 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-dimensional Evaluation of Tokenizer-free Multilingual Pretrained Models
Paper and Code

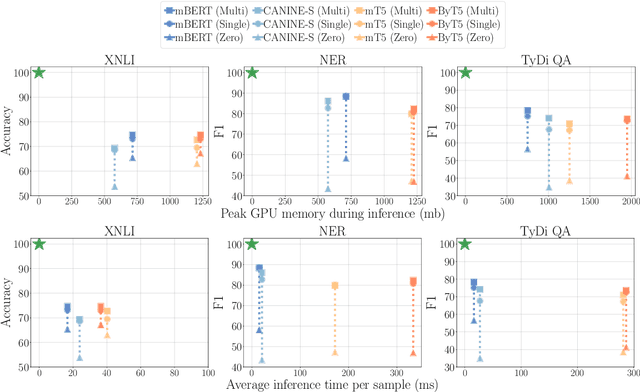


Recent work on tokenizer-free multilingual pretrained models show promising results in improving cross-lingual transfer and reducing engineering overhead (Clark et al., 2022; Xue et al., 2022). However, these works mainly focus on reporting accuracy on a limited set of tasks and data settings, placing less emphasis on other important factors when tuning and deploying the models in practice, such as memory usage, inference speed, and fine-tuning data robustness. We attempt to fill this gap by performing a comprehensive empirical comparison of multilingual tokenizer-free and subword-based models considering these various dimensions. Surprisingly, we find that subword-based models might still be the most practical choice in many settings, achieving better performance for lower inference latency and memory usage. Based on these results, we encourage future work in tokenizer-free methods to consider these factors when designing and evaluating new models.