 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Feb 04, 2025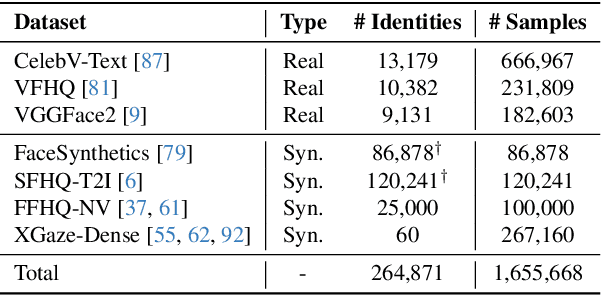
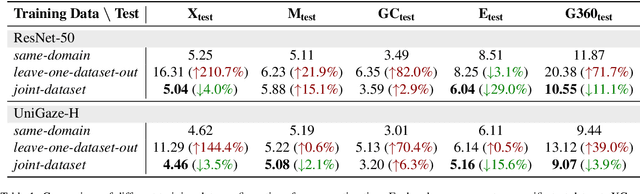

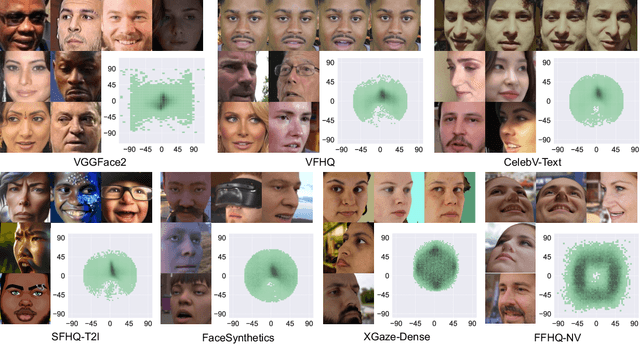
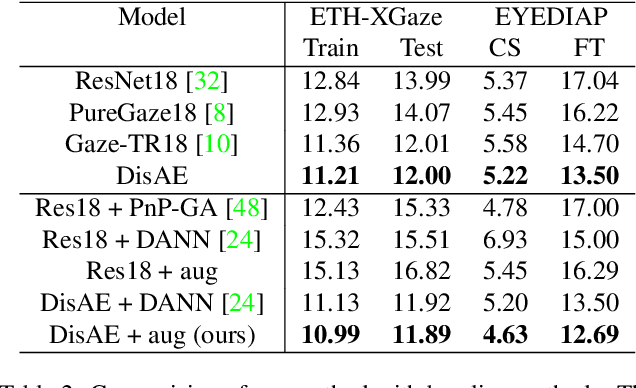
Despite decades of research on data collection and model architectures, current gaze estimation models face significant challenges in generalizing across diverse data domains. While recent advances in self-supervised pre-training have shown remarkable potential for improving model generalization in various vision tasks, their effectiveness in gaze estimation remains unexplored due to the geometric nature of the gaze regression task. We propose UniGaze, which leverages large-scale, in-the-wild facial datasets through self-supervised pre-training for gaze estimation. We carefully curate multiple facial datasets that capture diverse variations in identity, lighting, background, and head poses. By directly applying Masked Autoencoder (MAE) pre-training on normalized face images with a Vision Transformer (ViT) backbone, our UniGaze learns appropriate feature representations within the specific input space required by downstream gaze estimation models. Through comprehensive experiments using challenging cross-dataset evaluation and novel protocols, including leave-one-dataset-out and joint-dataset settings, we demonstrate that UniGaze significantly improves generalization across multiple data domains while minimizing reliance on costly labeled data. The source code and pre-trained models will be released upon acceptance.
Angle Range and Identity Similarity Enhanced Gaze and Head Redirection based on Synthetic data
Sep 11, 2023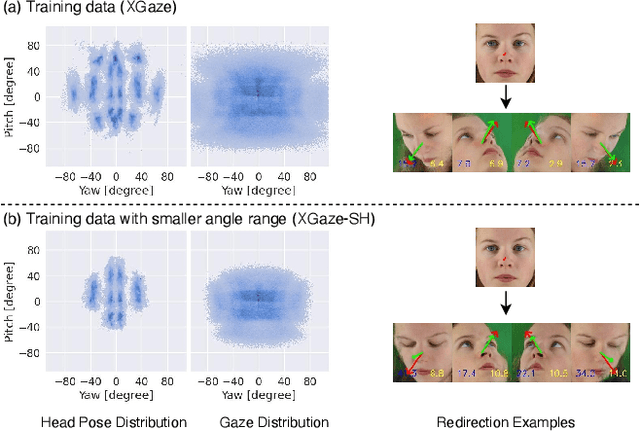

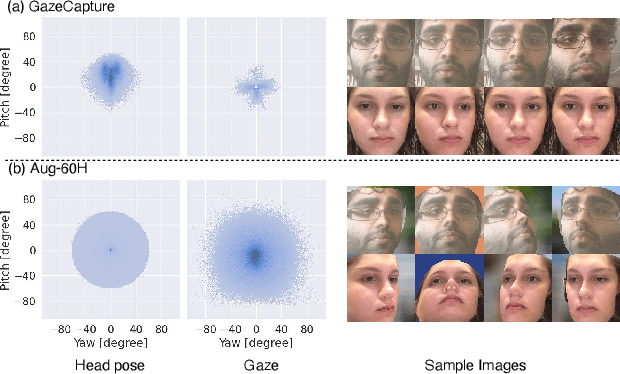
In this paper, we propose a method for improving the angular accuracy and photo-reality of gaze and head redirection in full-face images. The problem with current models is that they cannot handle redirection at large angles, and this limitation mainly comes from the lack of training data. To resolve this problem, we create data augmentation by monocular 3D face reconstruction to extend the head pose and gaze range of the real data, which allows the model to handle a wider redirection range. In addition to the main focus on data augmentation, we also propose a framework with better image quality and identity preservation of unseen subjects even training with synthetic data. Experiments show that our method significantly improves redirection performance in terms of redirection angular accuracy while maintaining high image quality, especially when redirecting to large angles.
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
May 25, 2023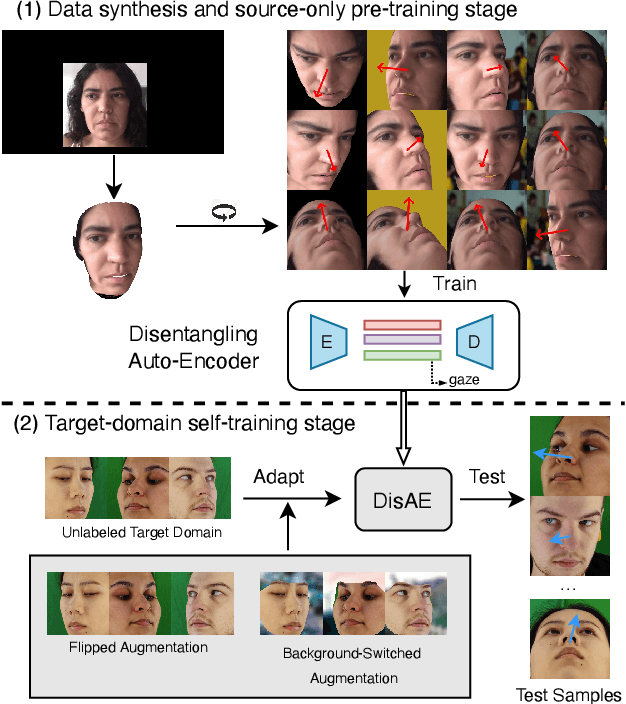
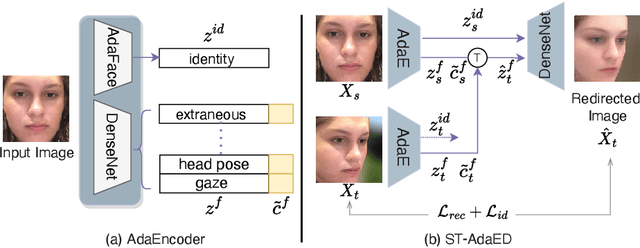
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play a significant role in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, we show that the model only using monocular-reconstructed synthetic training data can perform comparably to real data with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at \url{https://github.com/ut-vision/AdaptiveGaze}.
Rotation-Constrained Cross-View Feature Fusion for Multi-View Appearance-based Gaze Estimation
May 22, 2023

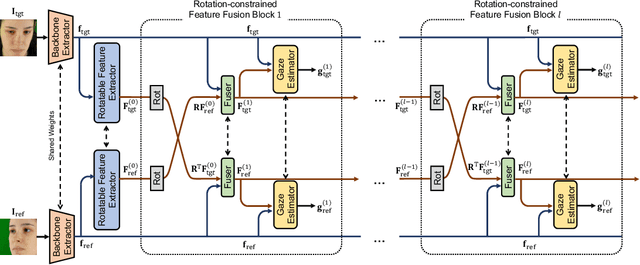

Appearance-based gaze estimation has been actively studied in recent years. However, its generalization performance for unseen head poses is still a significant limitation for existing methods. This work proposes a generalizable multi-view gaze estimation task and a cross-view feature fusion method to address this issue. In addition to paired images, our method takes the relative rotation matrix between two cameras as additional input. The proposed network learns to extract rotatable feature representation by using relative rotation as a constraint and adaptively fuses the rotatable features via stacked fusion modules. This simple yet efficient approach significantly improves generalization performance under unseen head poses without significantly increasing computational cost. The model can be trained with random combinations of cameras without fixing the positioning and can generalize to unseen camera pairs during inference. Through experiments using multiple datasets, we demonstrate the advantage of the proposed method over baseline methods, including state-of-the-art domain generalization approaches.
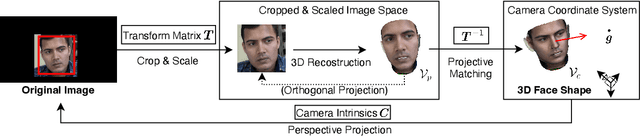
Learning-by-Novel-View-Synthesis for Full-Face Appearance-based 3D Gaze Estimation
Jan 23, 2022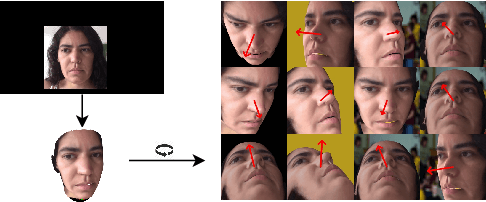
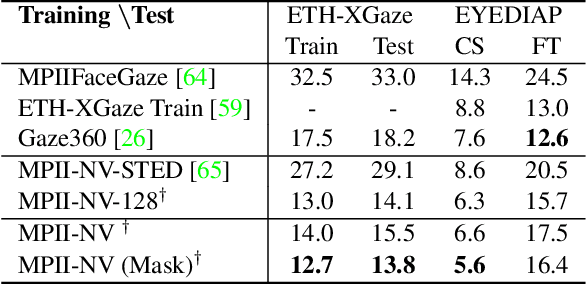
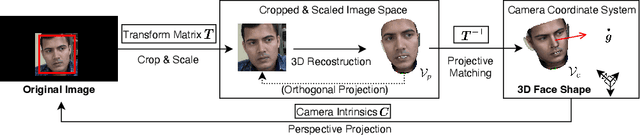
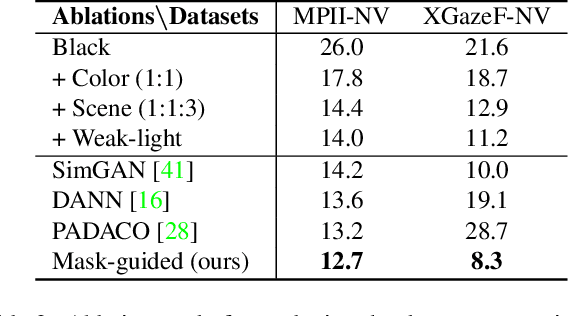
Despite recent advances in appearance-based gaze estimation techniques, the need for training data that covers the target head pose and gaze distribution remains a crucial challenge for practical deployment. This work examines a novel approach for synthesizing gaze estimation training data based on monocular 3D face reconstruction. Unlike prior works using multi-view reconstruction, photo-realistic CG models, or generative neural networks, our approach can manipulate and extend the head pose range of existing training data without any additional requirements. We introduce a projective matching procedure to align the reconstructed 3D facial mesh to the camera coordinate system and synthesize face images with accurate gaze labels. We also propose a mask-guided gaze estimation model and data augmentation strategies to further improve the estimation accuracy by taking advantage of the synthetic training data. Experiments using multiple public datasets show that our approach can significantly improve the estimation performance on challenging cross-dataset settings with non-overlapping gaze distributions.