 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
Real-Time Multi-Scene Visibility Enhancement for Promoting Navigational Safety of Vessels Under Complex Weather Conditions
Sep 02, 2024



The visible-light camera, which is capable of environment perception and navigation assistance, has emerged as an essential imaging sensor for marine surface vessels in intelligent waterborne transportation systems (IWTS). However, the visual imaging quality inevitably suffers from several kinds of degradations (e.g., limited visibility, low contrast, color distortion, etc.) under complex weather conditions (e.g., haze, rain, and low-lightness). The degraded visual information will accordingly result in inaccurate environment perception and delayed operations for navigational risk. To promote the navigational safety of vessels, many computational methods have been presented to perform visual quality enhancement under poor weather conditions. However, most of these methods are essentially specific-purpose implementation strategies, only available for one specific weather type. To overcome this limitation, we propose to develop a general-purpose multi-scene visibility enhancement method, i.e., edge reparameterization- and attention-guided neural network (ERANet), to adaptively restore the degraded images captured under different weather conditions. In particular, our ERANet simultaneously exploits the channel attention, spatial attention, and reparameterization technology to enhance the visual quality while maintaining low computational cost. Extensive experiments conducted on standard and IWTS-related datasets have demonstrated that our ERANet could outperform several representative visibility enhancement methods in terms of both imaging quality and computational efficiency. The superior performance of IWTS-related object detection and scene segmentation could also be steadily obtained after ERANet-based visibility enhancement under complex weather conditions.
* 15 pages, 13 figures
Multi-Task Learning-Enabled Automatic Vessel Draft Reading for Intelligent Maritime Surveillance
Oct 11, 2023



The accurate and efficient vessel draft reading (VDR) is an important component of intelligent maritime surveillance, which could be exploited to assist in judging whether the vessel is normally loaded or overloaded. The computer vision technique with an excellent price-to-performance ratio has become a popular medium to estimate vessel draft depth. However, the traditional estimation methods easily suffer from several limitations, such as sensitivity to low-quality images, high computational cost, etc. In this work, we propose a multi-task learning-enabled computational method (termed MTL-VDR) for generating highly reliable VDR. In particular, our MTL-VDR mainly consists of four components, i.e., draft mark detection, draft scale recognition, vessel/water segmentation, and final draft depth estimation. We first construct a benchmark dataset related to draft mark detection and employ a powerful and efficient convolutional neural network to accurately perform the detection task. The multi-task learning method is then proposed for simultaneous draft scale recognition and vessel/water segmentation. To obtain more robust VDR under complex conditions (e.g., damaged and stained scales, etc.), the accurate draft scales are generated by an automatic correction method, which is presented based on the spatial distribution rules of draft scales. Finally, an adaptive computational method is exploited to yield an accurate and robust draft depth. Extensive experiments have been implemented on the realistic dataset to compare our MTL-VDR with state-of-the-art methods. The results have demonstrated its superior performance in terms of accuracy, robustness, and efficiency. The computational speed exceeds 40 FPS, which satisfies the requirements of real-time maritime surveillance to guarantee vessel traffic safety.
Double Domain Guided Real-Time Low-Light Image Enhancement for Ultra-High-Definition Transportation Surveillance
Sep 15, 2023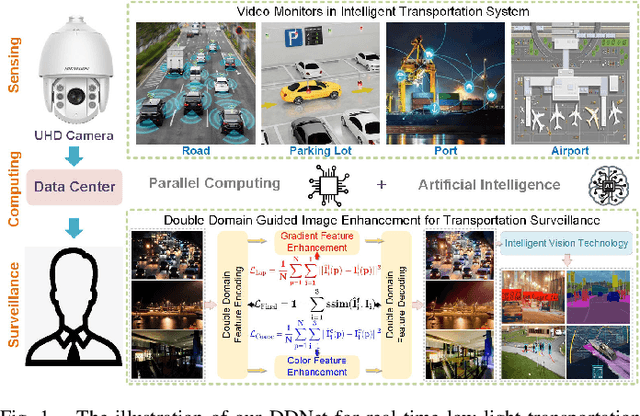
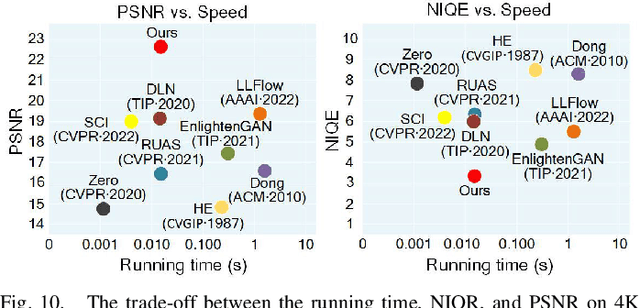


Real-time transportation surveillance is an essential part of the intelligent transportation system (ITS). However, images captured under low-light conditions often suffer the poor visibility with types of degradation, such as noise interference and vague edge features, etc. With the development of imaging devices, the quality of the visual surveillance data is continually increasing, like 2K and 4K, which has more strict requirements on the efficiency of image processing. To satisfy the requirements on both enhancement quality and computational speed, this paper proposes a double domain guided real-time low-light image enhancement network (DDNet) for ultra-high-definition (UHD) transportation surveillance. Specifically, we design an encoder-decoder structure as the main architecture of the learning network. In particular, the enhancement processing is divided into two subtasks (i.e., color enhancement and gradient enhancement) via the proposed coarse enhancement module (CEM) and LoG-based gradient enhancement module (GEM), which are embedded in the encoder-decoder structure. It enables the network to enhance the color and edge features simultaneously. Through the decomposition and reconstruction on both color and gradient domains, our DDNet can restore the detailed feature information concealed by the darkness with better visual quality and efficiency. The evaluation experiments on standard and transportation-related datasets demonstrate that our DDNet provides superior enhancement quality and efficiency compared with the state-of-the-art methods. Besides, the object detection and scene segmentation experiments indicate the practical benefits for higher-level image analysis under low-light environments in ITS.
Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives
Mar 29, 2023



Thanks to the augmented convenience, safety advantages, and potential commercial value, Intelligent vehicles (IVs) have attracted wide attention throughout the world. Although a few autonomous driving unicorns assert that IVs will be commercially deployable by 2025, their implementation is still restricted to small-scale validation due to various issues, among which precise computation of control commands or trajectories by planning methods remains a prerequisite for IVs. This paper aims to review state-of-the-art planning methods, including pipeline planning and end-to-end planning methods. In terms of pipeline methods, a survey of selecting algorithms is provided along with a discussion of the expansion and optimization mechanisms, whereas in end-to-end methods, the training approaches and verification scenarios of driving tasks are points of concern. Experimental platforms are reviewed to facilitate readers in selecting suitable training and validation methods. Finally, the current challenges and future directions are discussed. The side-by-side comparison presented in this survey not only helps to gain insights into the strengths and limitations of the reviewed methods but also assists with system-level design choices.
Asynchronous Trajectory Matching-Based Multimodal Maritime Data Fusion for Vessel Traffic Surveillance in Inland Waterways
Feb 22, 2023



The automatic identification system (AIS) and video cameras have been widely exploited for vessel traffic surveillance in inland waterways. The AIS data could provide the vessel identity and dynamic information on vessel position and movements. In contrast, the video data could describe the visual appearances of moving vessels, but without knowing the information on identity, position and movements, etc. To further improve vessel traffic surveillance, it becomes necessary to fuse the AIS and video data to simultaneously capture the visual features, identity and dynamic information for the vessels of interest. However, traditional data fusion methods easily suffer from several potential limitations, e.g., asynchronous messages, missing data, random outliers, etc. In this work, we first extract the AIS- and video-based vessel trajectories, and then propose a deep learning-enabled asynchronous trajectory matching method (named DeepSORVF) to fuse the AIS-based vessel information with the corresponding visual targets. In addition, by combining the AIS- and video-based movement features, we also present a prior knowledge-driven anti-occlusion method to yield accurate and robust vessel tracking results under occlusion conditions. To validate the efficacy of our DeepSORVF, we have also constructed a new benchmark dataset (termed FVessel) for vessel detection, tracking, and data fusion. It consists of many videos and the corresponding AIS data collected in various weather conditions and locations. The experimental results have demonstrated that our method is capable of guaranteeing high-reliable data fusion and anti-occlusion vessel tracking.
Conservative-Progressive Collaborative Learning for Semi-supervised Semantic Segmentation
Nov 30, 2022Pseudo supervision is regarded as the core idea in semi-supervised learning for semantic segmentation, and there is always a tradeoff between utilizing only the high-quality pseudo labels and leveraging all the pseudo labels. Addressing that, we propose a novel learning approach, called Conservative-Progressive Collaborative Learning (CPCL), among which two predictive networks are trained in parallel, and the pseudo supervision is implemented based on both the agreement and disagreement of the two predictions. One network seeks common ground via intersection supervision and is supervised by the high-quality labels to ensure a more reliable supervision, while the other network reserves differences via union supervision and is supervised by all the pseudo labels to keep exploring with curiosity. Thus, the collaboration of conservative evolution and progressive exploration can be achieved. To reduce the influences of the suspicious pseudo labels, the loss is dynamic re-weighted according to the prediction confidence. Extensive experiments demonstrate that CPCL achieves state-of-the-art performance for semi-supervised semantic segmentation.