 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORACAL: A Robust and Explainable Multimodal Framework for Smart Contract Vulnerability Detection with Causal Graph Enrichment
Mar 30, 2026Although Graph Neural Networks (GNNs) have shown promise for smart contract vulnerability detection, they still face significant limitations. Homogeneous graph models fail to capture the interplay between control flow and data dependencies, while heterogeneous graph approaches often lack deep semantic understanding, leaving them susceptible to adversarial attacks. Moreover, most black-box models fail to provide explainable evidence, hindering trust in professional audits. To address these challenges, we propose ORACAL (Observable RAG-enhanced Analysis with CausAL reasoning), a heterogeneous multimodal graph learning framework that integrates Control Flow Graph (CFG), Data Flow Graph (DFG), and Call Graph (CG). ORACAL selectively enriches critical subgraphs with expert-level security context from Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs), and employs a causal attention mechanism to disentangle true vulnerability indicators from spurious correlations. For transparency, the framework adopts PGExplainer to generate subgraph-level explanations identifying vulnerability triggering paths. Experiments on large-scale datasets demonstrate that ORACAL achieves state-of-the-art performance, outperforming MANDO-HGT, MTVHunter, GNN-SC, and SCVHunter by up to 39.6 percentage points, with a peak Macro F1 of 91.28% on the primary benchmark. ORACAL maintains strong generalization on out-of-distribution datasets with 91.8% on CGT Weakness and 77.1% on DAppScan. In explainability evaluation, PGExplainer achieves 32.51% Mean Intersection over Union (MIoU) against manually annotated vulnerability triggering paths. Under adversarial attacks, ORACAL limits performance degradation to approximately 2.35% F1 decrease with an Attack Success Rate (ASR) of only 3%, surpassing SCVHunter and MANDO-HGT which exhibit ASRs ranging from 10.91% to 18.73%.
Securing the AI Supply Chain: What Can We Learn From Developer-Reported Security Issues and Solutions of AI Projects?
Dec 29, 2025The rapid growth of Artificial Intelligence (AI) models and applications has led to an increasingly complex security landscape. Developers of AI projects must contend not only with traditional software supply chain issues but also with novel, AI-specific security threats. However, little is known about what security issues are commonly encountered and how they are resolved in practice. This gap hinders the development of effective security measures for each component of the AI supply chain. We bridge this gap by conducting an empirical investigation of developer-reported issues and solutions, based on discussions from Hugging Face and GitHub. To identify security-related discussions, we develop a pipeline that combines keyword matching with an optimal fine-tuned distilBERT classifier, which achieved the best performance in our extensive comparison of various deep learning and large language models. This pipeline produces a dataset of 312,868 security discussions, providing insights into the security reporting practices of AI applications and projects. We conduct a thematic analysis of 753 posts sampled from our dataset and uncover a fine-grained taxonomy of 32 security issues and 24 solutions across four themes: (1) System and Software, (2) External Tools and Ecosystem, (3) Model, and (4) Data. We reveal that many security issues arise from the complex dependencies and black-box nature of AI components. Notably, challenges related to Models and Data often lack concrete solutions. Our insights can offer evidence-based guidance for developers and researchers to address real-world security threats across the AI supply chain.
Software Vulnerability Management in the Era of Artificial Intelligence: An Industry Perspective
Dec 23, 2025Artificial Intelligence (AI) has revolutionized software development, particularly by automating repetitive tasks and improving developer productivity. While these advancements are well-documented, the use of AI-powered tools for Software Vulnerability Management (SVM), such as vulnerability detection and repair, remains underexplored in industry settings. To bridge this gap, our study aims to determine the extent of the adoption of AI-powered tools for SVM, identify barriers and facilitators to the use, and gather insights to help improve the tools to meet industry needs better. We conducted a survey study involving 60 practitioners from diverse industry sectors across 27 countries. The survey incorporates both quantitative and qualitative questions to analyze the adoption trends, assess tool strengths, identify practical challenges, and uncover opportunities for improvement. Our findings indicate that AI-powered tools are used throughout the SVM life cycle, with 69% of users reporting satisfaction with their current use. Practitioners value these tools for their speed, coverage, and accessibility. However, concerns about false positives, missing context, and trust issues remain prevalent. We observe a socio-technical adoption pattern in which AI outputs are filtered through human oversight and organizational governance. To support safe and effective use of AI for SVM, we recommend improvements in explainability, contextual awareness, integration workflows, and validation practices. We assert that these findings can offer practical guidance for practitioners, tool developers, and researchers seeking to enhance secure software development through the use of AI.
LLMSecConfig: An LLM-Based Approach for Fixing Software Container Misconfigurations
Feb 04, 2025



Security misconfigurations in Container Orchestrators (COs) can pose serious threats to software systems. While Static Analysis Tools (SATs) can effectively detect these security vulnerabilities, the industry currently lacks automated solutions capable of fixing these misconfigurations. The emergence of Large Language Models (LLMs), with their proven capabilities in code understanding and generation, presents an opportunity to address this limitation. This study introduces LLMSecConfig, an innovative framework that bridges this gap by combining SATs with LLMs. Our approach leverages advanced prompting techniques and Retrieval-Augmented Generation (RAG) to automatically repair security misconfigurations while preserving operational functionality. Evaluation of 1,000 real-world Kubernetes configurations achieved a 94\% success rate while maintaining a low rate of introducing new misconfigurations. Our work makes a promising step towards automated container security management, reducing the manual effort required for configuration maintenance.
Automated Code-centric Software Vulnerability Assessment: How Far Are We? An Empirical Study in C/C++
Aug 03, 2024



Background: The C and C++ languages hold significant importance in Software Engineering research because of their widespread use in practice. Numerous studies have utilized Machine Learning (ML) and Deep Learning (DL) techniques to detect software vulnerabilities (SVs) in the source code written in these languages. However, the application of these techniques in function-level SV assessment has been largely unexplored. SV assessment is increasingly crucial as it provides detailed information on the exploitability, impacts, and severity of security defects, thereby aiding in their prioritization and remediation. Aims: We conduct the first empirical study to investigate and compare the performance of ML and DL models, many of which have been used for SV detection, for function-level SV assessment in C/C++. Method: Using 9,993 vulnerable C/C++ functions, we evaluated the performance of six multi-class ML models and five multi-class DL models for the SV assessment at the function level based on the Common Vulnerability Scoring System (CVSS). We further explore multi-task learning, which can leverage common vulnerable code to predict all SV assessment outputs simultaneously in a single model, and compare the effectiveness and efficiency of this model type with those of the original multi-class models. Results: We show that ML has matching or even better performance compared to the multi-class DL models for function-level SV assessment with significantly less training time. Employing multi-task learning allows the DL models to perform significantly better, with an average of 8-22% increase in Matthews Correlation Coefficient (MCC). Conclusions: We distill the practices of using data-driven techniques for function-level SV assessment in C/C++, including the use of multi-task DL to balance efficiency and effectiveness. This can establish a strong foundation for future work in this area.
Systematic Literature Review on Application of Machine Learning in Continuous Integration
May 22, 2023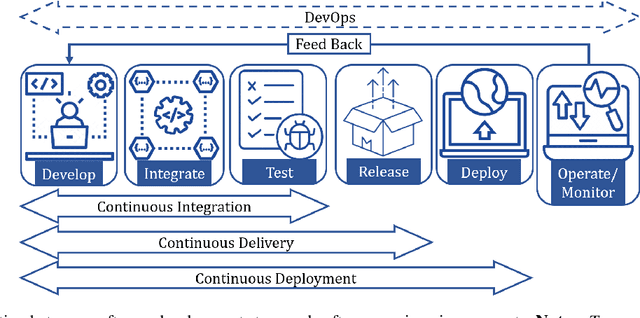
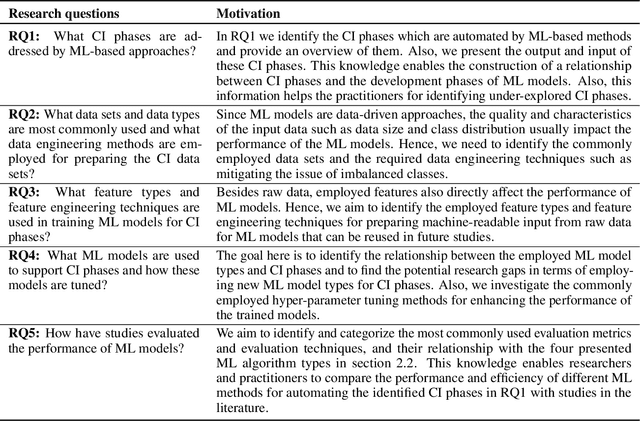
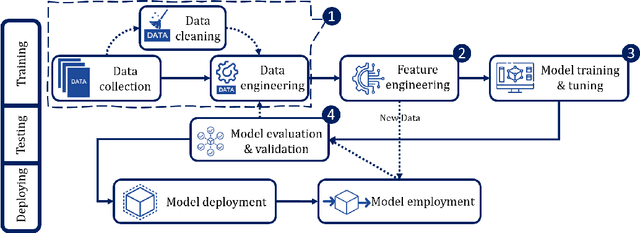

This research conducted a systematic review of the literature on machine learning (ML)-based methods in the context of Continuous Integration (CI) over the past 22 years. The study aimed to identify and describe the techniques used in ML-based solutions for CI and analyzed various aspects such as data engineering, feature engineering, hyper-parameter tuning, ML models, evaluation methods, and metrics. In this paper, we have depicted the phases of CI testing, the connection between them, and the employed techniques in training the ML method phases. We presented nine types of data sources and four taken steps in the selected studies for preparing the data. Also, we identified four feature types and nine subsets of data features through thematic analysis of the selected studies. Besides, five methods for selecting and tuning the hyper-parameters are shown. In addition, we summarised the evaluation methods used in the literature and identified fifteen different metrics. The most commonly used evaluation methods were found to be precision, recall, and F1-score, and we have also identified five methods for evaluating the performance of trained ML models. Finally, we have presented the relationship between ML model types, performance measurements, and CI phases. The study provides valuable insights for researchers and practitioners interested in ML-based methods in CI and emphasizes the need for further research in this area.
SoK: Machine Learning for Continuous Integration
Apr 06, 2023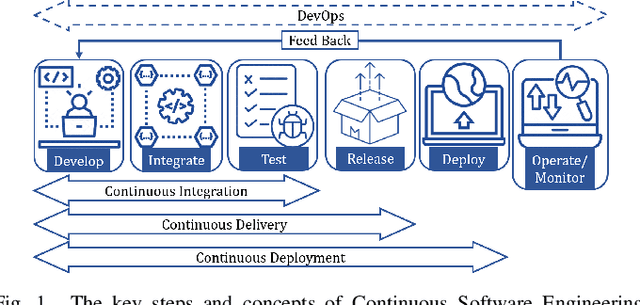
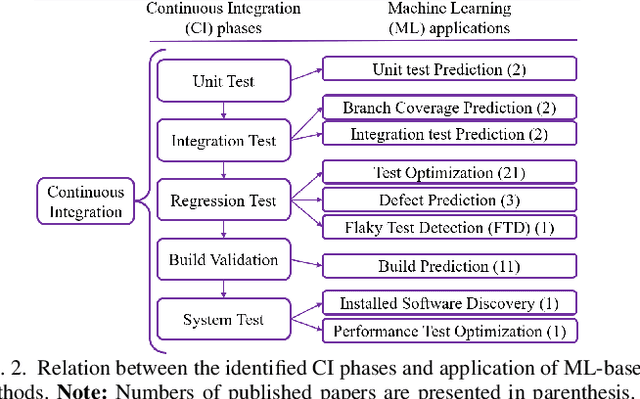
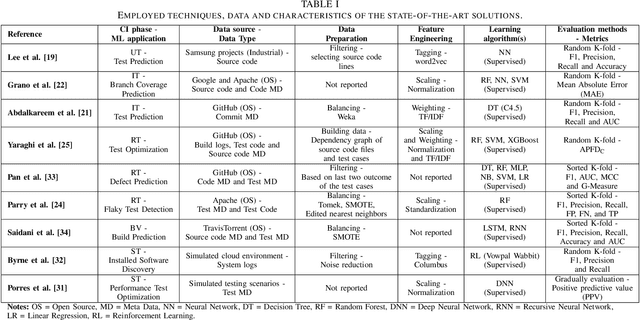
Continuous Integration (CI) has become a well-established software development practice for automatically and continuously integrating code changes during software development. An increasing number of Machine Learning (ML) based approaches for automation of CI phases are being reported in the literature. It is timely and relevant to provide a Systemization of Knowledge (SoK) of ML-based approaches for CI phases. This paper reports an SoK of different aspects of the use of ML for CI. Our systematic analysis also highlights the deficiencies of the existing ML-based solutions that can be improved for advancing the state-of-the-art.