 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutGKN: Graph Similarity Learning of Floor Plans
Sep 03, 2025Floor plans depict building layouts and are often represented as graphs to capture the underlying spatial relationships. Comparison of these graphs is critical for applications like search, clustering, and data visualization. The most successful methods to compare graphs \ie, graph matching networks, rely on costly intermediate cross-graph node-level interactions, therefore being slow in inference time. We introduce \textbf{LayoutGKN}, a more efficient approach that postpones the cross-graph node-level interactions to the end of the joint embedding architecture. We do so by using a differentiable graph kernel as a distance function on the final learned node-level embeddings. We show that LayoutGKN computes similarity comparably or better than graph matching networks while significantly increasing the speed. \href{https://github.com/caspervanengelenburg/LayoutGKN}{Code and data} are open.
MSD: A Benchmark Dataset for Floor Plan Generation of Building Complexes
Jul 14, 2024



Diverse and realistic floor plan data are essential for the development of useful computer-aided methods in architectural design. Today's large-scale floor plan datasets predominantly feature simple floor plan layouts, typically representing single-apartment dwellings only. To compensate for the mismatch between current datasets and the real world, we develop \textbf{Modified Swiss Dwellings} (MSD) -- the first large-scale floor plan dataset that contains a significant share of layouts of multi-apartment dwellings. MSD features over 5.3K floor plans of medium- to large-scale building complexes, covering over 18.9K distinct apartments. We validate that existing approaches for floor plan generation, while effective in simpler scenarios, cannot yet seamlessly address the challenges posed by MSD. Our benchmark calls for new research in floor plan machine understanding. Code and data are open.
SSIG: A Visually-Guided Graph Edit Distance for Floor Plan Similarity
Sep 08, 2023We propose a simple yet effective metric that measures structural similarity between visual instances of architectural floor plans, without the need for learning. Qualitatively, our experiments show that the retrieval results are similar to deeply learned methods. Effectively comparing instances of floor plan data is paramount to the success of machine understanding of floor plan data, including the assessment of floor plan generative models and floor plan recommendation systems. Comparing visual floor plan images goes beyond a sole pixel-wise visual examination and is crucially about similarities and differences in the shapes and relations between subdivisions that compose the layout. Currently, deep metric learning approaches are used to learn a pair-wise vector representation space that closely mimics the structural similarity, in which the models are trained on similarity labels that are obtained by Intersection-over-Union (IoU). To compensate for the lack of structural awareness in IoU, graph-based approaches such as Graph Matching Networks (GMNs) are used, which require pairwise inference for comparing data instances, making GMNs less practical for retrieval applications. In this paper, an effective evaluation metric for judging the structural similarity of floor plans, coined SSIG (Structural Similarity by IoU and GED), is proposed based on both image and graph distances. In addition, an efficient algorithm is developed that uses SSIG to rank a large-scale floor plan database. Code will be openly available.
AmsterTime: A Visual Place Recognition Benchmark Dataset for Severe Domain Shift
Mar 30, 2022
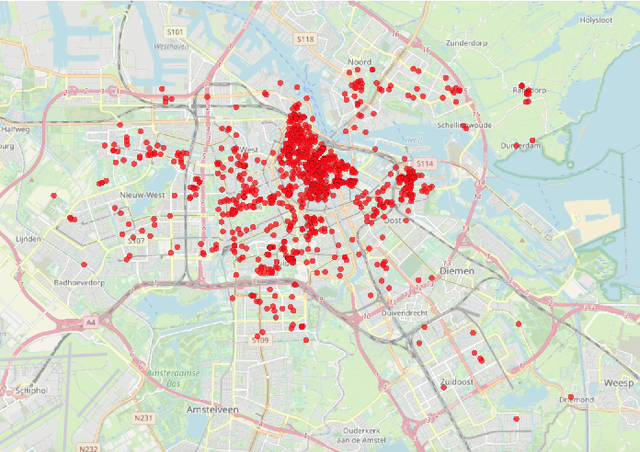

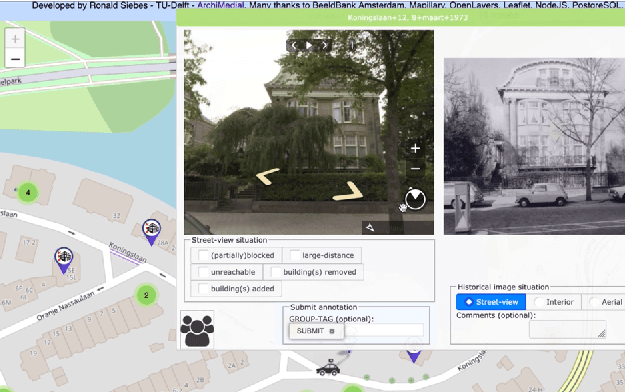
We introduce AmsterTime: a challenging dataset to benchmark visual place recognition (VPR) in presence of a severe domain shift. AmsterTime offers a collection of 2,500 well-curated images matching the same scene from a street view matched to historical archival image data from Amsterdam city. The image pairs capture the same place with different cameras, viewpoints, and appearances. Unlike existing benchmark datasets, AmsterTime is directly crowdsourced in a GIS navigation platform (Mapillary). We evaluate various baselines, including non-learning, supervised and self-supervised methods, pre-trained on different relevant datasets, for both verification and retrieval tasks. Our result credits the best accuracy to the ResNet-101 model pre-trained on the Landmarks dataset for both verification and retrieval tasks by 84% and 24%, respectively. Additionally, a subset of Amsterdam landmarks is collected for feature evaluation in a classification task. Classification labels are further used to extract the visual explanations using Grad-CAM for inspection of the learned similar visuals in a deep metric learning models.
Reconstructing Compact Building Models from Point Clouds Using Deep Implicit Fields
Jan 09, 2022
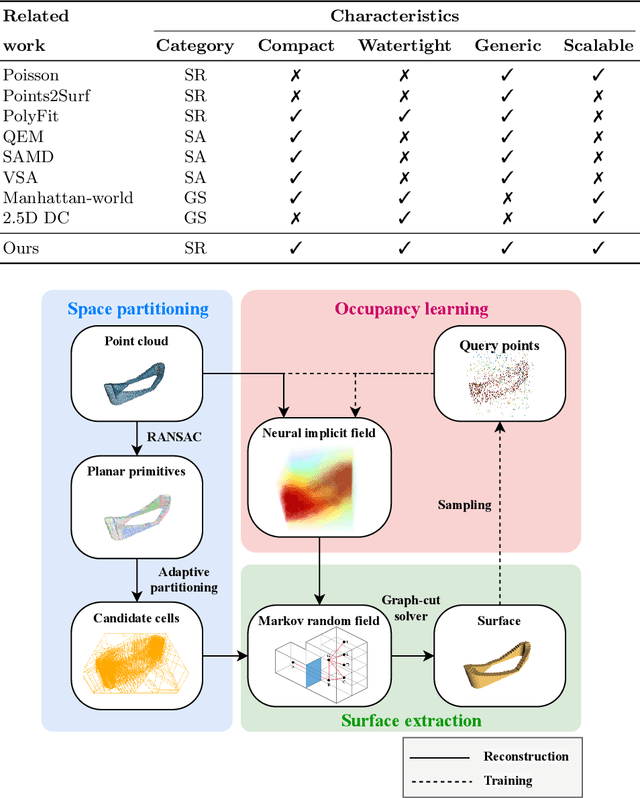

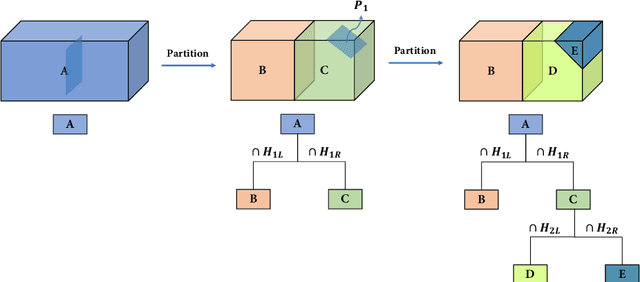
Three-dimensional (3D) building models play an increasingly pivotal role in many real-world applications while obtaining a compact representation of buildings remains an open problem. In this paper, we present a novel framework for reconstructing compact, watertight, polygonal building models from point clouds. Our framework comprises three components: (a) a cell complex is generated via adaptive space partitioning that provides a polyhedral embedding as the candidate set; (b) an implicit field is learned by a deep neural network that facilitates building occupancy estimation; (c) a Markov random field is formulated to extract the outer surface of a building via combinatorial optimization. We evaluate and compare our method with state-of-the-art methods in shape reconstruction, surface approximation, and geometry simplification. Experiments on both synthetic and real-world point clouds have demonstrated that, with our neural-guided strategy, high-quality building models can be obtained with significant advantages in fidelity, compactness, and computational efficiency. Our method shows robustness to noise and insufficient measurements, and it can directly generalize from synthetic scans to real-world measurements. The source code of this work is freely available at https://github.com/chenzhaiyu/points2poly.
Zoom-CAM: Generating Fine-grained Pixel Annotations from Image Labels
Oct 16, 2020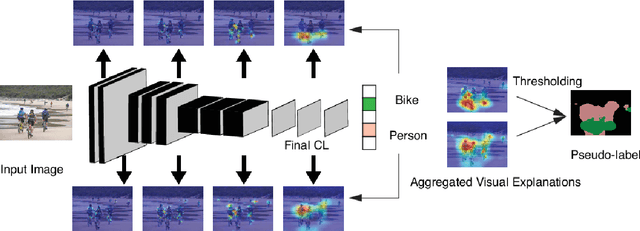
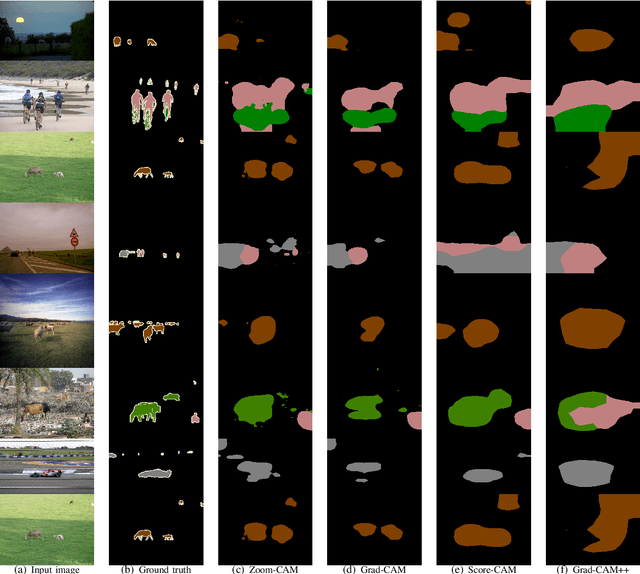
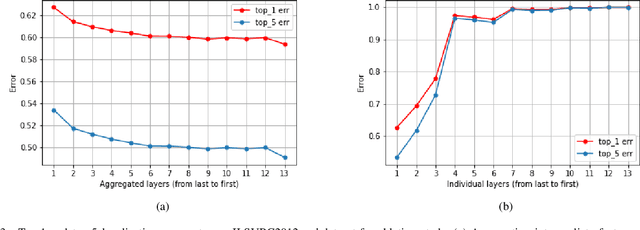

Current weakly supervised object localization and segmentation rely on class-discriminative visualization techniques to generate pseudo-labels for pixel-level training. Such visualization methods, including class activation mapping (CAM) and Grad-CAM, use only the deepest, lowest resolution convolutional layer, missing all information in intermediate layers. We propose Zoom-CAM: going beyond the last lowest resolution layer by integrating the importance maps over all activations in intermediate layers. Zoom-CAM captures fine-grained small-scale objects for various discriminative class instances, which are commonly missed by the baseline visualization methods. We focus on generating pixel-level pseudo-labels from class labels. The quality of our pseudo-labels evaluated on the ImageNet localization task exhibits more than 2.8% improvement on top-1 error. For weakly supervised semantic segmentation our generated pseudo-labels improve a state of the art model by 1.1%.
Attention-Aware Age-Agnostic Visual Place Recognition
Sep 11, 2019
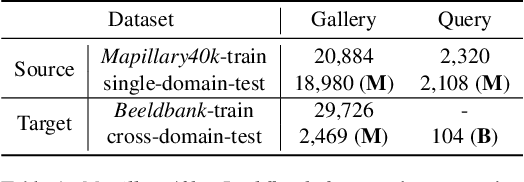
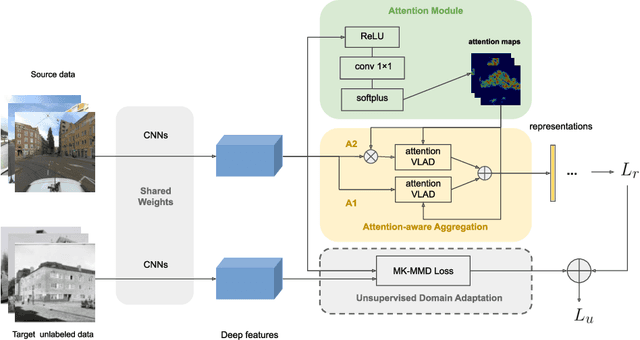
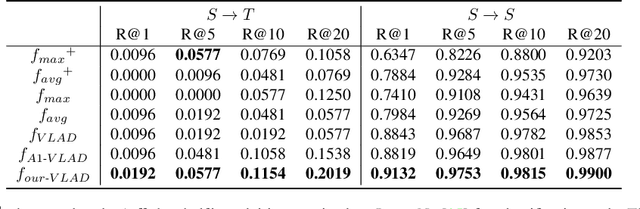
A cross-domain visual place recognition (VPR) task is proposed in this work, i.e., matching images of the same architectures depicted in different domains. VPR is commonly treated as an image retrieval task, where a query image from an unknown location is matched with relevant instances from geo-tagged gallery database. Different from conventional VPR settings where the query images and gallery images come from the same domain, we propose a more common but challenging setup where the query images are collected under a new unseen condition. The two domains involved in this work are contemporary street view images of Amsterdam from the Mapillary dataset (source domain) and historical images of the same city from Beeldbank dataset (target domain). We tailored an age-invariant feature learning CNN that can focus on domain invariant objects and learn to match images based on a weakly supervised ranking loss. We propose an attention aggregation module that is robust to domain discrepancy between the train and the test data. Further, a multi-kernel maximum mean discrepancy (MK-MMD) domain adaptation loss is adopted to improve the cross-domain ranking performance. Both attention and adaptation modules are unsupervised while the ranking loss uses weak supervision. Visual inspection shows that the attention module focuses on built forms while the dramatically changing environment are less weighed. Our proposed CNN achieves state of the art results (99% accuracy) on the single-domain VPR task and 20% accuracy at its best on the cross-domain VPR task, revealing the difficulty of age-invariant VPR.
Cross Domain Image Matching in Presence of Outliers
Sep 08, 2019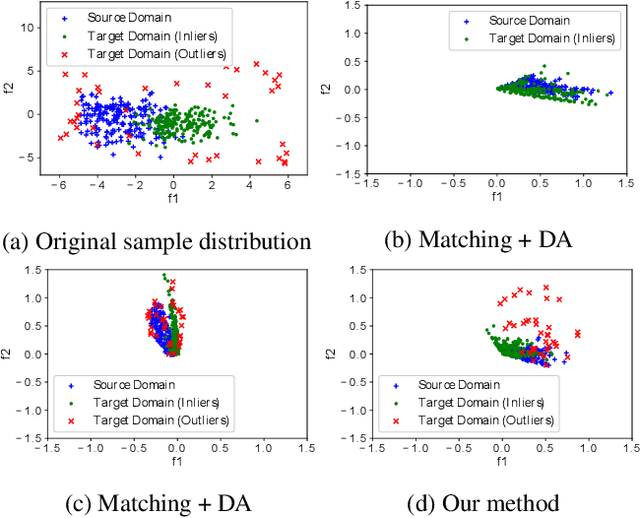

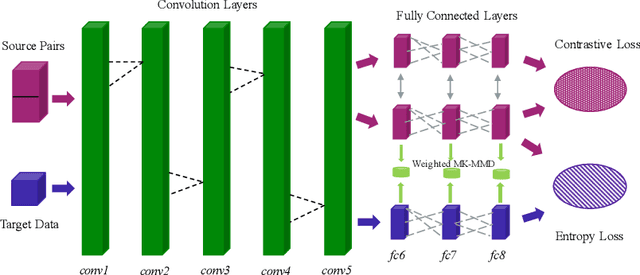

Cross domain image matching between image collections from different source and target domains is challenging in times of deep learning due to i) limited variation of image conditions in a training set, ii) lack of paired-image labels during training, iii) the existing of outliers that makes image matching domains not fully overlap. To this end, we propose an end-to-end architecture that can match cross domain images without labels in the target domain and handle non-overlapping domains by outlier detection. We leverage domain adaptation and triplet constraints for training a network capable of learning domain invariant and identity distinguishable representations, and iteratively detecting the outliers with an entropy loss and our proposed weighted MK-MMD. Extensive experimental evidence on Office [17] dataset and our proposed datasets Shape, Pitts-CycleGAN shows that the proposed approach yields state-of-the-art cross domain image matching and outlier detection performance on different benchmarks. The code will be made publicly available.
Deep Visual City Recognition Visualization
May 06, 2019

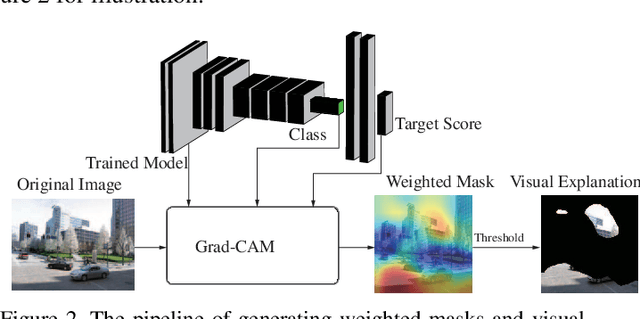
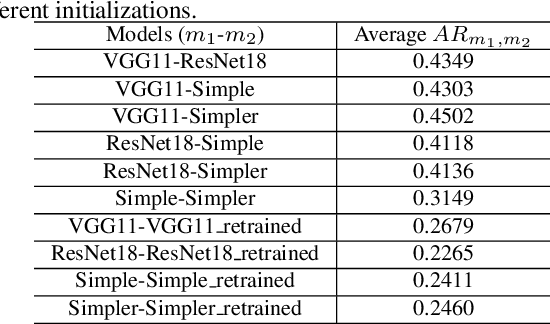
Understanding how cities visually differ from each others is interesting for planners, residents, and historians. We investigate the interpretation of deep features learned by convolutional neural networks (CNNs) for city recognition. Given a trained city recognition network, we first generate weighted masks using the known Grad-CAM technique and to select the most discriminate regions in the image. Since the image classification label is the city name, it contains no information of objects that are class-discriminate, we investigate the interpretability of deep representations with two methods. (i) Unsupervised method is used to cluster the objects appearing in the visual explanations. (ii) A pretrained semantic segmentation model is used to label objects in pixel level, and then we introduce statistical measures to quantitatively evaluate the interpretability of discriminate objects. The influence of network architectures and random initializations in training, is studied on the interpretability of CNN features for city recognition. The results suggest that network architectures would affect the interpretability of learned visual representations greater than different initializations.