 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom-CAM: Generating Fine-grained Pixel Annotations from Image Labels
Paper and Code
Oct 16, 2020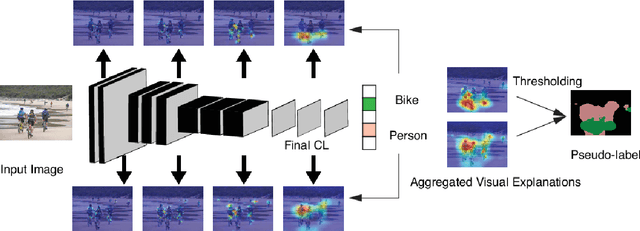
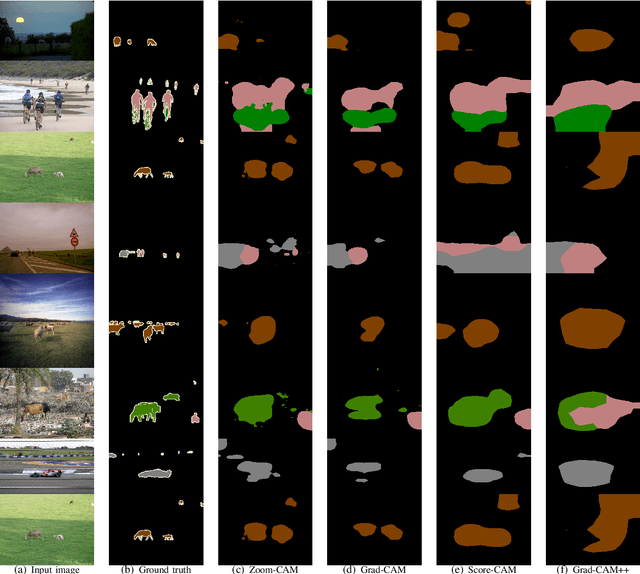
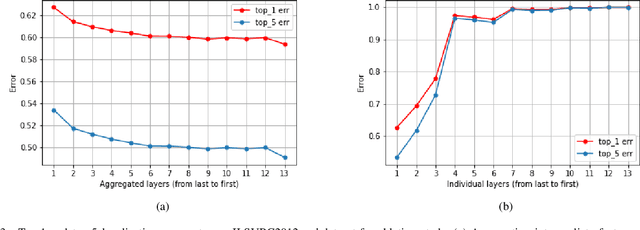

Current weakly supervised object localization and segmentation rely on class-discriminative visualization techniques to generate pseudo-labels for pixel-level training. Such visualization methods, including class activation mapping (CAM) and Grad-CAM, use only the deepest, lowest resolution convolutional layer, missing all information in intermediate layers. We propose Zoom-CAM: going beyond the last lowest resolution layer by integrating the importance maps over all activations in intermediate layers. Zoom-CAM captures fine-grained small-scale objects for various discriminative class instances, which are commonly missed by the baseline visualization methods. We focus on generating pixel-level pseudo-labels from class labels. The quality of our pseudo-labels evaluated on the ImageNet localization task exhibits more than 2.8% improvement on top-1 error. For weakly supervised semantic segmentation our generated pseudo-labels improve a state of the art model by 1.1%.