 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
May 29, 2025
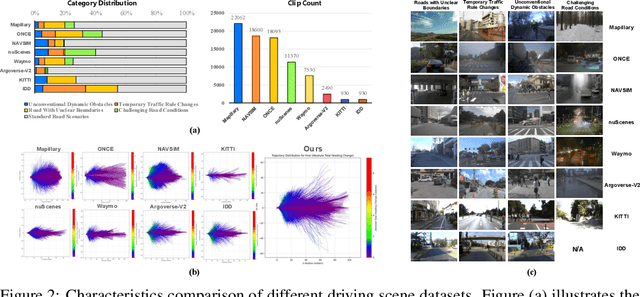
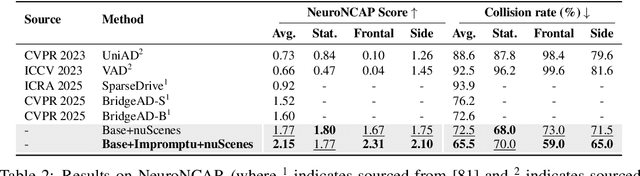

Vision-Language-Action (VLA) models for autonomous driving show promise but falter in unstructured corner case scenarios, largely due to a scarcity of targeted benchmarks. To address this, we introduce Impromptu VLA. Our core contribution is the Impromptu VLA Dataset: over 80,000 meticulously curated video clips, distilled from over 2M source clips sourced from 8 open-source large-scale datasets. This dataset is built upon our novel taxonomy of four challenging unstructured categories and features rich, planning-oriented question-answering annotations and action trajectories. Crucially, experiments demonstrate that VLAs trained with our dataset achieve substantial performance gains on established benchmarks--improving closed-loop NeuroNCAP scores and collision rates, and reaching near state-of-the-art L2 accuracy in open-loop nuScenes trajectory prediction. Furthermore, our Q&A suite serves as an effective diagnostic, revealing clear VLM improvements in perception, prediction, and planning. Our code, data and models are available at https://github.com/ahydchh/Impromptu-VLA.
Graph Learning-Driven Multi-Vessel Association: Fusing Multimodal Data for Maritime Intelligence
Apr 12, 2025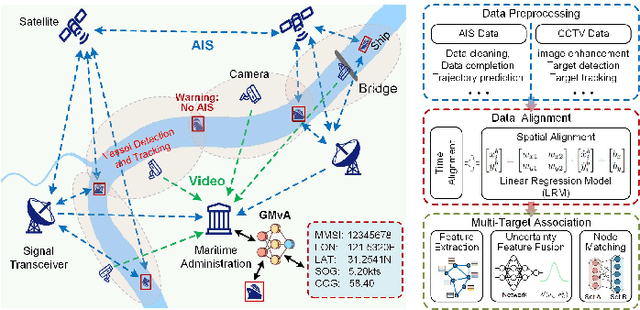
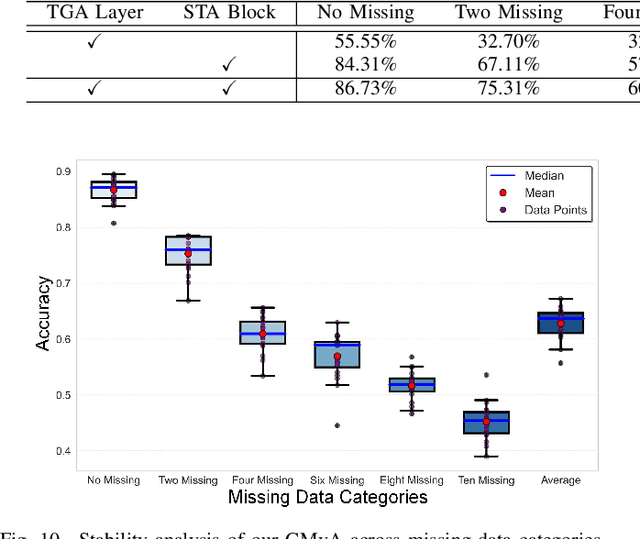
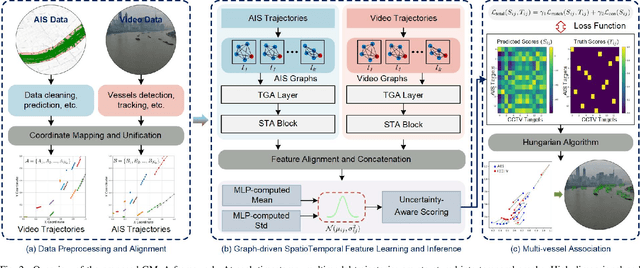
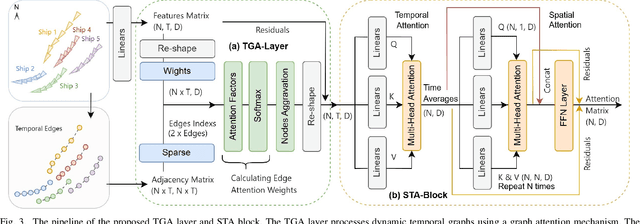
Ensuring maritime safety and optimizing traffic management in increasingly crowded and complex waterways require effective waterway monitoring. However, current methods struggle with challenges arising from multimodal data, such as dimensional disparities, mismatched target counts, vessel scale variations, occlusions, and asynchronous data streams from systems like the automatic identification system (AIS) and closed-circuit television (CCTV). Traditional multi-target association methods often struggle with these complexities, particularly in densely trafficked waterways. To overcome these issues, we propose a graph learning-driven multi-vessel association (GMvA) method tailored for maritime multimodal data fusion. By integrating AIS and CCTV data, GMvA leverages time series learning and graph neural networks to capture the spatiotemporal features of vessel trajectories effectively. To enhance feature representation, the proposed method incorporates temporal graph attention and spatiotemporal attention, effectively capturing both local and global vessel interactions. Furthermore, a multi-layer perceptron-based uncertainty fusion module computes robust similarity scores, and the Hungarian algorithm is adopted to ensure globally consistent and accurate target matching. Extensive experiments on real-world maritime datasets confirm that GMvA delivers superior accuracy and robustness in multi-target association, outperforming existing methods even in challenging scenarios with high vessel density and incomplete or unevenly distributed AIS and CCTV data.