 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Augmented Coreset Expansion for Scalable Dataset Distillation
Dec 05, 2024



With the rapid scaling of neural networks, data storage and communication demands have intensified. Dataset distillation has emerged as a promising solution, condensing information from extensive datasets into a compact set of synthetic samples by solving a bilevel optimization problem. However, current methods face challenges in computational efficiency, particularly with high-resolution data and complex architectures. Recently, knowledge-distillation-based dataset condensation approaches have made this process more computationally feasible. Yet, with the recent developments of generative foundation models, there is now an opportunity to achieve even greater compression, enhance the quality of distilled data, and introduce valuable diversity into the data representation. In this work, we propose a two-stage solution. First, we compress the dataset by selecting only the most informative patches to form a coreset. Next, we leverage a generative foundation model to dynamically expand this compressed set in real-time, enhancing the resolution of these patches and introducing controlled variability to the coreset. Our extensive experiments demonstrate the robustness and efficiency of our approach across a range of dataset distillation benchmarks. We demonstrate a significant improvement of over 10% compared to the state-of-the-art on several large-scale dataset distillation benchmarks. The code will be released soon.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
Learning How To Ask: Cycle-Consistency Refines Prompts in Multimodal Foundation Models
Feb 13, 2024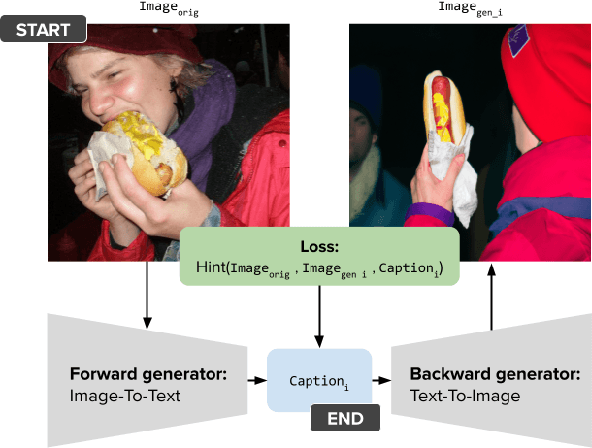

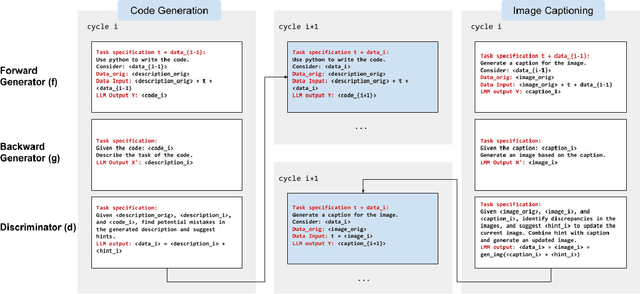

When LLMs perform zero-shot inference, they typically use a prompt with a task specification, and generate a completion. However, there is no work to explore the possibility of the reverse - going from completion to task specification. In this paper, we employ both directions to perform cycle-supervised learning entirely in-context. Our goal is to create a forward map f : X -> Y (e.g. image -> generated caption), coupled with a backward map g : Y -> X (e.g. caption -> generated image) to construct a cycle-consistency "loss" (formulated as an update to the prompt) to enforce g(f(X)) ~= X. The technique, called CyclePrompt, uses cycle-consistency as a free supervisory signal to iteratively craft the prompt. Importantly, CyclePrompt reinforces model performance without expensive fine-tuning, without training data, and without the complexity of external environments (e.g. compilers, APIs). We demonstrate CyclePrompt in two domains: code generation and image captioning. Our results on the HumanEval coding benchmark put us in first place on the leaderboard among models that do not rely on extra training data or usage of external environments, and third overall. Compared to the GPT4 baseline, we improve accuracy from 80.5% to 87.2%. In the vision-language space, we generate detailed image captions which outperform baseline zero-shot GPT4V captions, when tested against natural (VQAv2) and diagrammatic (FigureQA) visual question-answering benchmarks. To the best of our knowledge, this is the first use of self-supervised learning for prompting.
Exploring Group and Symmetry Principles in Large Language Models
Feb 09, 2024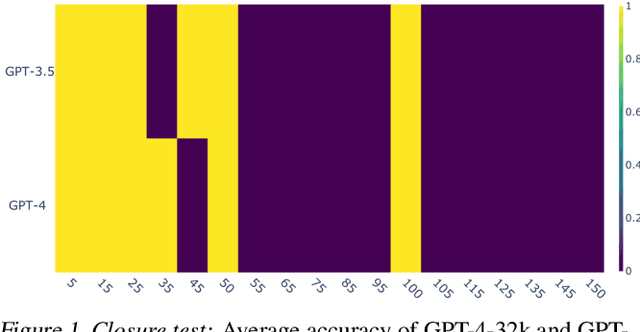
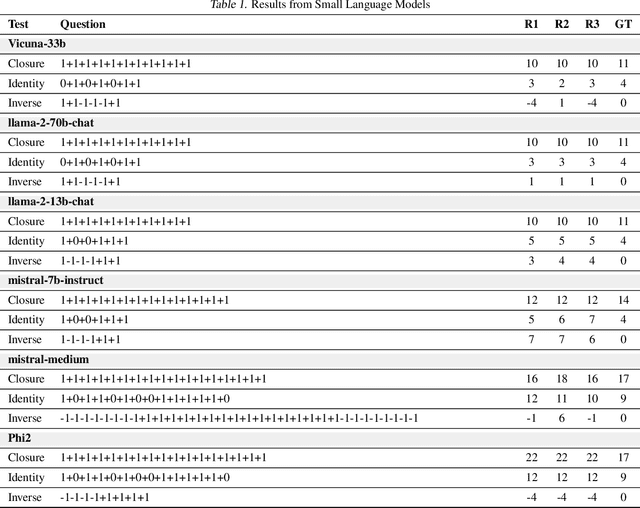
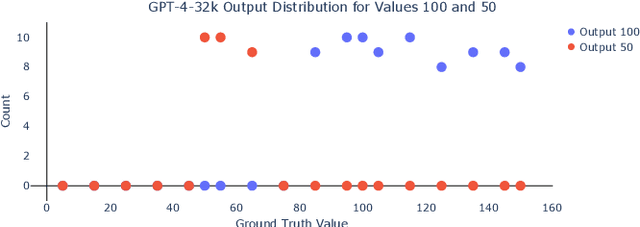
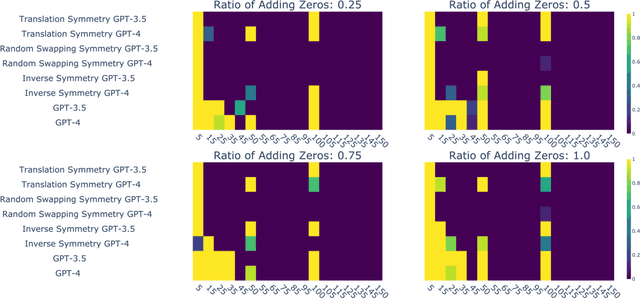
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of applications; however, assessing their reasoning capabilities remains a significant challenge. In this paper, we introduce a framework grounded in group and symmetry principles, which have played a crucial role in fields such as physics and mathematics, and offer another way to evaluate their capabilities. While the proposed framework is general, to showcase the benefits of employing these properties, we focus on arithmetic reasoning and investigate the performance of these models on four group properties: closure, identity, inverse, and associativity. Our findings reveal that LLMs studied in this work struggle to preserve group properties across different test regimes. In the closure test, we observe biases towards specific outputs and an abrupt degradation in their performance from 100% to 0% after a specific sequence length. They also perform poorly in the identity test, which represents adding irrelevant information in the context, and show sensitivity when subjected to inverse test, which examines the robustness of the model with respect to negation. In addition, we demonstrate that breaking down problems into smaller steps helps LLMs in the associativity test that we have conducted. To support these tests we have developed a synthetic dataset which will be released.
DiversiGATE: A Comprehensive Framework for Reliable Large Language Models
Jun 26, 2023In this paper, we introduce DiversiGATE, a unified framework that consolidates diverse methodologies for LLM verification. The proposed framework comprises two main components: Diversification and Aggregation which provide a holistic perspective on existing verification approaches, such as Self-Consistency, Math Prompter and WebGPT. Furthermore, we propose a novel `SelfLearner' model that conforms to the DiversiGATE framework which can learn from its own outputs and refine its performance over time, leading to improved accuracy. To evaluate the effectiveness of SelfLearner, we conducted a rigorous series of experiments, including tests on synthetic data as well as on popular arithmetic reasoning benchmarks such as GSM8K. Our results demonstrate that our approach outperforms traditional LLMs, achieving a considerable 54.8% -> 61.8% improvement on the GSM8K benchmark.
Are uGLAD? Time will tell!
Mar 21, 2023We frequently encounter multiple series that are temporally correlated in our surroundings, such as EEG data to examine alterations in brain activity or sensors to monitor body movements. Segmentation of multivariate time series data is a technique for identifying meaningful patterns or changes in the time series that can signal a shift in the system's behavior. However, most segmentation algorithms have been designed primarily for univariate time series, and their performance on multivariate data remains largely unsatisfactory, making this a challenging problem. In this work, we introduce a novel approach for multivariate time series segmentation using conditional independence (CI) graphs. CI graphs are probabilistic graphical models that represents the partial correlations between the nodes. We propose a domain agnostic multivariate segmentation framework `$\texttt{tGLAD}$' which draws a parallel between the CI graph nodes and the variables of the time series. Consider applying a graph recovery model $\texttt{uGLAD}$ to a short interval of the time series, it will result in a CI graph that shows partial correlations among the variables. We extend this idea to the entire time series by utilizing a sliding window to create a batch of time intervals and then run a single $\texttt{uGLAD}$ model in multitask learning mode to recover all the CI graphs simultaneously. As a result, we obtain a corresponding temporal CI graphs representation. We then designed a first-order and second-order based trajectory tracking algorithms to study the evolution of these graphs across distinct intervals. Finally, an `Allocation' algorithm is used to determine a suitable segmentation of the temporal graph sequence. $\texttt{tGLAD}$ provides a competitive time complexity of $O(N)$ for settings where number of variables $D<<N$. We demonstrate successful empirical results on a Physical Activity Monitoring data.
MathPrompter: Mathematical Reasoning using Large Language Models
Mar 04, 2023


Large Language Models (LLMs) have limited performance when solving arithmetic reasoning tasks and often provide incorrect answers. Unlike natural language understanding, math problems typically have a single correct answer, making the task of generating accurate solutions more challenging for LLMs. To the best of our knowledge, we are not aware of any LLMs that indicate their level of confidence in their responses which fuels a trust deficit in these models impeding their adoption. To address this deficiency, we propose `MathPrompter', a technique that improves performance of LLMs on arithmetic problems along with increased reliance in the predictions. MathPrompter uses the Zero-shot chain-of-thought prompting technique to generate multiple Algebraic expressions or Python functions to solve the same math problem in different ways and thereby raise the confidence level in the output results. This is in contrast to other prompt based CoT methods, where there is no check on the validity of the intermediate steps followed. Our technique improves over state-of-the-art on the MultiArith dataset ($78.7\%\rightarrow92.5\%$) evaluated using 175B parameter GPT-based LLM.