 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation into Misuse of Java Security APIs by Large Language Models
Apr 04, 2024



The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.
Systematic Literature Review on Application of Machine Learning in Continuous Integration
May 22, 2023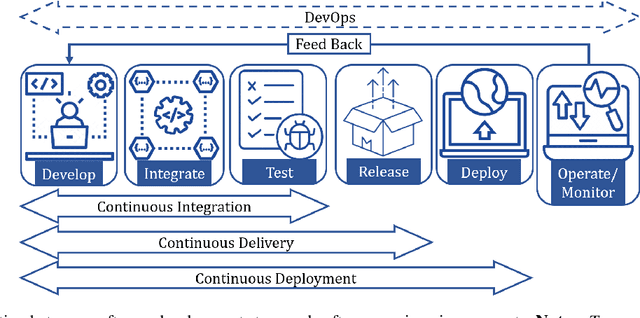
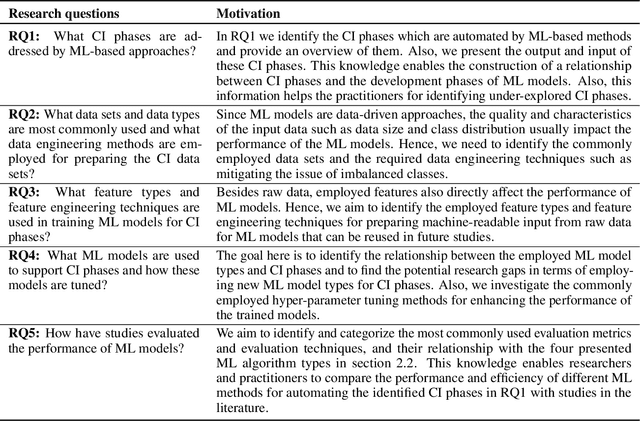
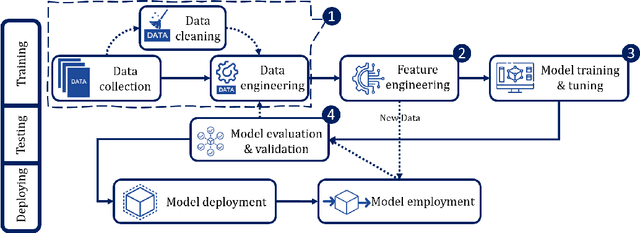

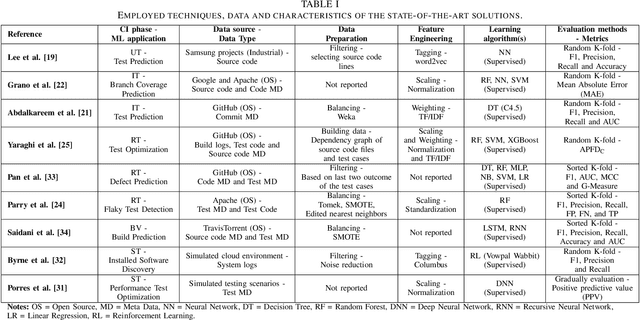
This research conducted a systematic review of the literature on machine learning (ML)-based methods in the context of Continuous Integration (CI) over the past 22 years. The study aimed to identify and describe the techniques used in ML-based solutions for CI and analyzed various aspects such as data engineering, feature engineering, hyper-parameter tuning, ML models, evaluation methods, and metrics. In this paper, we have depicted the phases of CI testing, the connection between them, and the employed techniques in training the ML method phases. We presented nine types of data sources and four taken steps in the selected studies for preparing the data. Also, we identified four feature types and nine subsets of data features through thematic analysis of the selected studies. Besides, five methods for selecting and tuning the hyper-parameters are shown. In addition, we summarised the evaluation methods used in the literature and identified fifteen different metrics. The most commonly used evaluation methods were found to be precision, recall, and F1-score, and we have also identified five methods for evaluating the performance of trained ML models. Finally, we have presented the relationship between ML model types, performance measurements, and CI phases. The study provides valuable insights for researchers and practitioners interested in ML-based methods in CI and emphasizes the need for further research in this area.
SoK: Machine Learning for Continuous Integration
Apr 06, 2023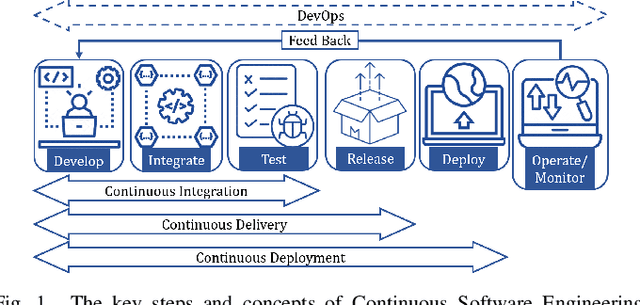
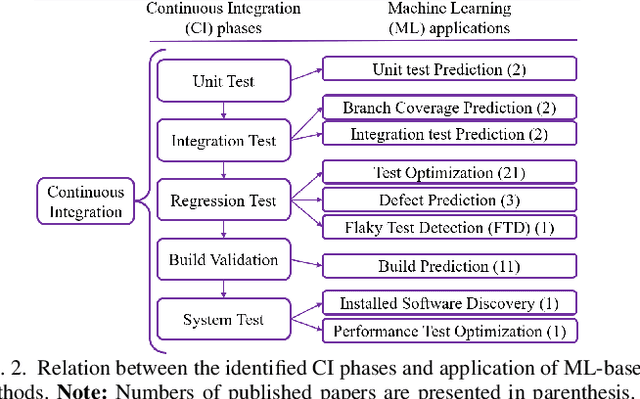
Continuous Integration (CI) has become a well-established software development practice for automatically and continuously integrating code changes during software development. An increasing number of Machine Learning (ML) based approaches for automation of CI phases are being reported in the literature. It is timely and relevant to provide a Systemization of Knowledge (SoK) of ML-based approaches for CI phases. This paper reports an SoK of different aspects of the use of ML for CI. Our systematic analysis also highlights the deficiencies of the existing ML-based solutions that can be improved for advancing the state-of-the-art.
LogGD:Detecting Anomalies from System Logs by Graph Neural Networks
Sep 16, 2022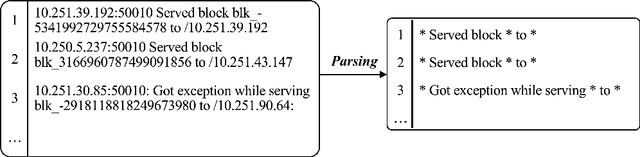
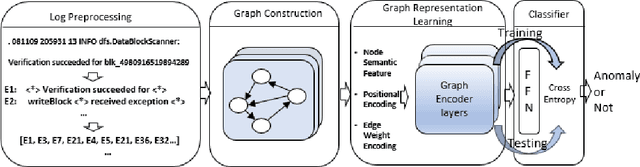
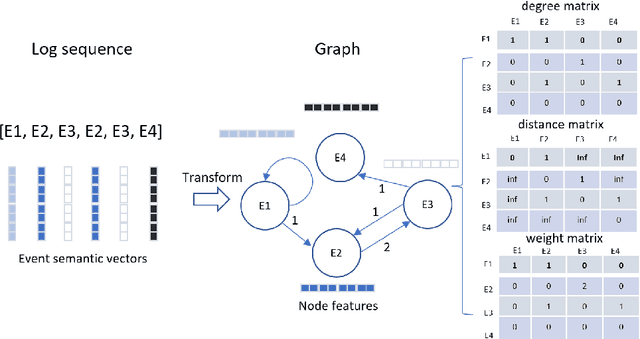
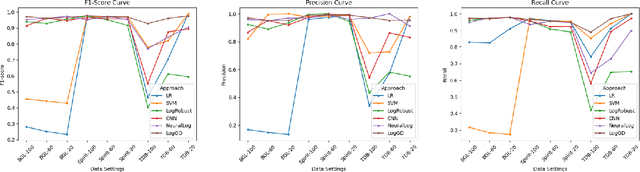
Log analysis is one of the main techniques engineers use to troubleshoot faults of large-scale software systems. During the past decades, many log analysis approaches have been proposed to detect system anomalies reflected by logs. They usually take log event counts or sequential log events as inputs and utilize machine learning algorithms including deep learning models to detect system anomalies. These anomalies are often identified as violations of quantitative relational patterns or sequential patterns of log events in log sequences. However, existing methods fail to leverage the spatial structural relationships among log events, resulting in potential false alarms and unstable performance. In this study, we propose a novel graph-based log anomaly detection method, LogGD, to effectively address the issue by transforming log sequences into graphs. We exploit the powerful capability of Graph Transformer Neural Network, which combines graph structure and node semantics for log-based anomaly detection. We evaluate the proposed method on four widely-used public log datasets. Experimental results show that LogGD can outperform state-of-the-art quantitative-based and sequence-based methods and achieve stable performance under different window size settings. The results confirm that LogGD is effective in log-based anomaly detection.