 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation into Misuse of Java Security APIs by Large Language Models
Apr 04, 2024



The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.
Objective Prediction of Tomorrow's Affect Using Multi-Modal Physiological Data and Personal Chronicles: A Study of Monitoring College Student Well-being in 2020
Jan 26, 2022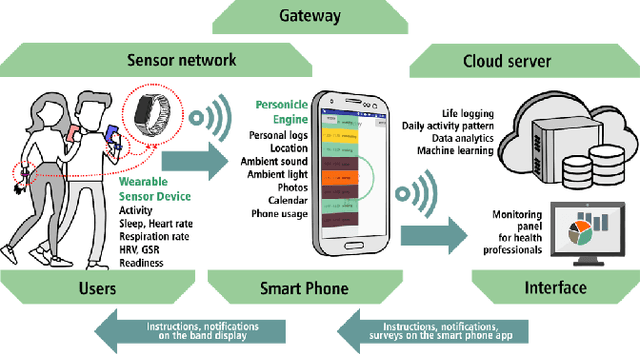
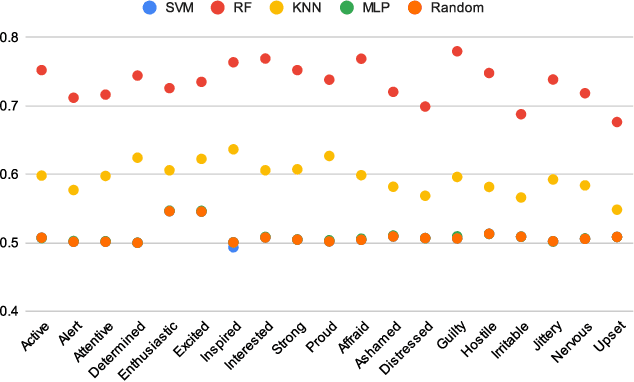
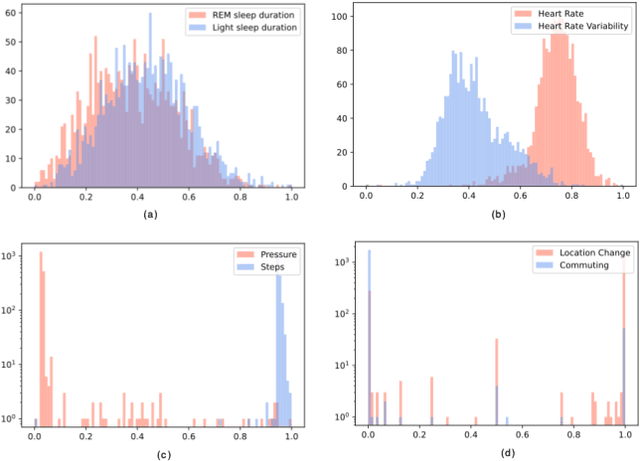
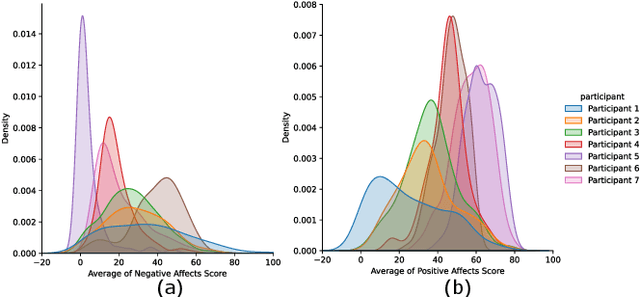
Monitoring and understanding affective states are important aspects of healthy functioning and treatment of mood-based disorders. Recent advancements of ubiquitous wearable technologies have increased the reliability of such tools in detecting and accurately estimating mental states (e.g., mood, stress, etc.), offering comprehensive and continuous monitoring of individuals over time. Previous attempts to model an individual's mental state were limited to subjective approaches or the inclusion of only a few modalities (i.e., phone, watch). Thus, the goal of our study was to investigate the capacity to more accurately predict affect through a fully automatic and objective approach using multiple commercial devices. Longitudinal physiological data and daily assessments of emotions were collected from a sample of college students using smart wearables and phones for over a year. Results showed that our model was able to predict next-day affect with accuracy comparable to state of the art methods.
Persian Wordnet Construction using Supervised Learning
Apr 11, 2017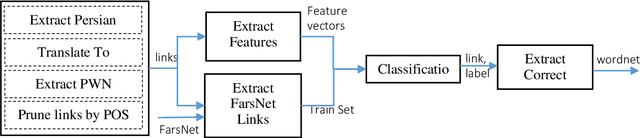
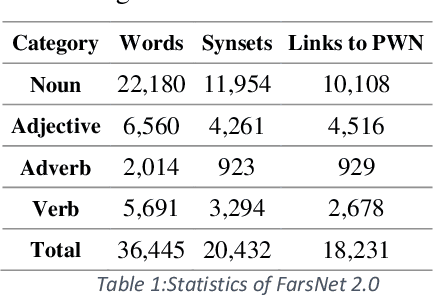
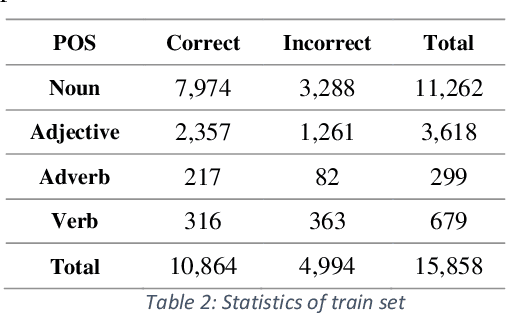
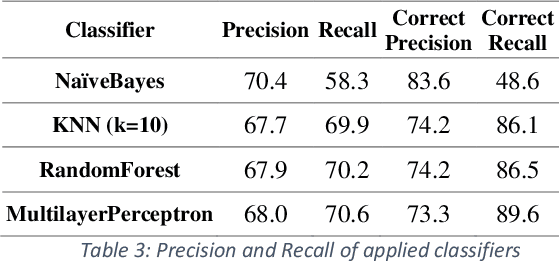
This paper presents an automated supervised method for Persian wordnet construction. Using a Persian corpus and a bi-lingual dictionary, the initial links between Persian words and Princeton WordNet synsets have been generated. These links will be discriminated later as correct or incorrect by employing seven features in a trained classification system. The whole method is just a classification system, which has been trained on a train set containing FarsNet as a set of correct instances. State of the art results on the automatically derived Persian wordnet is achieved. The resulted wordnet with a precision of 91.18% includes more than 16,000 words and 22,000 synsets.