 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
Jun 11, 2026Search Agents -- large language models augmented with search tools -- have intensified the need for future-proof evaluation benchmarks. Existing benchmarks such as BrowseComp rely on static knowledge, making them vulnerable to test-set contamination and parametric memorization. Consequently, models can achieve high scores through fact recall rather than genuine retrieval, obscuring true browsing competence via reasoning shortcuts. In this paper, we introduce EvoBrowseComp, an evolving benchmark of 400 English and 400 Chinese contamination-free complex questions synthesized via live-web traversal. To collect these questions, we design a three-agent collaborative framework: (1) a QA synthesis agent that retrieves fresh knowledge from the live web to synthesize QA pairs; (2) an information filtering agent that filters retrieved knowledge in terms of credibility and popularity to block parametric shortcuts; and (3) a high-level guidance agent that formalizes questions into reasoning graphs to reduce logical redundancy and shortcuts in synthesized QA pairs. Because the framework supports fully automated synthesis, EvoBrowseComp can be regularly updated to prevent data contamination and maintain temporal freshness. Extensive experiments confirm its great difficulty, requiring broad horizontal search. It establishes a scalable paradigm for auto-updatable, high-difficulty benchmarking that keeps pace with both evolving world knowledge and advancing agent capabilities.
Evidence-Based Intelligent Diagnostic and Therapeutic Visualization System with Large Language Models: Multi-Turn Interaction and Multimodal Treatment Plan Generation
Jun 05, 2026Aim: Existing AI-assisted traditional Chinese medicine diagnostic tools suffer from opaque reasoning processes, passive interaction, and limited treatment plan presentation. This study proposes a knowledge-enhanced visual diagnostic system to improve the transparency and interpretability of syndrome differentiation and treatment. Methods: The system is built upon a Neo4j knowledge graph comprising 241 syndromes, 1,263 symptoms, and 2,485 relations. It incorporates a four-stage symptom matching pipeline (exact, semantic, fuzzy, and large language model verification), an information gain-driven proactive questioning strategy optimized with genetic algorithms, and a multimodal treatment presentation integrating artificial intelligence-generated illustrations, three-dimensional meridian-acupoint models, and evidence-based literature. Results: Knowledge graph constraints reduced non-standard outputs by 32%. Case studies validated the effectiveness of the interactive workflow across patient self-assessment, clinician-assisted diagnosis, and traditional Chinese medicine education. Automated paired-comparison evaluation across 30 cases further demonstrated significant improvements in diagnostic trust (Cohen's d = 1.82, p < 0.001), reduced cognitive load (improvements in four of five dimensions), and higher credibility of evidence-based references (4.21 vs. 2.95). Conclusions: The proposed system enhances the transparency of traditional Chinese medicine diagnostic reasoning and the interpretability of treatment plans through knowledge graph-driven visualization and multimodal interaction, offering a practical solution for trustworthy artificial intelligence-assisted traditional Chinese medicine applications.
A Structure-Agnostic Co-Tuning Framework for LLMs and SLMs in Cloud-Edge Systems
Nov 12, 2025
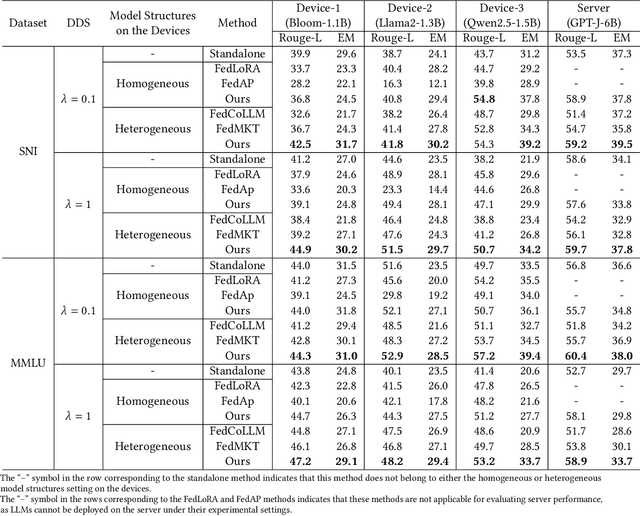
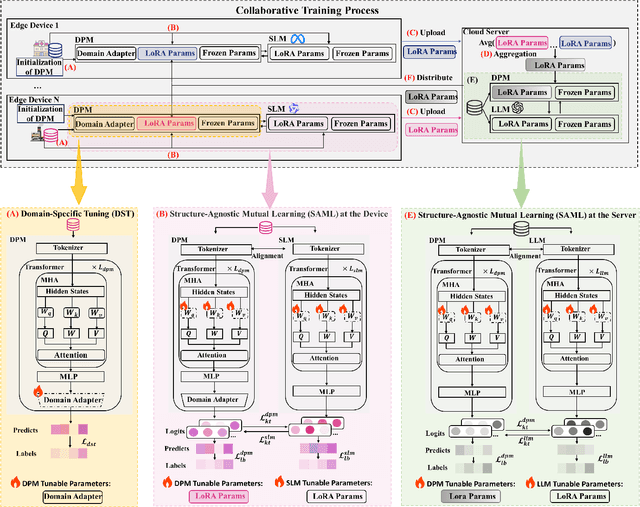
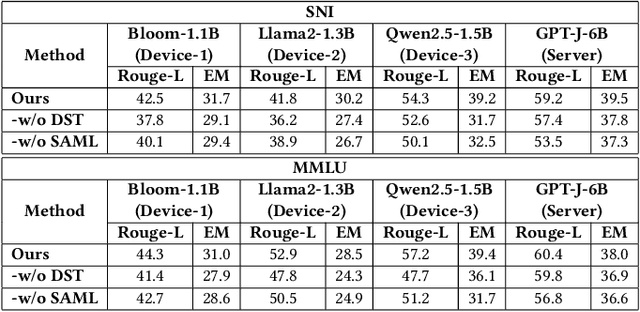
The surge in intelligent applications driven by large language models (LLMs) has made it increasingly difficult for bandwidth-limited cloud servers to process extensive LLM workloads in real time without compromising user data privacy. To solve these problems, recent research has focused on constructing cloud-edge consortia that integrate server-based LLM with small language models (SLMs) on mobile edge devices. Furthermore, designing collaborative training mechanisms within such consortia to enhance inference performance has emerged as a promising research direction. However, the cross-domain deployment of SLMs, coupled with structural heterogeneity in SLMs architectures, poses significant challenges to enhancing model performance. To this end, we propose Co-PLMs, a novel co-tuning framework for collaborative training of large and small language models, which integrates the process of structure-agnostic mutual learning to realize knowledge exchange between the heterogeneous language models. This framework employs distilled proxy models (DPMs) as bridges to enable collaborative training between the heterogeneous server-based LLM and on-device SLMs, while preserving the domain-specific insights of each device. The experimental results show that Co-PLMs outperform state-of-the-art methods, achieving average increases of 5.38% in Rouge-L and 4.88% in EM.
Investigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
Benchmarking Data Efficiency and Computational Efficiency of Temporal Action Localization Models
Aug 24, 2023



In temporal action localization, given an input video, the goal is to predict which actions it contains, where they begin, and where they end. Training and testing current state-of-the-art deep learning models requires access to large amounts of data and computational power. However, gathering such data is challenging and computational resources might be limited. This work explores and measures how current deep temporal action localization models perform in settings constrained by the amount of data or computational power. We measure data efficiency by training each model on a subset of the training set. We find that TemporalMaxer outperforms other models in data-limited settings. Furthermore, we recommend TriDet when training time is limited. To test the efficiency of the models during inference, we pass videos of different lengths through each model. We find that TemporalMaxer requires the least computational resources, likely due to its simple architecture.
Investigation of Architectures and Receptive Fields for Appearance-based Gaze Estimation
Aug 18, 2023


With the rapid development of deep learning technology in the past decade, appearance-based gaze estimation has attracted great attention from both computer vision and human-computer interaction research communities. Fascinating methods were proposed with variant mechanisms including soft attention, hard attention, two-eye asymmetry, feature disentanglement, rotation consistency, and contrastive learning. Most of these methods take the single-face or multi-region as input, yet the basic architecture of gaze estimation has not been fully explored. In this paper, we reveal the fact that tuning a few simple parameters of a ResNet architecture can outperform most of the existing state-of-the-art methods for the gaze estimation task on three popular datasets. With our extensive experiments, we conclude that the stride number, input image resolution, and multi-region architecture are critical for the gaze estimation performance while their effectiveness dependent on the quality of the input face image. We obtain the state-of-the-art performances on three datasets with 3.64 on ETH-XGaze, 4.50 on MPIIFaceGaze, and 9.13 on Gaze360 degrees gaze estimation error by taking ResNet-50 as the backbone.
A Deep Learning Approach to Predicting Ventilator Parameters for Mechanically Ventilated Septic Patients
Feb 21, 2022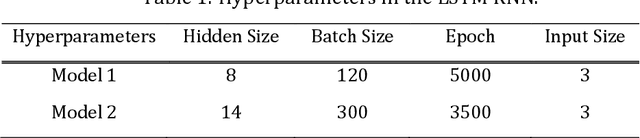
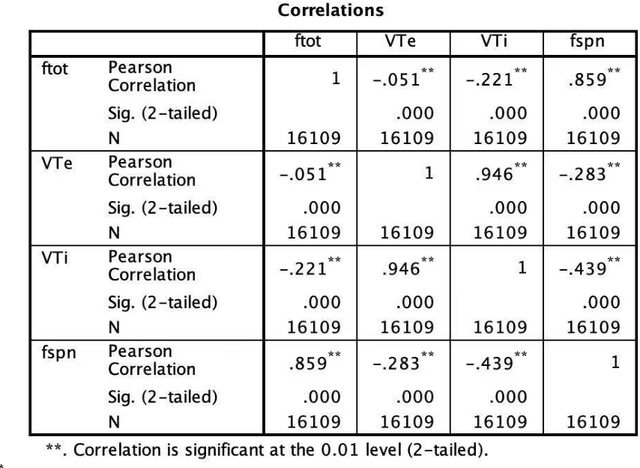
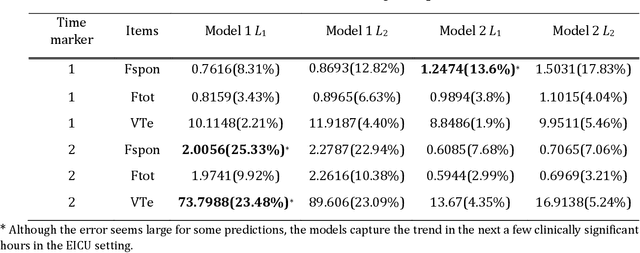
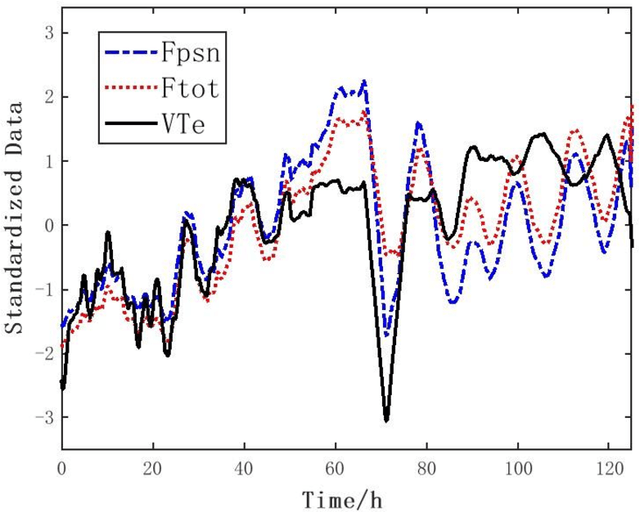
We develop a deep learning approach to predicting a set of ventilator parameters for a mechanically ventilated septic patient using a long and short term memory (LSTM) recurrent neural network (RNN) model. We focus on short-term predictions of a set of ventilator parameters for the septic patient in emergency intensive care unit (EICU). The short-term predictability of the model provides attending physicians with early warnings to make timely adjustment to the treatment of the patient in the EICU. The patient specific deep learning model can be trained on any given critically ill patient, making it an intelligent aide for physicians to use in emergent medical situations.