 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Constrained Cross-View Feature Fusion for Multi-View Appearance-based Gaze Estimation
May 22, 2023

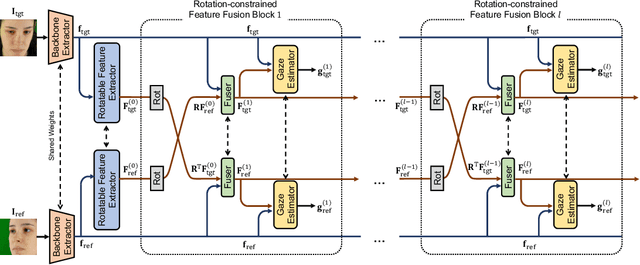

Appearance-based gaze estimation has been actively studied in recent years. However, its generalization performance for unseen head poses is still a significant limitation for existing methods. This work proposes a generalizable multi-view gaze estimation task and a cross-view feature fusion method to address this issue. In addition to paired images, our method takes the relative rotation matrix between two cameras as additional input. The proposed network learns to extract rotatable feature representation by using relative rotation as a constraint and adaptively fuses the rotatable features via stacked fusion modules. This simple yet efficient approach significantly improves generalization performance under unseen head poses without significantly increasing computational cost. The model can be trained with random combinations of cameras without fixing the positioning and can generalize to unseen camera pairs during inference. Through experiments using multiple datasets, we demonstrate the advantage of the proposed method over baseline methods, including state-of-the-art domain generalization approaches.
Cascading Feature Extraction for Fast Point Cloud Registration
Oct 23, 2021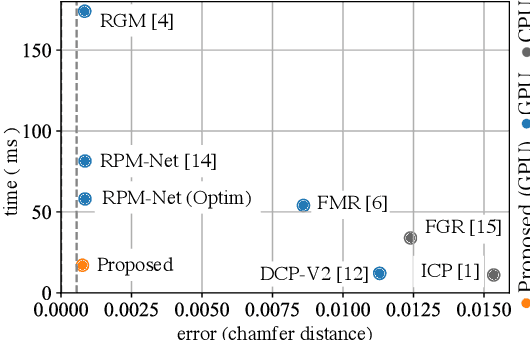
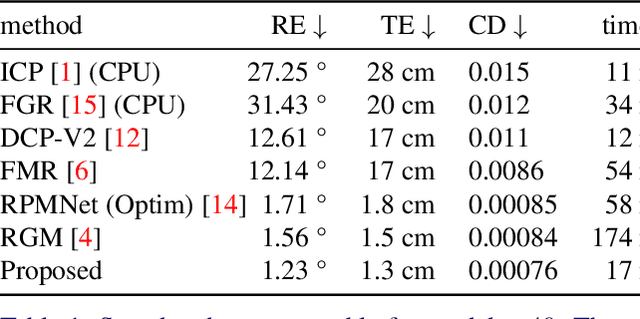
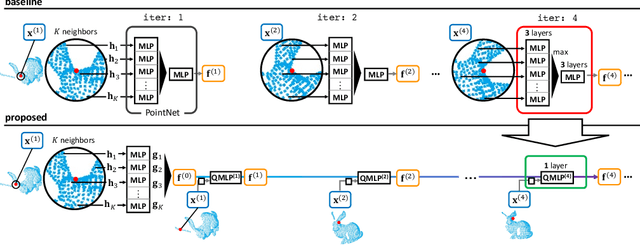
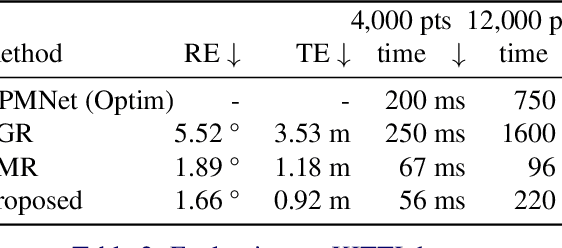
We propose a method for speeding up a 3D point cloud registration through a cascading feature extraction. The current approach with the highest accuracy is realized by iteratively executing feature extraction and registration using deep features. However, iterative feature extraction takes time. Our proposed method significantly reduces the computational cost using cascading shallow layers. Our idea is to omit redundant computations that do not always contribute to the final accuracy. The proposed approach is approximately three times faster than the existing methods without a loss of accuracy.