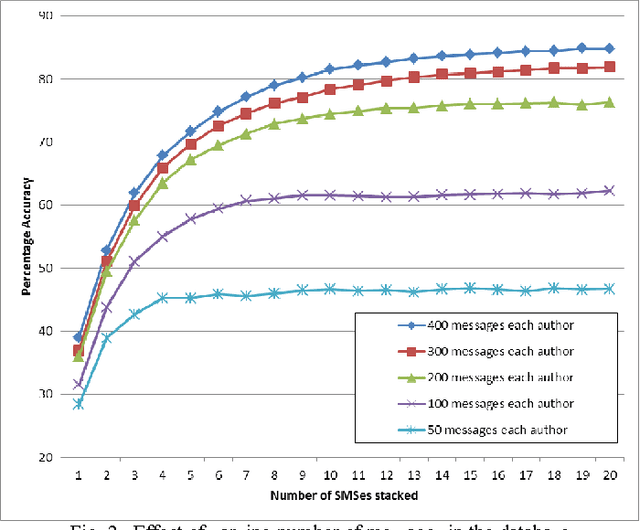
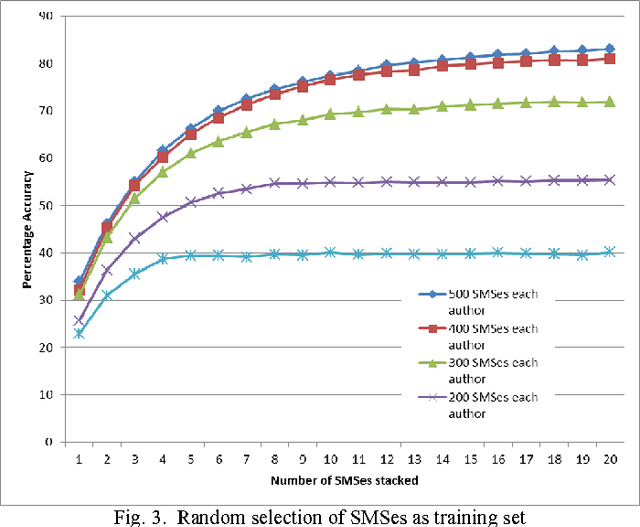
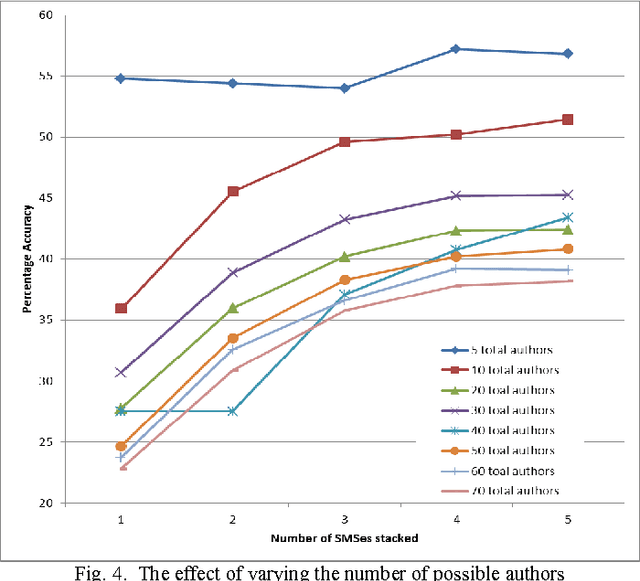
SMS messaging is a popular media of communication. Because of its popularity and privacy, it could be used for many illegal purposes. Additionally, since they are part of the day to day life, SMSes can be used as evidence for many legal disputes. Since a cellular phone might be accessible to people close to the owner, it is important to establish the fact that the sender of the message is indeed the owner of the phone. For this purpose, the straight forward solutions seem to be the use of popular stylometric methods. However, in comparison with the data used for stylometry in the literature, SMSes have unusual characteristics making it hard or impossible to apply these methods in a conventional way. Our target is to come up with a method of authorship detection of SMS messages that could still give a usable accuracy. We argue that, considering the methods of author attribution, the best method that could be applied to SMS messages is an n-gram method. To prove our point, we checked two different methods of distribution comparison with varying number of training and testing data. We specifically try to compare how well our algorithms work under less amount of testing data and large number of candidate authors (which we believe to be the real world scenario) against controlled tests with less number of authors and selected SMSes with large number of words. To counter the lack of information in an SMS message, we propose the method of stacking together few SMSes.
AntiPlag: Plagiarism Detection on Electronic Submissions of Text Based Assignments
Mar 06, 2014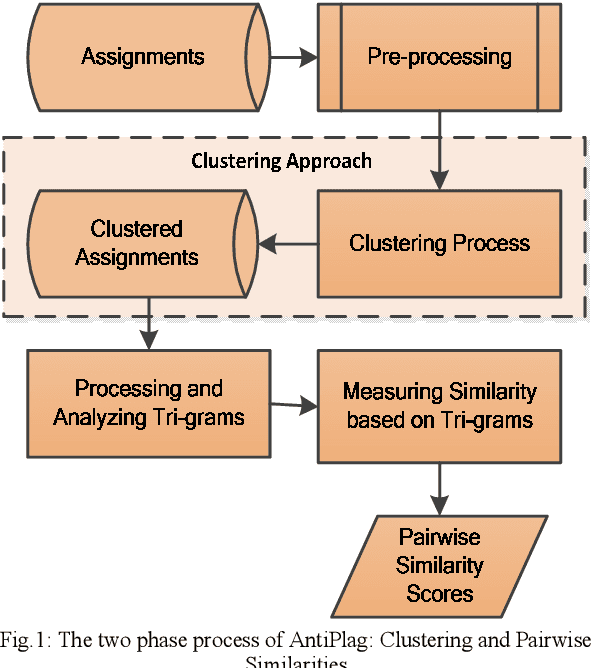
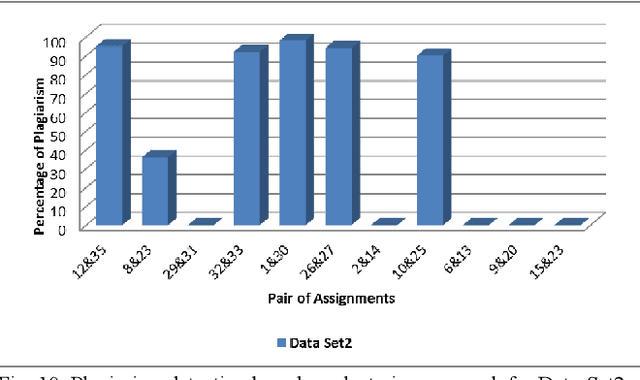
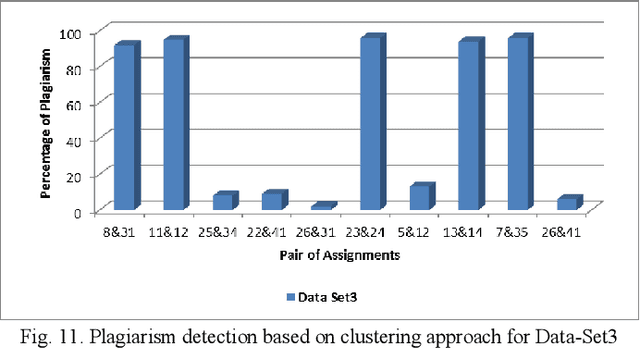
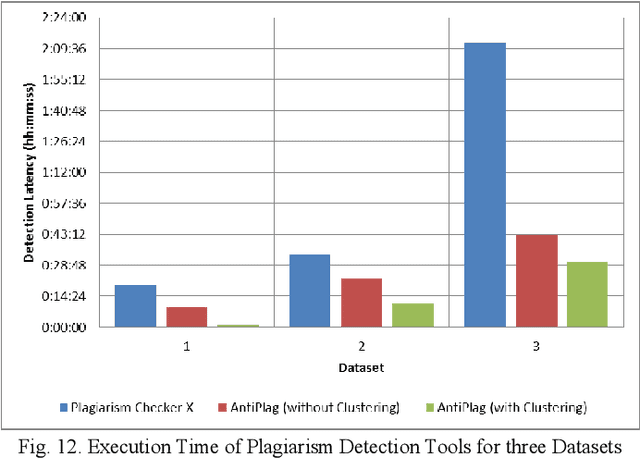
Plagiarism is one of the growing issues in academia and is always a concern in Universities and other academic institutions. The situation is becoming even worse with the availability of ample resources on the web. This paper focuses on creating an effective and fast tool for plagiarism detection for text based electronic assignments. Our plagiarism detection tool named AntiPlag is developed using the tri-gram sequence matching technique. Three sets of text based assignments were tested by AntiPlag and the results were compared against an existing commercial plagiarism detection tool. AntiPlag showed better results in terms of false positives compared to the commercial tool due to the pre-processing steps performed in AntiPlag. In addition, to improve the detection latency, AntiPlag applies a data clustering technique making it four times faster than the commercial tool considered. AntiPlag could be used to isolate plagiarized text based assignments from non-plagiarised assignments easily. Therefore, we present AntiPlag, a fast and effective tool for plagiarism detection on text based electronic assignments.
User Friendly Line CAPTCHAs
Feb 04, 2014
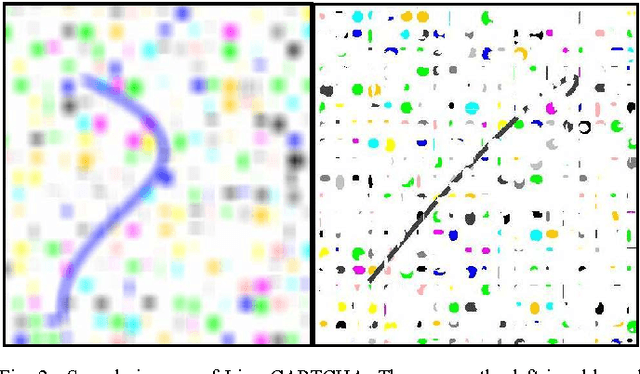


CAPTCHAs or reverse Turing tests are real-time assessments used by programs (or computers) to tell humans and machines apart. This is achieved by assigning and assessing hard AI problems that could only be solved easily by human but not by machines. Applications of such assessments range from stopping spammers from automatically filling online forms to preventing hackers from performing dictionary attack. Today, the race between makers and breakers of CAPTCHAs is at a juncture, where the CAPTCHAs proposed are not even answerable by humans. We consider such CAPTCHAs as non user friendly. In this paper, we propose a novel technique for reverse Turing test - we call it the Line CAPTCHAs - that mainly focuses on user friendliness while not compromising the security aspect that is expected to be provided by such a system.
* 6 pages