 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Automatic Facial Micro-expression Analysis: Databases, Methods and Challenges
Jun 15, 2018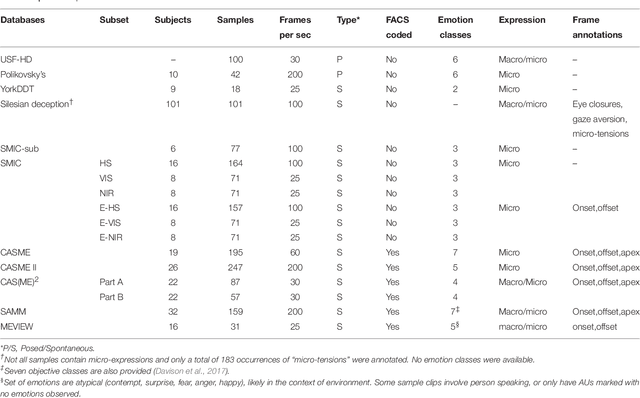


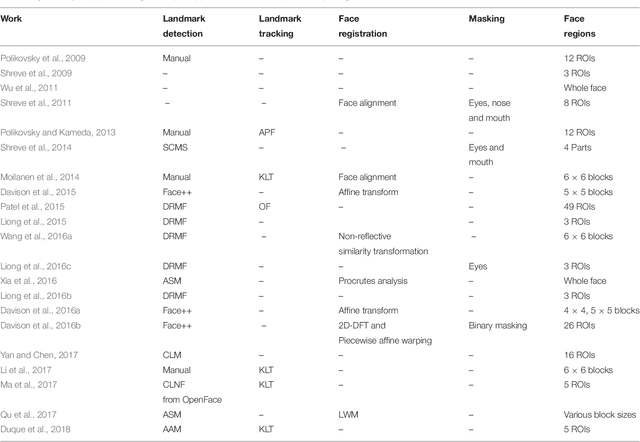
Over the last few years, automatic facial micro-expression analysis has garnered increasing attention from experts across different disciplines because of its potential applications in various fields such as clinical diagnosis, forensic investigation and security systems. Advances in computer algorithms and video acquisition technology have rendered machine analysis of facial micro-expressions possible today, in contrast to decades ago when it was primarily the domain of psychiatrists where analysis was largely manual. Indeed, although the study of facial micro-expressions is a well-established field in psychology, it is still relatively new from the computational perspective with many interesting problems. In this survey, we present a comprehensive review of state-of-the-art databases and methods for micro-expressions spotting and recognition. Individual stages involved in the automation of these tasks are also described and reviewed at length. In addition, we also deliberate on the challenges and future directions in this growing field of automatic facial micro-expression analysis.
Spontaneous Subtle Expression Detection and Recognition based on Facial Strain
Jun 09, 2016
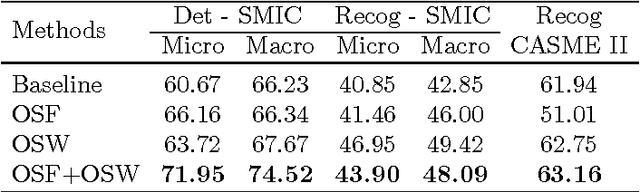
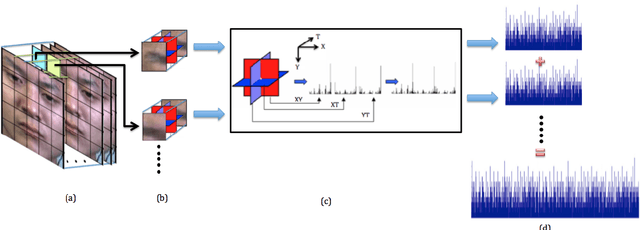
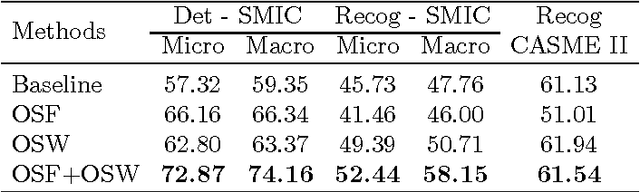
Optical strain is an extension of optical flow that is capable of quantifying subtle changes on faces and representing the minute facial motion intensities at the pixel level. This is computationally essential for the relatively new field of spontaneous micro-expression, where subtle expressions can be technically challenging to pinpoint. In this paper, we present a novel method for detecting and recognizing micro-expressions by utilizing facial optical strain magnitudes to construct optical strain features and optical strain weighted features. The two sets of features are then concatenated to form the resultant feature histogram. Experiments were performed on the CASME II and SMIC databases. We demonstrate on both databases, the usefulness of optical strain information and more importantly, that our best approaches are able to outperform the original baseline results for both detection and recognition tasks. A comparison of the proposed method with other existing spatio-temporal feature extraction approaches is also presented.
* 21 pages (including references), single column format, accepted to Signal Processing: Image Communication journal
Sparsity in Dynamics of Spontaneous Subtle Emotions: Analysis \& Application
Feb 11, 2016



Spontaneous subtle emotions are expressed through micro-expressions, which are tiny, sudden and short-lived dynamics of facial muscles; thus poses a great challenge for visual recognition. The abrupt but significant dynamics for the recognition task are temporally sparse while the rest, irrelevant dynamics, are temporally redundant. In this work, we analyze and enforce sparsity constrains to learn significant temporal and spectral structures while eliminate irrelevant facial dynamics of micro-expressions, which would ease the challenge in the visual recognition of spontaneous subtle emotions. The hypothesis is confirmed through experimental results of automatic spontaneous subtle emotion recognition with several sparsity levels on CASME II and SMIC, the only two publicly available spontaneous subtle emotion databases. The overall performances of the automatic subtle emotion recognition are boosted when only significant dynamics are preserved from the original sequences.
Multi-scale Discriminant Saliency with Wavelet-based Hidden Markov Tree Modelling
Jun 06, 2013



The bottom-up saliency, an early stage of humans' visual attention, can be considered as a binary classification problem between centre and surround classes. Discriminant power of features for the classification is measured as mutual information between distributions of image features and corresponding classes . As the estimated discrepancy very much depends on considered scale level, multi-scale structure and discriminant power are integrated by employing discrete wavelet features and Hidden Markov Tree (HMT). With wavelet coefficients and Hidden Markov Tree parameters, quad-tree like label structures are constructed and utilized in maximum a posterior probability (MAP) of hidden class variables at corresponding dyadic sub-squares. Then, a saliency value for each square block at each scale level is computed with discriminant power principle. Finally, across multiple scales is integrated the final saliency map by an information maximization rule. Both standard quantitative tools such as NSS, LCC, AUC and qualitative assessments are used for evaluating the proposed multi-scale discriminant saliency (MDIS) method against the well-know information based approach AIM on its released image collection with eye-tracking data. Simulation results are presented and analysed to verify the validity of MDIS as well as point out its limitation for further research direction.
Multi-scale Visual Attention & Saliency Modelling with Decision Theory
Feb 04, 2013

Bottom-up saliency, an early human visual processing, behaves like binary classification of interest and null hypothesis. Its discriminant power, mutual information of image features and class distribution, is closely related to saliency value by the well-known centre-surround theory. As classification accuracy very much depends on window sizes, the discriminant saliency (power) varies according to sampling scales. Discriminating power estimation in multi-scales framework needs integrating with wavelet transformation and then estimating statistical discrepancy of two consecutive scales (centre-surround windows) by Hidden Markov Tree (HMT) model. Finally, multi-scale discriminant saliency (MDIS) maps are combined by the maximum information rule to synthesize a final saliency map. All MDIS maps are evaluated with standard quantitative tools (NSS,LCC,AUC) on N.Bruce's database with ground truth data as eye-tracking locations ; as well assessed qualitatively by visual examination of individual cases. For evaluating MDIS against well-known AIM saliency method, simulations are needed and described in details with several interesting conclusions, drawn for further research directions.
Fast non parametric entropy estimation for spatial-temporal saliency method
Jan 31, 2013


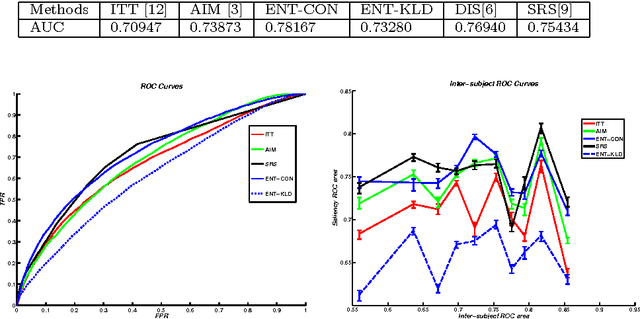
This paper formulates bottom-up visual saliency as center surround conditional entropy and presents a fast and efficient technique for the computation of such a saliency map. It is shown that the new saliency formulation is consistent with self-information based saliency, decision-theoretic saliency and Bayesian definition of surprises but also faces the same significant computational challenge of estimating probability density in very high dimensional spaces with limited samples. We have developed a fast and efficient nonparametric method to make the practical implementation of these types of saliency maps possible. By aligning pixels from the center and surround regions and treating their location coordinates as random variables, we use a k-d partitioning method to efficiently estimating the center surround conditional entropy. We present experimental results on two publicly available eye tracking still image databases and show that the new technique is competitive with state of the art bottom-up saliency computational methods. We have also extended the technique to compute spatiotemporal visual saliency of video and evaluate the bottom-up spatiotemporal saliency against eye tracking data on a video taken onboard a moving vehicle with the driver's eye being tracked by a head mounted eye-tracker.
Multiscale Discriminant Saliency for Visual Attention
Jan 17, 2013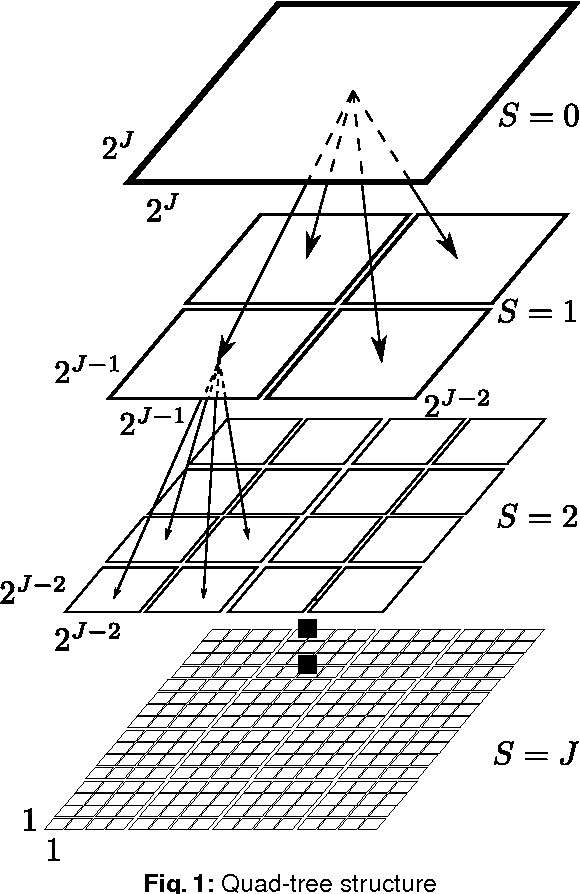


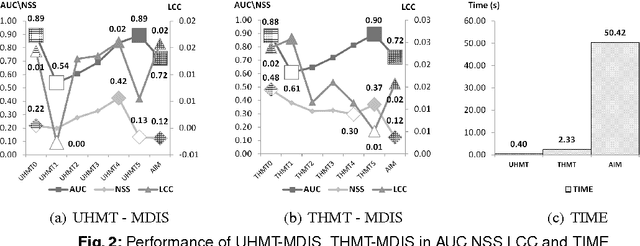
The bottom-up saliency, an early stage of humans' visual attention, can be considered as a binary classification problem between center and surround classes. Discriminant power of features for the classification is measured as mutual information between features and two classes distribution. The estimated discrepancy of two feature classes very much depends on considered scale levels; then, multi-scale structure and discriminant power are integrated by employing discrete wavelet features and Hidden markov tree (HMT). With wavelet coefficients and Hidden Markov Tree parameters, quad-tree like label structures are constructed and utilized in maximum a posterior probability (MAP) of hidden class variables at corresponding dyadic sub-squares. Then, saliency value for each dyadic square at each scale level is computed with discriminant power principle and the MAP. Finally, across multiple scales is integrated the final saliency map by an information maximization rule. Both standard quantitative tools such as NSS, LCC, AUC and qualitative assessments are used for evaluating the proposed multiscale discriminant saliency method (MDIS) against the well-know information-based saliency method AIM on its Bruce Database wity eye-tracking data. Simulation results are presented and analyzed to verify the validity of MDIS as well as point out its disadvantages for further research direction.
Wavelet-based Scale Saliency
Jan 14, 2013



Both pixel-based scale saliency (PSS) and basis project methods focus on multiscale analysis of data content and structure. Their theoretical relations and practical combination are previously discussed. However, no models have ever been proposed for calculating scale saliency on basis-projected descriptors since then. This paper extend those ideas into mathematical models and implement them in the wavelet-based scale saliency (WSS). While PSS uses pixel-value descriptors, WSS treats wavelet sub-bands as basis descriptors. The paper discusses different wavelet descriptors: discrete wavelet transform (DWT), wavelet packet transform (DWPT), quaternion wavelet transform (QWT) and best basis quaternion wavelet packet transform (QWPTBB). WSS saliency maps of different descriptors are generated and compared against other saliency methods by both quantitative and quanlitative methods. Quantitative results, ROC curves, AUC values and NSS values are collected from simulations on Bruce and Kootstra image databases with human eye-tracking data as ground-truth. Furthermore, qualitative visual results of saliency maps are analyzed and compared against each other as well as eye-tracking data inclusive in the databases.