 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Augmented Coreset Expansion for Scalable Dataset Distillation
Dec 05, 2024



With the rapid scaling of neural networks, data storage and communication demands have intensified. Dataset distillation has emerged as a promising solution, condensing information from extensive datasets into a compact set of synthetic samples by solving a bilevel optimization problem. However, current methods face challenges in computational efficiency, particularly with high-resolution data and complex architectures. Recently, knowledge-distillation-based dataset condensation approaches have made this process more computationally feasible. Yet, with the recent developments of generative foundation models, there is now an opportunity to achieve even greater compression, enhance the quality of distilled data, and introduce valuable diversity into the data representation. In this work, we propose a two-stage solution. First, we compress the dataset by selecting only the most informative patches to form a coreset. Next, we leverage a generative foundation model to dynamically expand this compressed set in real-time, enhancing the resolution of these patches and introducing controlled variability to the coreset. Our extensive experiments demonstrate the robustness and efficiency of our approach across a range of dataset distillation benchmarks. We demonstrate a significant improvement of over 10% compared to the state-of-the-art on several large-scale dataset distillation benchmarks. The code will be released soon.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
Learning How To Ask: Cycle-Consistency Refines Prompts in Multimodal Foundation Models
Feb 13, 2024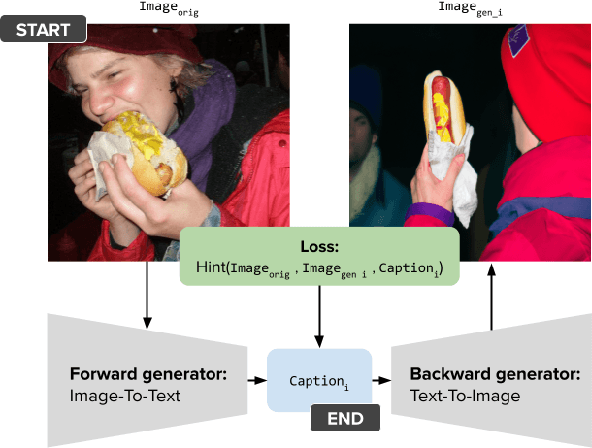

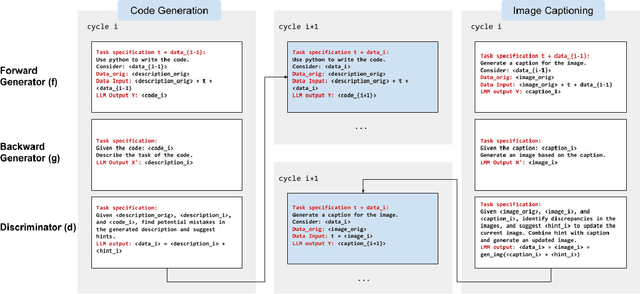

When LLMs perform zero-shot inference, they typically use a prompt with a task specification, and generate a completion. However, there is no work to explore the possibility of the reverse - going from completion to task specification. In this paper, we employ both directions to perform cycle-supervised learning entirely in-context. Our goal is to create a forward map f : X -> Y (e.g. image -> generated caption), coupled with a backward map g : Y -> X (e.g. caption -> generated image) to construct a cycle-consistency "loss" (formulated as an update to the prompt) to enforce g(f(X)) ~= X. The technique, called CyclePrompt, uses cycle-consistency as a free supervisory signal to iteratively craft the prompt. Importantly, CyclePrompt reinforces model performance without expensive fine-tuning, without training data, and without the complexity of external environments (e.g. compilers, APIs). We demonstrate CyclePrompt in two domains: code generation and image captioning. Our results on the HumanEval coding benchmark put us in first place on the leaderboard among models that do not rely on extra training data or usage of external environments, and third overall. Compared to the GPT4 baseline, we improve accuracy from 80.5% to 87.2%. In the vision-language space, we generate detailed image captions which outperform baseline zero-shot GPT4V captions, when tested against natural (VQAv2) and diagrammatic (FigureQA) visual question-answering benchmarks. To the best of our knowledge, this is the first use of self-supervised learning for prompting.
Automated Neuron Shape Analysis from Electron Microscopy
May 29, 2020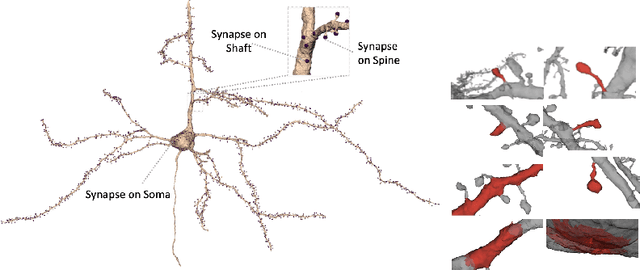
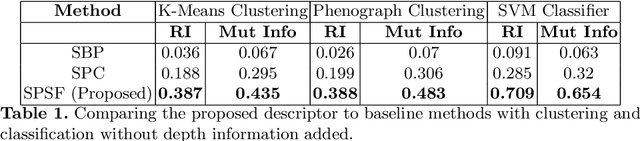
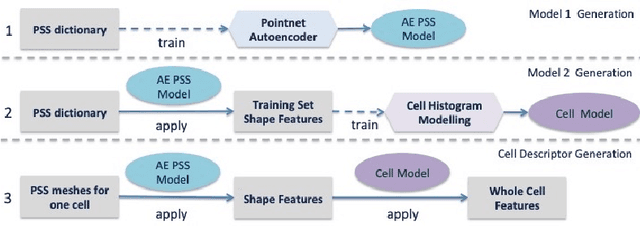
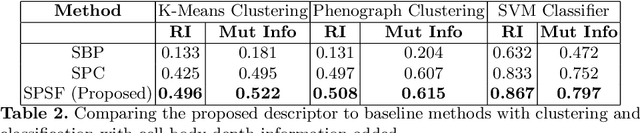
Morphology based analysis of cell types has been an area of great interest to the neuroscience community for several decades. Recently, high resolution electron microscopy (EM) datasets of the mouse brain have opened up opportunities for data analysis at a level of detail that was previously impossible. These datasets are very large in nature and thus, manual analysis is not a practical solution. Of particular interest are details to the level of post synaptic structures. This paper proposes a fully automated framework for analysis of post-synaptic structure based neuron analysis from EM data. The processing framework involves shape extraction, representation with an autoencoder, and whole cell modeling and analysis based on shape distributions. We apply our novel framework on a dataset of 1031 neurons obtained from imaging a 1mm x 1mm x 40 micrometer volume of the mouse visual cortex and show the strength of our method in clustering and classification of neuronal shapes.