 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synchronized Audio-Visual Multi-View Capture System
Mar 24, 2026Multi-view capture systems have been an important tool in research for recording human motion under controlling conditions. Most existing systems are specified around video streams and provide little or no support for audio acquisition and rigorous audio-video alignment, despite both being essential for studying conversational interaction where timing at the level of turn-taking, overlap, and prosody matters. In this technical report, we describe an audio-visual multi-view capture system that addresses this gap by treating synchronized audio and synchronized video as first-class signals. The system combines a multi-camera pipeline with multi-channel microphone recording under a unified timing architecture and provides a practical workflow for calibration, acquisition, and quality control that supports repeatable recordings at scale. We quantify synchronization performance in deployment and show that the resulting recordings are temporally consistent enough to support fine-grained analysis and data-driven modeling of conversation behavior.
Investigation of Architectures and Receptive Fields for Appearance-based Gaze Estimation
Aug 18, 2023


With the rapid development of deep learning technology in the past decade, appearance-based gaze estimation has attracted great attention from both computer vision and human-computer interaction research communities. Fascinating methods were proposed with variant mechanisms including soft attention, hard attention, two-eye asymmetry, feature disentanglement, rotation consistency, and contrastive learning. Most of these methods take the single-face or multi-region as input, yet the basic architecture of gaze estimation has not been fully explored. In this paper, we reveal the fact that tuning a few simple parameters of a ResNet architecture can outperform most of the existing state-of-the-art methods for the gaze estimation task on three popular datasets. With our extensive experiments, we conclude that the stride number, input image resolution, and multi-region architecture are critical for the gaze estimation performance while their effectiveness dependent on the quality of the input face image. We obtain the state-of-the-art performances on three datasets with 3.64 on ETH-XGaze, 4.50 on MPIIFaceGaze, and 9.13 on Gaze360 degrees gaze estimation error by taking ResNet-50 as the backbone.
GazeNeRF: 3D-Aware Gaze Redirection with Neural Radiance Fields
Dec 08, 2022



We propose GazeNeRF, a 3D-aware method for the task of gaze redirection. Existing gaze redirection methods operate on 2D images and struggle to generate 3D consistent results. Instead, we build on the intuition that the face region and eyeballs are separate 3D structures that move in a coordinated yet independent fashion. Our method leverages recent advancements in conditional image-based neural radiance fields and proposes a two-stream architecture that predicts volumetric features for the face and eye regions separately. Rigidly transforming the eye features via a 3D rotation matrix provides fine-grained control over the desired gaze angle. The final, redirected image is then attained via differentiable volume compositing. Our experiments show that this architecture outperforms naively conditioned NeRF baselines as well as previous state-of-the-art 2D gaze redirection methods in terms of redirection accuracy and identity preservation.
Zoom-CAM: Generating Fine-grained Pixel Annotations from Image Labels
Oct 16, 2020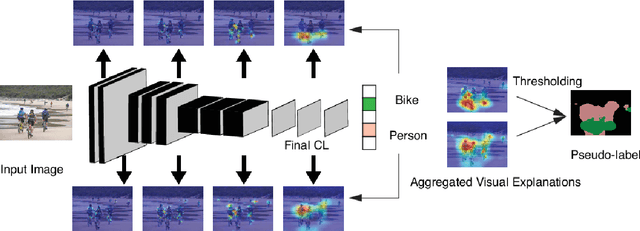
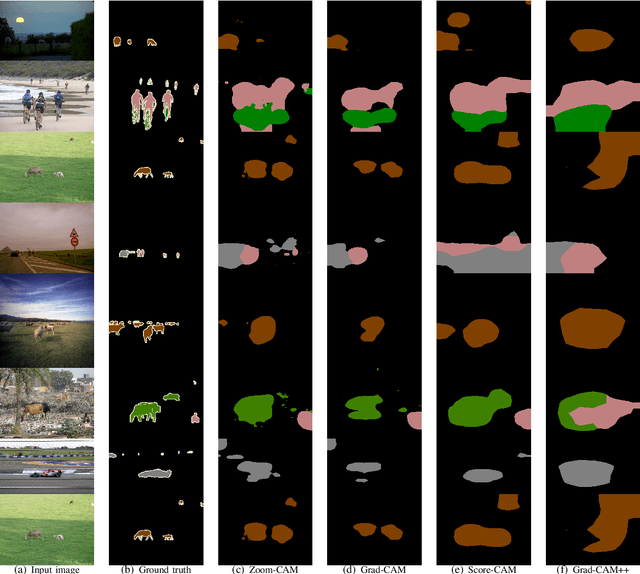
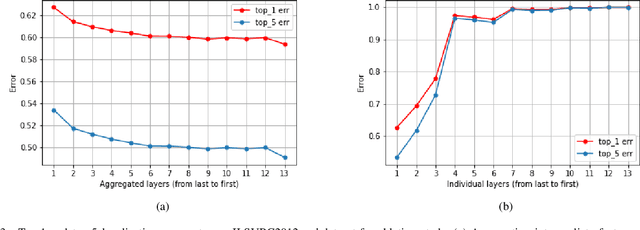

Current weakly supervised object localization and segmentation rely on class-discriminative visualization techniques to generate pseudo-labels for pixel-level training. Such visualization methods, including class activation mapping (CAM) and Grad-CAM, use only the deepest, lowest resolution convolutional layer, missing all information in intermediate layers. We propose Zoom-CAM: going beyond the last lowest resolution layer by integrating the importance maps over all activations in intermediate layers. Zoom-CAM captures fine-grained small-scale objects for various discriminative class instances, which are commonly missed by the baseline visualization methods. We focus on generating pixel-level pseudo-labels from class labels. The quality of our pseudo-labels evaluated on the ImageNet localization task exhibits more than 2.8% improvement on top-1 error. For weakly supervised semantic segmentation our generated pseudo-labels improve a state of the art model by 1.1%.
WeightAlign: Normalizing Activations by Weight Alignment
Oct 14, 2020
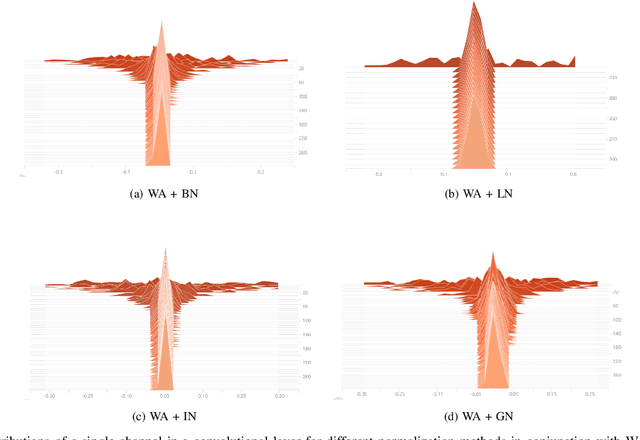
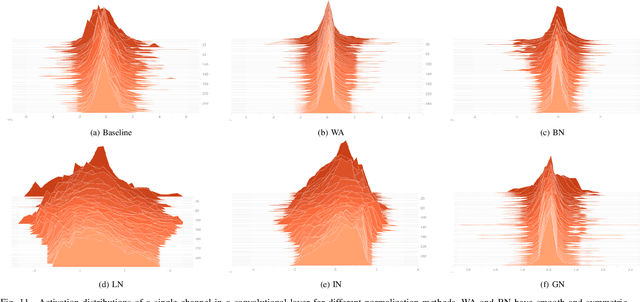

Batch normalization (BN) allows training very deep networks by normalizing activations by mini-batch sample statistics which renders BN unstable for small batch sizes. Current small-batch solutions such as Instance Norm, Layer Norm, and Group Norm use channel statistics which can be computed even for a single sample. Such methods are less stable than BN as they critically depend on the statistics of a single input sample. To address this problem, we propose a normalization of activation without sample statistics. We present WeightAlign: a method that normalizes the weights by the mean and scaled standard derivation computed within a filter, which normalizes activations without computing any sample statistics. Our proposed method is independent of batch size and stable over a wide range of batch sizes. Because weight statistics are orthogonal to sample statistics, we can directly combine WeightAlign with any method for activation normalization. We experimentally demonstrate these benefits for classification on CIFAR-10, CIFAR-100, ImageNet, for semantic segmentation on PASCAL VOC 2012 and for domain adaptation on Office-31.
Deep Visual City Recognition Visualization
May 06, 2019

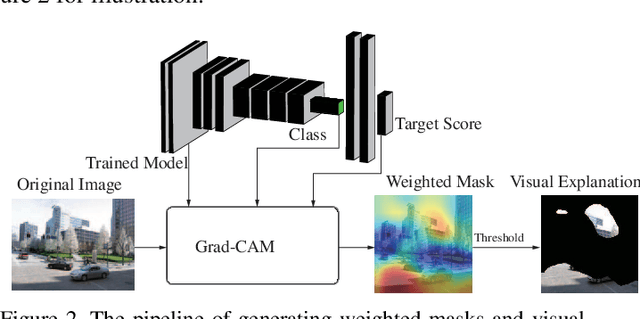
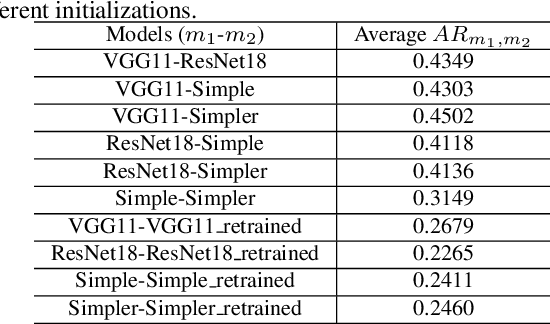
Understanding how cities visually differ from each others is interesting for planners, residents, and historians. We investigate the interpretation of deep features learned by convolutional neural networks (CNNs) for city recognition. Given a trained city recognition network, we first generate weighted masks using the known Grad-CAM technique and to select the most discriminate regions in the image. Since the image classification label is the city name, it contains no information of objects that are class-discriminate, we investigate the interpretability of deep representations with two methods. (i) Unsupervised method is used to cluster the objects appearing in the visual explanations. (ii) A pretrained semantic segmentation model is used to label objects in pixel level, and then we introduce statistical measures to quantitatively evaluate the interpretability of discriminate objects. The influence of network architectures and random initializations in training, is studied on the interpretability of CNN features for city recognition. The results suggest that network architectures would affect the interpretability of learned visual representations greater than different initializations.