 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Developer and LLM Biases in Code Evaluation
Mar 25, 2026As LLMs are increasingly used as judges in code applications, they should be evaluated in realistic interactive settings that capture partial context and ambiguous intent. We present TRACE (Tool for Rubric Analysis in Code Evaluation), a framework that evaluates LLM judges' ability to predict human preferences and automatically extracts rubric items to reveal systematic biases in how humans and models weigh each item. Across three modalities -- chat-based programming, IDE autocompletion, and instructed code editing -- we use TRACE to measure how well LLM judges align with developer preferences. Among 13 different models, the best judges underperform human annotators by 12-23%. TRACE identifies 35 significant sources of misalignment between humans and judges across interaction modalities, the majority of which correspond to existing software engineering code quality criteria. For example, in chat-based coding, judges are biased towards longer code explanations while humans prefer shorter ones. We find significant misalignment on the majority of existing code quality dimensions, showing alignment gaps between LLM judges and human preference in realistic coding applications.
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization
Sep 27, 2024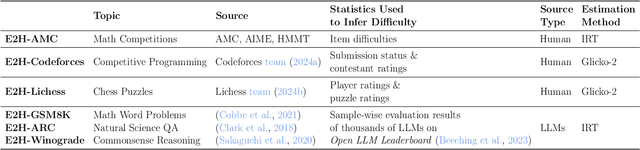

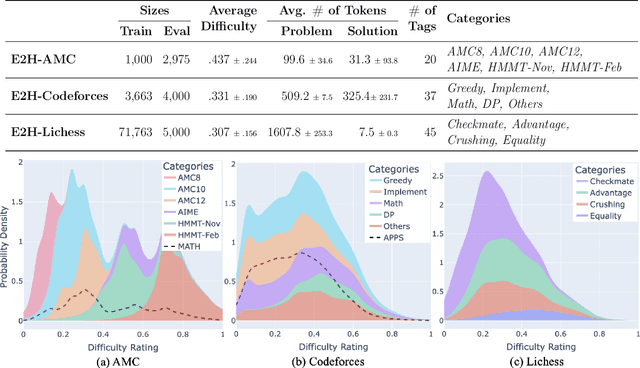
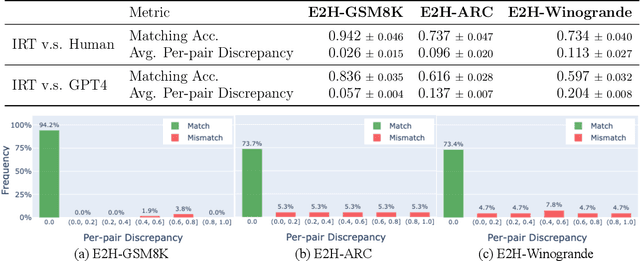
While generalization over tasks from easy to hard is crucial to profile language models (LLMs), the datasets with fine-grained difficulty annotations for each problem across a broad range of complexity are still blank. Aiming to address this limitation, we present Easy2Hard-Bench, a consistently formatted collection of 6 benchmark datasets spanning various domains, such as mathematics and programming problems, chess puzzles, and reasoning questions. Each problem within these datasets is annotated with numerical difficulty scores. To systematically estimate problem difficulties, we collect abundant performance data on attempts to each problem by humans in the real world or LLMs on the prominent leaderboard. Leveraging the rich performance data, we apply well-established difficulty ranking systems, such as Item Response Theory (IRT) and Glicko-2 models, to uniformly assign numerical difficulty scores to problems. Moreover, datasets in Easy2Hard-Bench distinguish themselves from previous collections by a higher proportion of challenging problems. Through extensive experiments with six state-of-the-art LLMs, we provide a comprehensive analysis of their performance and generalization capabilities across varying levels of difficulty, with the aim of inspiring future research in LLM generalization. The datasets are available at https://huggingface.co/datasets/furonghuang-lab/Easy2Hard-Bench.
Shadowcast: Stealthy Data Poisoning Attacks Against Vision-Language Models
Feb 05, 2024



Vision-Language Models (VLMs) excel in generating textual responses from visual inputs, yet their versatility raises significant security concerns. This study takes the first step in exposing VLMs' susceptibility to data poisoning attacks that can manipulate responses to innocuous, everyday prompts. We introduce Shadowcast, a stealthy data poisoning attack method where poison samples are visually indistinguishable from benign images with matching texts. Shadowcast demonstrates effectiveness in two attack types. The first is Label Attack, tricking VLMs into misidentifying class labels, such as confusing Donald Trump for Joe Biden. The second is Persuasion Attack, which leverages VLMs' text generation capabilities to craft narratives, such as portraying junk food as health food, through persuasive and seemingly rational descriptions. We show that Shadowcast are highly effective in achieving attacker's intentions using as few as 50 poison samples. Moreover, these poison samples remain effective across various prompts and are transferable across different VLM architectures in the black-box setting. This work reveals how poisoned VLMs can generate convincing yet deceptive misinformation and underscores the importance of data quality for responsible deployments of VLMs. Our code is available at: https://github.com/umd-huang-lab/VLM-Poisoning.