 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Retraining for Online RL: Decoupled Policy Learning to Mitigate Exploration Bias
Paper and Code
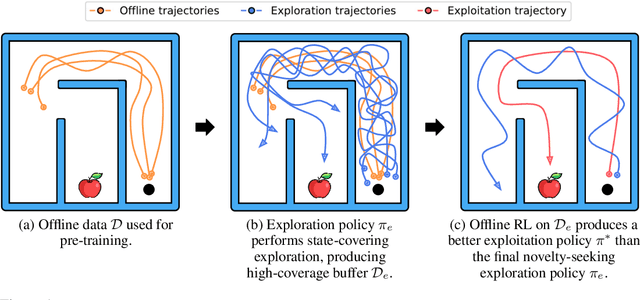
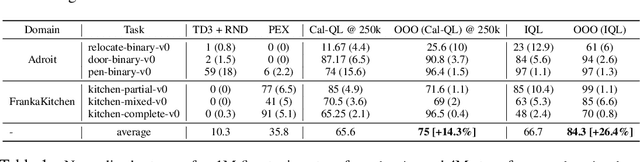
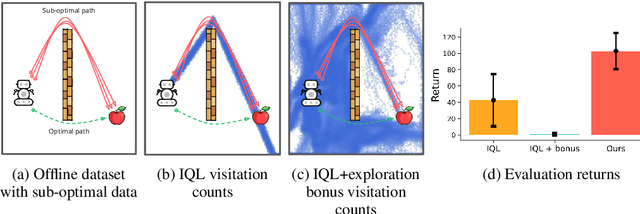

It is desirable for policies to optimistically explore new states and behaviors during online reinforcement learning (RL) or fine-tuning, especially when prior offline data does not provide enough state coverage. However, exploration bonuses can bias the learned policy, and our experiments find that naive, yet standard use of such bonuses can fail to recover a performant policy. Concurrently, pessimistic training in offline RL has enabled recovery of performant policies from static datasets. Can we leverage offline RL to recover better policies from online interaction? We make a simple observation that a policy can be trained from scratch on all interaction data with pessimistic objectives, thereby decoupling the policies used for data collection and for evaluation. Specifically, we propose offline retraining, a policy extraction step at the end of online fine-tuning in our Offline-to-Online-to-Offline (OOO) framework for reinforcement learning (RL). An optimistic (exploration) policy is used to interact with the environment, and a separate pessimistic (exploitation) policy is trained on all the observed data for evaluation. Such decoupling can reduce any bias from online interaction (intrinsic rewards, primacy bias) in the evaluation policy, and can allow more exploratory behaviors during online interaction which in turn can generate better data for exploitation. OOO is complementary to several offline-to-online RL and online RL methods, and improves their average performance by 14% to 26% in our fine-tuning experiments, achieves state-of-the-art performance on several environments in the D4RL benchmarks, and improves online RL performance by 165% on two OpenAI gym environments. Further, OOO can enable fine-tuning from incomplete offline datasets where prior methods can fail to recover a performant policy. Implementation: https://github.com/MaxSobolMark/OOO