 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fingerprint Image Synthesis with GANs, Diffusion Models, and Style Transfer Techniques
Mar 20, 2024

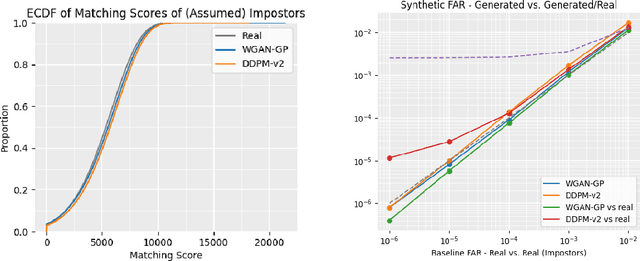
We present novel approaches involving generative adversarial networks and diffusion models in order to synthesize high quality, live and spoof fingerprint images while preserving features such as uniqueness and diversity. We generate live fingerprints from noise with a variety of methods, and we use image translation techniques to translate live fingerprint images to spoof. To generate different types of spoof images based on limited training data we incorporate style transfer techniques through a cycle autoencoder equipped with a Wasserstein metric along with Gradient Penalty (CycleWGAN-GP) in order to avoid mode collapse and instability. We find that when the spoof training data includes distinct spoof characteristics, it leads to improved live-to-spoof translation. We assess the diversity and realism of the generated live fingerprint images mainly through the Fr\'echet Inception Distance (FID) and the False Acceptance Rate (FAR). Our best diffusion model achieved a FID of 15.78. The comparable WGAN-GP model achieved slightly higher FID while performing better in the uniqueness assessment due to a slightly lower FAR when matched against the training data, indicating better creativity. Moreover, we give example images showing that a DDPM model clearly can generate realistic fingerprint images.
Content-Aware Speaker Embeddings for Speaker Diarisation
Feb 12, 2021
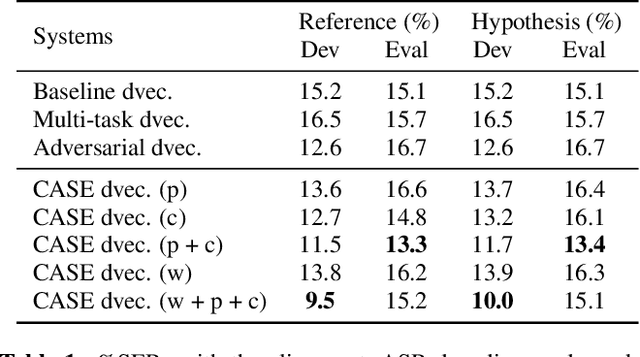

Recent speaker diarisation systems often convert variable length speech segments into fixed-length vector representations for speaker clustering, which are known as speaker embeddings. In this paper, the content-aware speaker embeddings (CASE) approach is proposed, which extends the input of the speaker classifier to include not only acoustic features but also their corresponding speech content, via phone, character, and word embeddings. Compared to alternative methods that leverage similar information, such as multitask or adversarial training, CASE factorises automatic speech recognition (ASR) from speaker recognition to focus on modelling speaker characteristics and correlations with the corresponding content units to derive more expressive representations. CASE is evaluated for speaker re-clustering with a realistic speaker diarisation setup using the AMI meeting transcription dataset, where the content information is obtained by performing ASR based on an automatic segmentation. Experimental results showed that CASE achieved a 17.8% relative speaker error rate reduction over conventional methods.
Local Differential Privacy for Deep Learning
Aug 08, 2019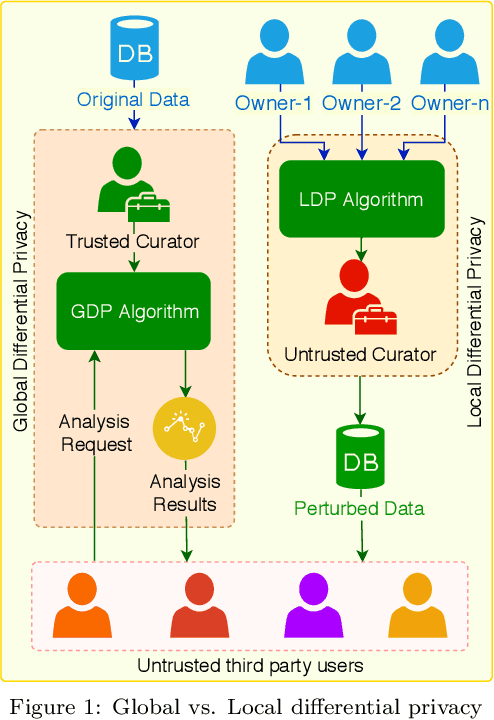

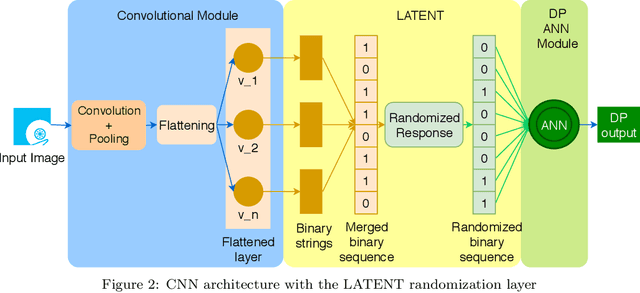
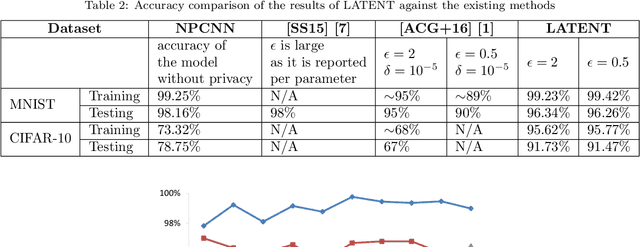
Deep learning (DL) is a promising area of machine learning which is becoming popular due to its remarkable accuracy when trained with a massive amount of data. Often, these datasets are highly sensitive crowd-sourced data such as medical data, financial data, or image data, and the DL models trained on these data tend to leak privacy. We propose a new local differentially private (LDP) algorithm (named LATENT) which redesigns the training process in a way that a data owner can add a randomization layer before data leave data owners' devices and reach to a potentially untrusted machine learning service. This way LATENT prevents privacy leaks of DL models, e.g., due to membership inference and memorizing model attacks, while providing excellent accuracy. By not requiring a trusted party, LATENT can be more practical for cloud-based machine learning services in comparison to existing differentially private approaches. Our experimental evaluation of LATENT on convolutional deep neural networks demonstrates excellent accuracy (e.g. 91\%- 96\%) with high model quality even under very low privacy budgets (e.g. $\epsilon=0.5$), outperforming existing differentially private approaches for deep learning.