 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWild-Time: A Benchmark of in-the-Wild Distribution Shift over Time
Paper and Code
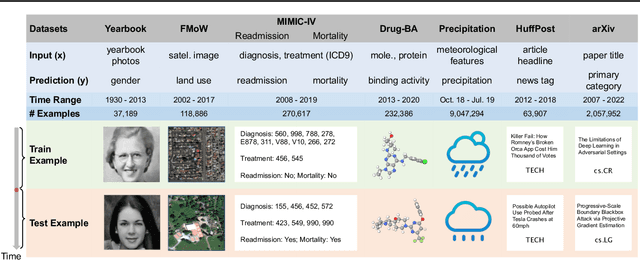
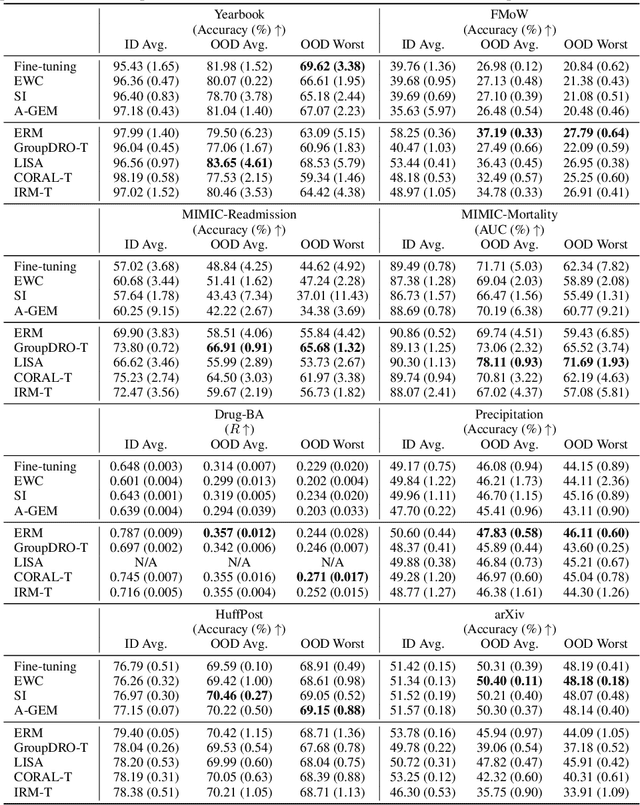
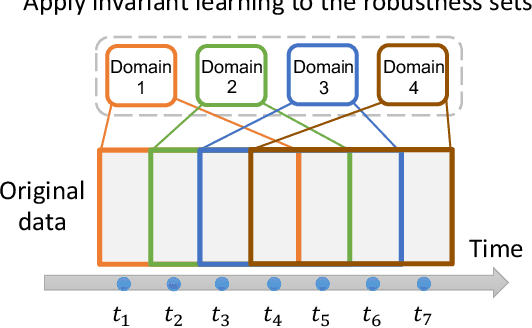
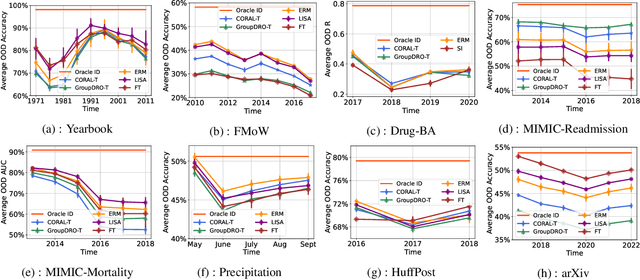
Distribution shift occurs when the test distribution differs from the training distribution, and it can considerably degrade performance of machine learning models deployed in the real world. Temporal shifts -- distribution shifts arising from the passage of time -- often occur gradually and have the additional structure of timestamp metadata. By leveraging timestamp metadata, models can potentially learn from trends in past distribution shifts and extrapolate into the future. While recent works have studied distribution shifts, temporal shifts remain underexplored. To address this gap, we curate Wild-Time, a benchmark of 5 datasets that reflect temporal distribution shifts arising in a variety of real-world applications, including patient prognosis and news classification. On these datasets, we systematically benchmark 13 prior approaches, including methods in domain generalization, continual learning, self-supervised learning, and ensemble learning. We use two evaluation strategies: evaluation with a fixed time split (Eval-Fix) and evaluation with a data stream (Eval-Stream). Eval-Fix, our primary evaluation strategy, aims to provide a simple evaluation protocol, while Eval-Stream is more realistic for certain real-world applications. Under both evaluation strategies, we observe an average performance drop of 20% from in-distribution to out-of-distribution data. Existing methods are unable to close this gap. Code is available at https://wild-time.github.io/.