 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of an Audio-Video Multimodal Deepfake Dataset using Unimodal and Multimodal Detectors
Sep 07, 2021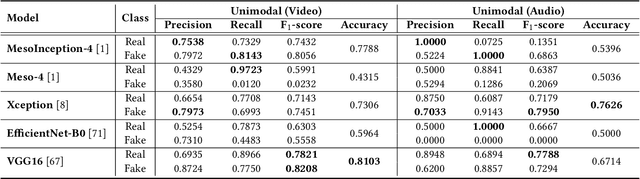
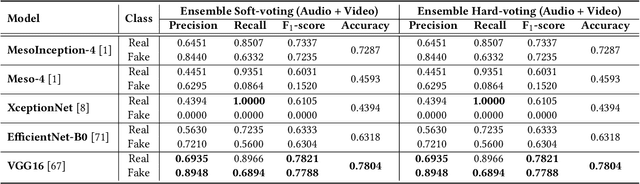
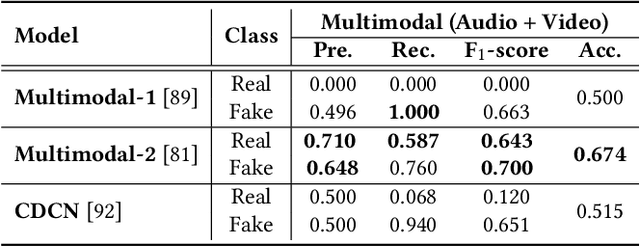
Significant advancements made in the generation of deepfakes have caused security and privacy issues. Attackers can easily impersonate a person's identity in an image by replacing his face with the target person's face. Moreover, a new domain of cloning human voices using deep-learning technologies is also emerging. Now, an attacker can generate realistic cloned voices of humans using only a few seconds of audio of the target person. With the emerging threat of potential harm deepfakes can cause, researchers have proposed deepfake detection methods. However, they only focus on detecting a single modality, i.e., either video or audio. On the other hand, to develop a good deepfake detector that can cope with the recent advancements in deepfake generation, we need to have a detector that can detect deepfakes of multiple modalities, i.e., videos and audios. To build such a detector, we need a dataset that contains video and respective audio deepfakes. We were able to find a most recent deepfake dataset, Audio-Video Multimodal Deepfake Detection Dataset (FakeAVCeleb), that contains not only deepfake videos but synthesized fake audios as well. We used this multimodal deepfake dataset and performed detailed baseline experiments using state-of-the-art unimodal, ensemble-based, and multimodal detection methods to evaluate it. We conclude through detailed experimentation that unimodals, addressing only a single modality, video or audio, do not perform well compared to ensemble-based methods. Whereas purely multimodal-based baselines provide the worst performance.
FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset
Sep 06, 2021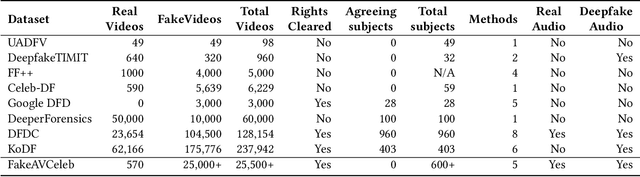
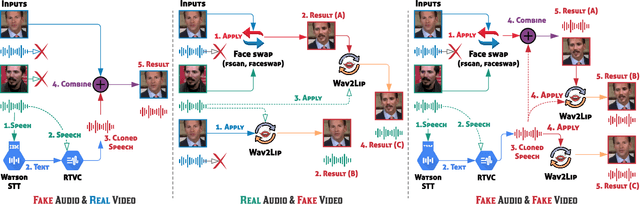
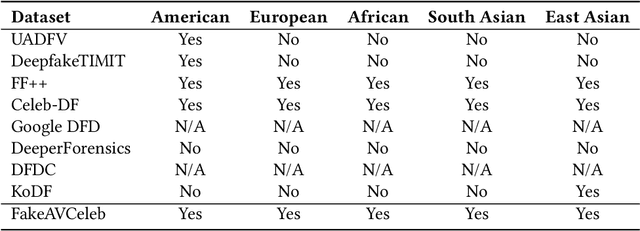

While significant advancements have been made in the generation of deepfakes using deep learning technologies, its misuse is a well-known issue now. Deepfakes can cause severe security and privacy issues as they can be used to impersonate a person's identity in a video by replacing his/her face with another person's face. Recently, a new problem of generating synthesized human voice of a person is emerging, where AI-based deep learning models can synthesize any person's voice requiring just a few seconds of audio. With the emerging threat of impersonation attacks using deepfake audios and videos, a new generation of deepfake detectors is needed to focus on both video and audio collectively. A large amount of good quality datasets is typically required to capture the real-world scenarios to develop a competent deepfake detector. Existing deepfake datasets either contain deepfake videos or audios, which are racially biased as well. Hence, there is a crucial need for creating a good video as well as an audio deepfake dataset, which can be used to detect audio and video deepfake simultaneously. To fill this gap, we propose a novel Audio-Video Deepfake dataset (FakeAVCeleb) that contains not only deepfake videos but also respective synthesized lip-synced fake audios. We generate this dataset using the current most popular deepfake generation methods. We selected real YouTube videos of celebrities with four racial backgrounds (Caucasian, Black, East Asian, and South Asian) to develop a more realistic multimodal dataset that addresses racial bias and further help develop multimodal deepfake detectors. We performed several experiments using state-of-the-art detection methods to evaluate our deepfake dataset and demonstrate the challenges and usefulness of our multimodal Audio-Video deepfake dataset.