 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Fairness Concerns in AI-based Mobile App Reviews
Jan 16, 2024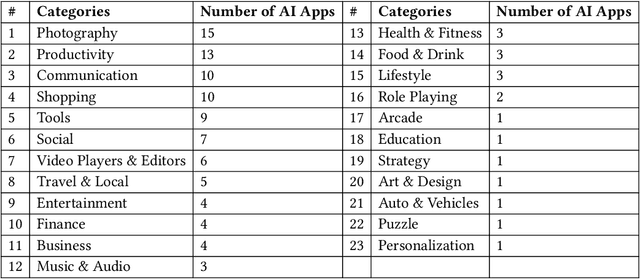
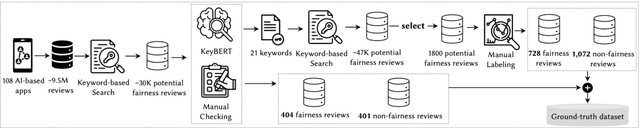

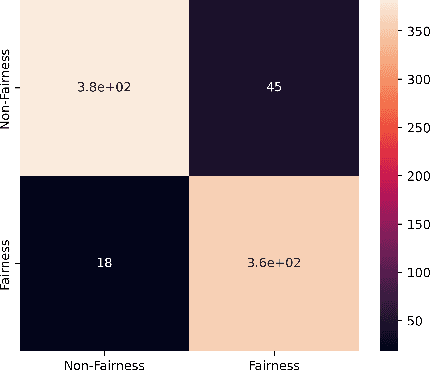
With the growing application of AI-based systems in our lives and society, there is a rising need to ensure that AI-based systems are developed and used in a responsible way. Fairness is one of the socio-technical concerns that must be addressed in AI-based systems for this purpose. Unfair AI-based systems, particularly, unfair AI-based mobile apps, can pose difficulties for a significant proportion of the global populace. This paper aims to deeply analyze fairness concerns in AI-based app reviews. We first manually constructed a ground-truth dataset including a statistical sample of fairness and non-fairness reviews. Leveraging the ground-truth dataset, we then developed and evaluated a set of machine learning and deep learning classifiers that distinguish fairness reviews from non-fairness reviews. Our experiments show that our best-performing classifier can detect fairness reviews with a precision of 94%. We then applied the best-performing classifier on approximately 9.5M reviews collected from 108 AI-based apps and identified around 92K fairness reviews. While the fairness reviews appear in 23 app categories, we found that the 'communication' and 'social' app categories have the highest percentage of fairness reviews. Next, applying the K-means clustering technique to the 92K fairness reviews, followed by manual analysis, led to the identification of six distinct types of fairness concerns (e.g., 'receiving different quality of features and services in different platforms and devices' and 'lack of transparency and fairness in dealing with user-generated content'). Finally, the manual analysis of 2,248 app owners' responses to the fairness reviews identified six root causes (e.g., 'copyright issues', 'external factors', 'development cost') that app owners report to justify fairness concerns.
Systematic Literature Review on Application of Machine Learning in Continuous Integration
May 22, 2023This research conducted a systematic review of the literature on machine learning (ML)-based methods in the context of Continuous Integration (CI) over the past 22 years. The study aimed to identify and describe the techniques used in ML-based solutions for CI and analyzed various aspects such as data engineering, feature engineering, hyper-parameter tuning, ML models, evaluation methods, and metrics. In this paper, we have depicted the phases of CI testing, the connection between them, and the employed techniques in training the ML method phases. We presented nine types of data sources and four taken steps in the selected studies for preparing the data. Also, we identified four feature types and nine subsets of data features through thematic analysis of the selected studies. Besides, five methods for selecting and tuning the hyper-parameters are shown. In addition, we summarised the evaluation methods used in the literature and identified fifteen different metrics. The most commonly used evaluation methods were found to be precision, recall, and F1-score, and we have also identified five methods for evaluating the performance of trained ML models. Finally, we have presented the relationship between ML model types, performance measurements, and CI phases. The study provides valuable insights for researchers and practitioners interested in ML-based methods in CI and emphasizes the need for further research in this area.
SoK: Machine Learning for Continuous Integration
Apr 06, 2023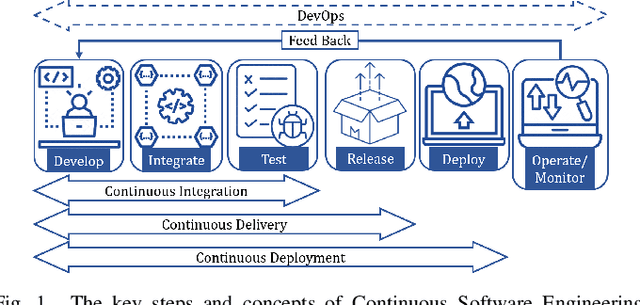
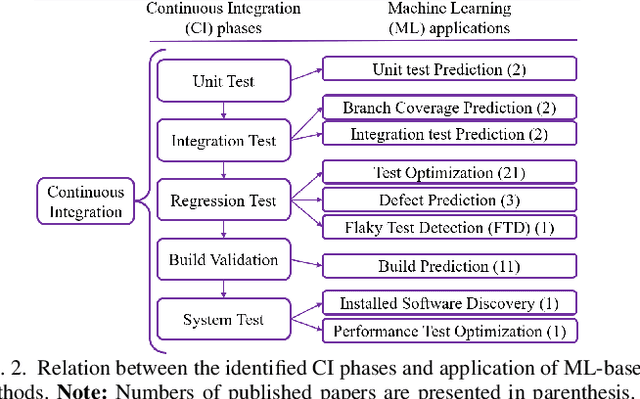
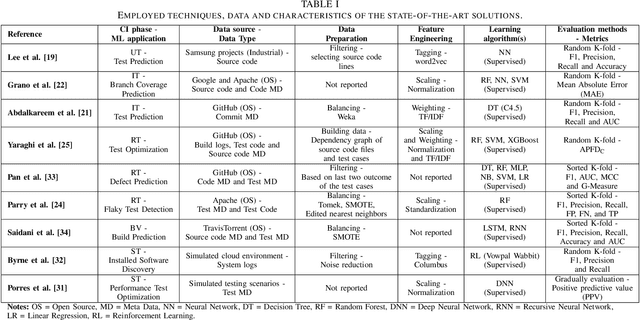
Continuous Integration (CI) has become a well-established software development practice for automatically and continuously integrating code changes during software development. An increasing number of Machine Learning (ML) based approaches for automation of CI phases are being reported in the literature. It is timely and relevant to provide a Systemization of Knowledge (SoK) of ML-based approaches for CI phases. This paper reports an SoK of different aspects of the use of ML for CI. Our systematic analysis also highlights the deficiencies of the existing ML-based solutions that can be improved for advancing the state-of-the-art.