 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-View Consistency Framework with Semi-Supervised Domain Adaptation
Jan 27, 2026Semi-Supervised Domain Adaptation (SSDA) leverages knowledge from a fully labeled source domain to classify data in a partially labeled target domain. Due to the limited number of labeled samples in the target domain, there can be intrinsic similarity of classes in the feature space, which may result in biased predictions, even when the model is trained on a balanced dataset. To overcome this limitation, we introduce a multi-view consistency framework, which includes two views for training strongly augmented data. One is a debiasing strategy for correcting class-wise prediction probabilities according to the prediction performance of the model. The other involves leveraging pseudo-negative labels derived from the model predictions. Furthermore, we introduce a cross-domain affinity learning aimed at aligning features of the same class across different domains, thereby enhancing overall performance. Experimental results demonstrate that our method outperforms the competing methods on two standard domain adaptation datasets, DomainNet and Office-Home. Combining unsupervised domain adaptation and semi-supervised learning offers indispensable contributions to the industrial sector by enhancing model adaptability, reducing annotation costs, and improving performance.
Semi-Supervised Learning with Pseudo-Negative Labels for Image Classification
Jan 10, 2023
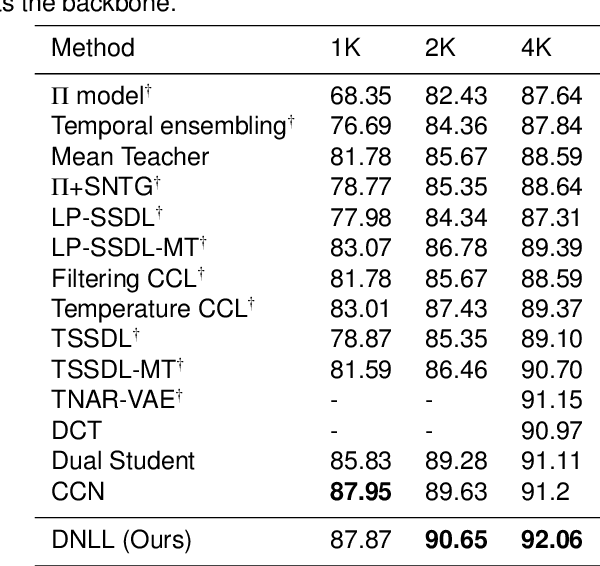
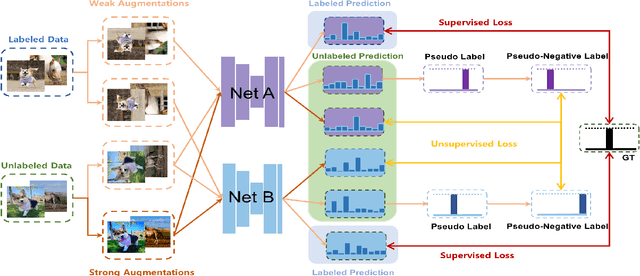
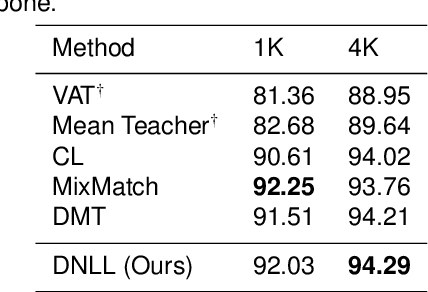
Semi-supervised learning frameworks usually adopt mutual learning approaches with multiple submodels to learn from different perspectives. To avoid transferring erroneous pseudo labels between these submodels, a high threshold is usually used to filter out a large number of low-confidence predictions for unlabeled data. However, such filtering can not fully exploit unlabeled data with low prediction confidence. To overcome this problem, in this work, we propose a mutual learning framework based on pseudo-negative labels. Negative labels are those that a corresponding data item does not belong. In each iteration, one submodel generates pseudo-negative labels for each data item, and the other submodel learns from these labels. The role of the two submodels exchanges after each iteration until convergence. By reducing the prediction probability on pseudo-negative labels, the dual model can improve its prediction ability. We also propose a mechanism to select a few pseudo-negative labels to feed into submodels. In the experiments, our framework achieves state-of-the-art results on several main benchmarks. Specifically, with our framework, the error rates of the 13-layer CNN model are 9.35% and 7.94% for CIFAR-10 with 1000 and 4000 labels, respectively. In addition, for the non-augmented MNIST with only 20 labels, the error rate is 0.81% by our framework, which is much smaller than that of other approaches. Our approach also demonstrates a significant performance improvement in domain adaptation.