 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Visual City Recognition Visualization
Paper and Code


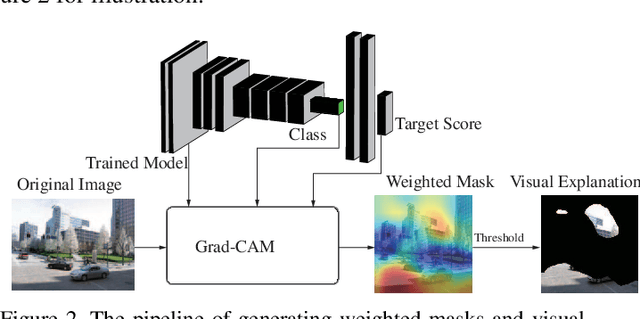
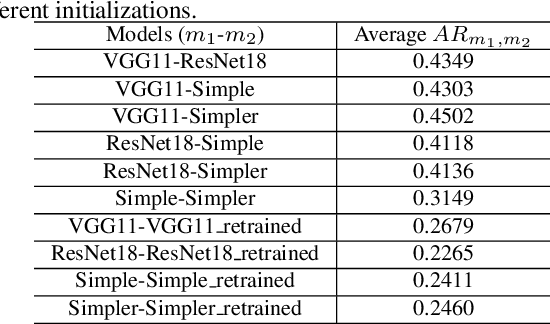
Understanding how cities visually differ from each others is interesting for planners, residents, and historians. We investigate the interpretation of deep features learned by convolutional neural networks (CNNs) for city recognition. Given a trained city recognition network, we first generate weighted masks using the known Grad-CAM technique and to select the most discriminate regions in the image. Since the image classification label is the city name, it contains no information of objects that are class-discriminate, we investigate the interpretability of deep representations with two methods. (i) Unsupervised method is used to cluster the objects appearing in the visual explanations. (ii) A pretrained semantic segmentation model is used to label objects in pixel level, and then we introduce statistical measures to quantitatively evaluate the interpretability of discriminate objects. The influence of network architectures and random initializations in training, is studied on the interpretability of CNN features for city recognition. The results suggest that network architectures would affect the interpretability of learned visual representations greater than different initializations.