 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Distance Metrics for Counterfactual Explainability
Oct 18, 2024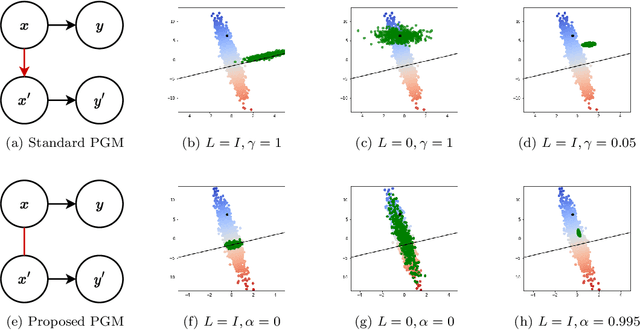
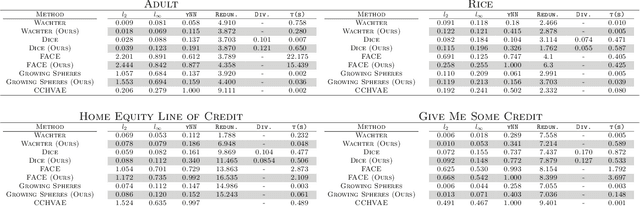
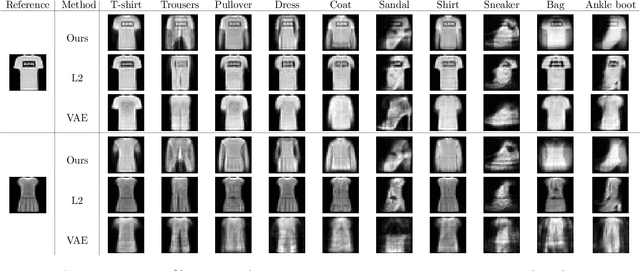
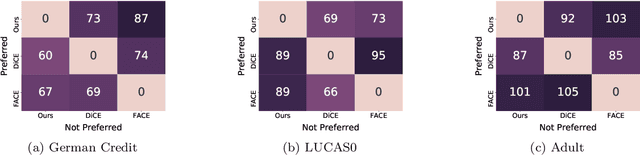
Counterfactual explanations have been a popular method of post-hoc explainability for a variety of settings in Machine Learning. Such methods focus on explaining classifiers by generating new data points that are similar to a given reference, while receiving a more desirable prediction. In this work, we investigate a framing for counterfactual generation methods that considers counterfactuals not as independent draws from a region around the reference, but as jointly sampled with the reference from the underlying data distribution. Through this framing, we derive a distance metric, tailored for counterfactual similarity that can be applied to a broad range of settings. Through both quantitative and qualitative analyses of counterfactual generation methods, we show that this framing allows us to express more nuanced dependencies among the covariates.
Prompt Recovery for Image Generation Models: A Comparative Study of Discrete Optimizers
Aug 12, 2024Recovering natural language prompts for image generation models, solely based on the generated images is a difficult discrete optimization problem. In this work, we present the first head-to-head comparison of recent discrete optimization techniques for the problem of prompt inversion. We evaluate Greedy Coordinate Gradients (GCG), PEZ , Random Search, AutoDAN and BLIP2's image captioner across various evaluation metrics related to the quality of inverted prompts and the quality of the images generated by the inverted prompts. We find that focusing on the CLIP similarity between the inverted prompts and the ground truth image acts as a poor proxy for the similarity between ground truth image and the image generated by the inverted prompts. While the discrete optimizers effectively minimize their objectives, simply using responses from a well-trained captioner often leads to generated images that more closely resemble those produced by the original prompts.
FUSE-ing Language Models: Zero-Shot Adapter Discovery for Prompt Optimization Across Tokenizers
Aug 09, 2024The widespread use of large language models has resulted in a multitude of tokenizers and embedding spaces, making knowledge transfer in prompt discovery tasks difficult. In this work, we propose FUSE (Flexible Unification of Semantic Embeddings), an inexpensive approach to approximating an adapter layer that maps from one model's textual embedding space to another, even across different tokenizers. We introduce a third-order tensor-based representation of a model's embedding space that aligns semantic embeddings that have been split apart by different tokenizers, and use this representation to derive an approximation of the gradient of one model's outputs with respect to another model's embedding space. We show the efficacy of our approach via multi-objective optimization over vision-language and causal language models for image captioning and sentiment-based image captioning.