 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexi-Fuzz least squares SVM for Alzheimer's diagnosis: Tackling noise, outliers, and class imbalance
Oct 18, 2024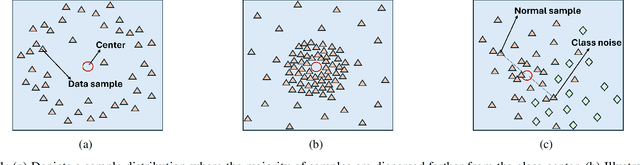


Alzheimer's disease (AD) is a leading neurodegenerative condition and the primary cause of dementia, characterized by progressive cognitive decline and memory loss. Its progression, marked by shrinkage in the cerebral cortex, is irreversible. Numerous machine learning algorithms have been proposed for the early diagnosis of AD. However, they often struggle with the issues of noise, outliers, and class imbalance. To tackle the aforementioned limitations, in this article, we introduce a novel, robust, and flexible membership scheme called Flexi-Fuzz. This scheme integrates a novel flexible weighting mechanism, class probability, and imbalance ratio. The proposed flexible weighting mechanism assigns the maximum weight to samples within a specific proximity to the center, with a gradual decrease in weight beyond a certain threshold. This approach ensures that samples near the class boundary still receive significant weight, maintaining their influence in the classification process. Class probability is used to mitigate the impact of noisy samples, while the imbalance ratio addresses class imbalance. Leveraging this, we incorporate the proposed Flexi-Fuzz membership scheme into the least squares support vector machines (LSSVM) framework, resulting in a robust and flexible model termed Flexi-Fuzz-LSSVM. We determine the class-center using two methods: the conventional mean approach and an innovative median approach, leading to two model variants, Flexi-Fuzz-LSSVM-I and Flexi-Fuzz-LSSVM-II. To validate the effectiveness of the proposed Flexi-Fuzz-LSSVM models, we evaluated them on benchmark UCI and KEEL datasets, both with and without label noise. Additionally, we tested the models on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset for AD diagnosis. Experimental results demonstrate the superiority of the Flexi-Fuzz-LSSVM models over baseline models.
Advancing RVFL networks: Robust classification with the HawkEye loss function
Oct 01, 2024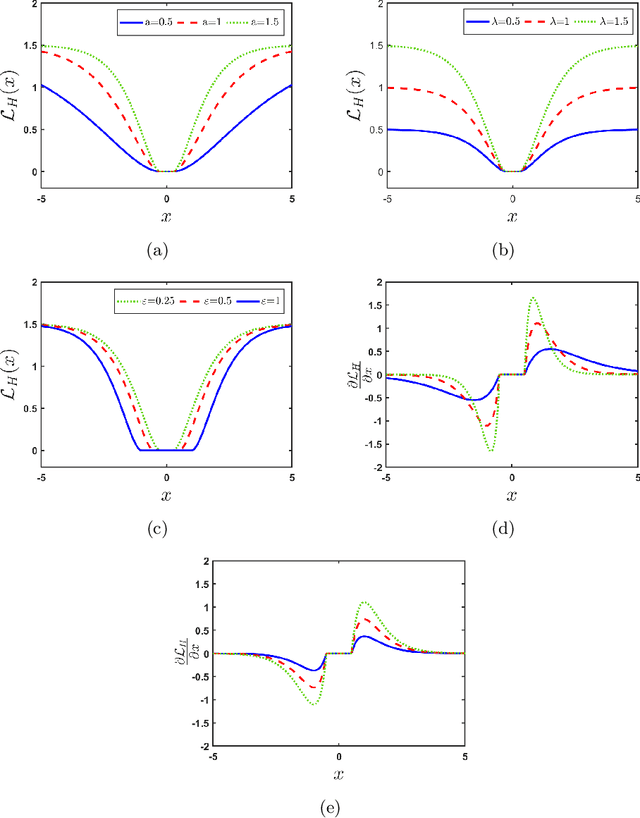

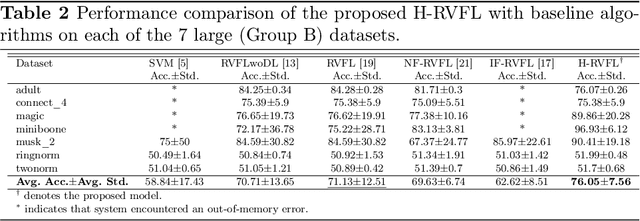
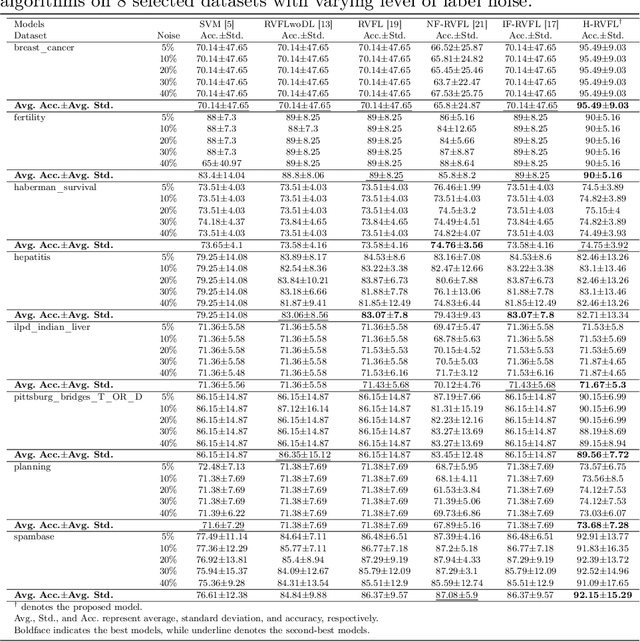
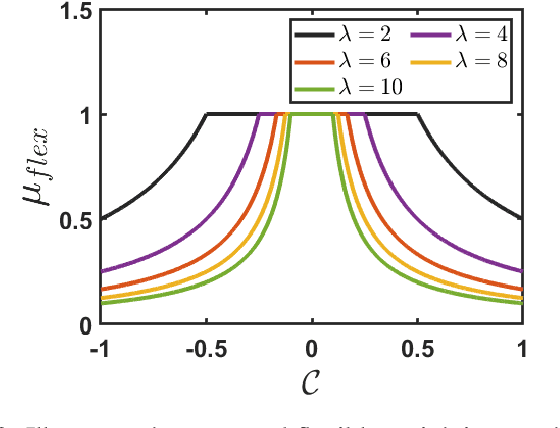
Random vector functional link (RVFL), a variant of single-layer feedforward neural network (SLFN), has garnered significant attention due to its lower computational cost and robustness to overfitting. Despite its advantages, the RVFL network's reliance on the square error loss function makes it highly sensitive to outliers and noise, leading to degraded model performance in real-world applications. To remedy it, we propose the incorporation of the HawkEye loss (H-loss) function into the RVFL framework. The H-loss function features nice mathematical properties, including smoothness and boundedness, while simultaneously incorporating an insensitive zone. Each characteristic brings its own advantages: 1) Boundedness limits the impact of extreme errors, enhancing robustness against outliers; 2) Smoothness facilitates the use of gradient-based optimization algorithms, ensuring stable and efficient convergence; and 3) The insensitive zone mitigates the effect of minor discrepancies and noise. Leveraging the H-loss function, we embed it into the RVFL framework and develop a novel robust RVFL model termed H-RVFL. Notably, this work addresses a significant gap, as no bounded loss function has been incorporated into RVFL to date. The non-convex optimization of the proposed H-RVFL is effectively addressed by the Nesterov accelerated gradient (NAG) algorithm, whose computational complexity is also discussed. The proposed H-RVFL model's effectiveness is validated through extensive experiments on $40$ benchmark datasets from UCI and KEEL repositories, with and without label noise. The results highlight significant improvements in robustness and efficiency, establishing the H-RVFL model as a powerful tool for applications in noisy and outlier-prone environments.
GL-TSVM: A robust and smooth twin support vector machine with guardian loss function
Aug 29, 2024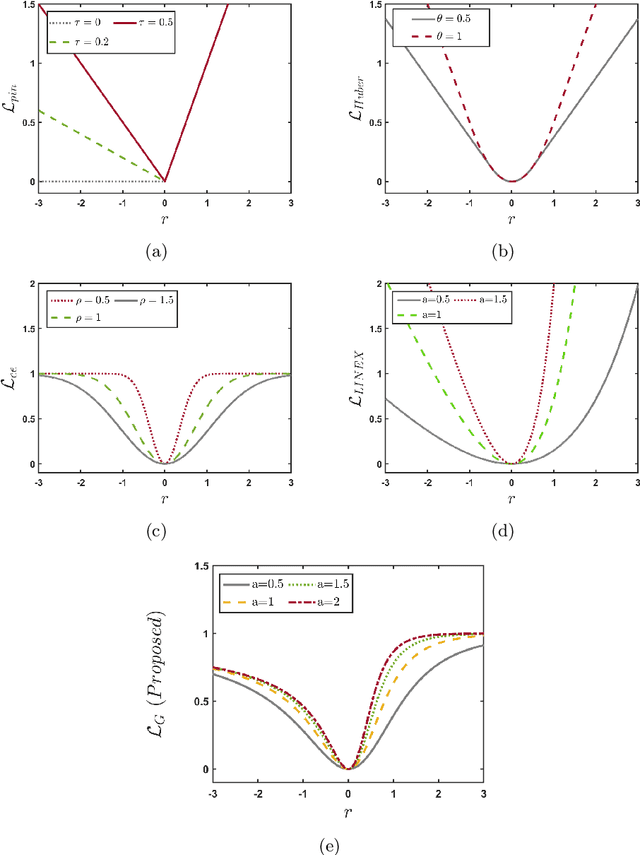
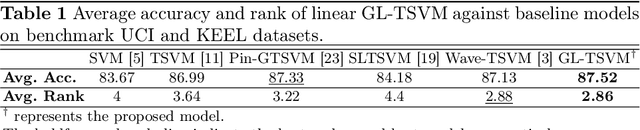
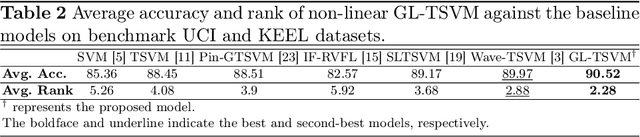

Twin support vector machine (TSVM), a variant of support vector machine (SVM), has garnered significant attention due to its $3/4$ times lower computational complexity compared to SVM. However, due to the utilization of the hinge loss function, TSVM is sensitive to outliers or noise. To remedy it, we introduce the guardian loss (G-loss), a novel loss function distinguished by its asymmetric, bounded, and smooth characteristics. We then fuse the proposed G-loss function into the TSVM and yield a robust and smooth classifier termed GL-TSVM. Further, to adhere to the structural risk minimization (SRM) principle and reduce overfitting, we incorporate a regularization term into the objective function of GL-TSVM. To address the optimization challenges of GL-TSVM, we devise an efficient iterative algorithm. The experimental analysis on UCI and KEEL datasets substantiates the effectiveness of the proposed GL-TSVM in comparison to the baseline models. Moreover, to showcase the efficacy of the proposed GL-TSVM in the biomedical domain, we evaluated it on the breast cancer (BreaKHis) and schizophrenia datasets. The outcomes strongly demonstrate the competitiveness of the proposed GL-TSVM against the baseline models.
Advancing Supervised Learning with the Wave Loss Function: A Robust and Smooth Approach
Apr 28, 2024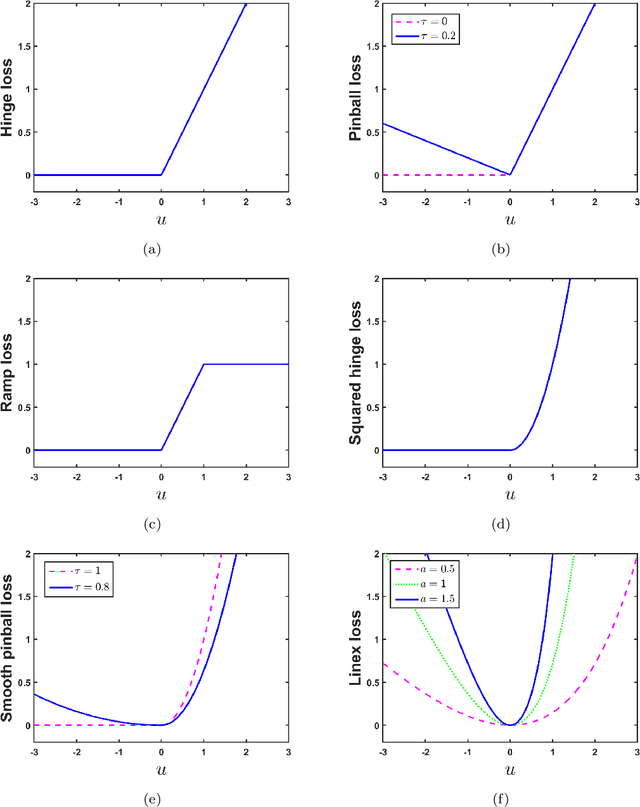

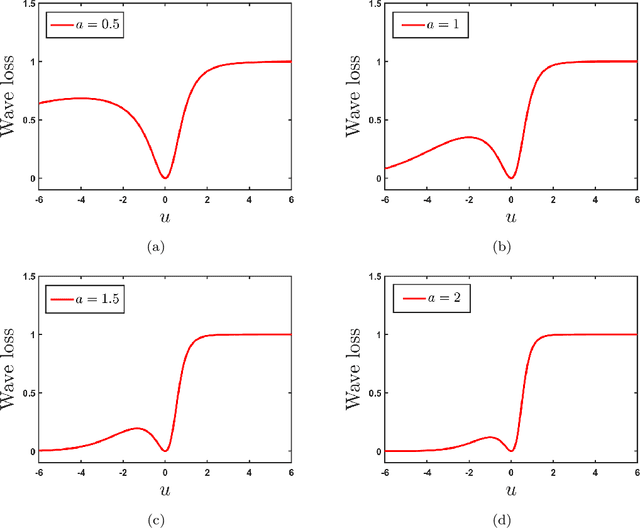

Loss function plays a vital role in supervised learning frameworks. The selection of the appropriate loss function holds the potential to have a substantial impact on the proficiency attained by the acquired model. The training of supervised learning algorithms inherently adheres to predetermined loss functions during the optimization process. In this paper, we present a novel contribution to the realm of supervised machine learning: an asymmetric loss function named wave loss. It exhibits robustness against outliers, insensitivity to noise, boundedness, and a crucial smoothness property. Theoretically, we establish that the proposed wave loss function manifests the essential characteristic of being classification-calibrated. Leveraging this breakthrough, we incorporate the proposed wave loss function into the least squares setting of support vector machines (SVM) and twin support vector machines (TSVM), resulting in two robust and smooth models termed Wave-SVM and Wave-TSVM, respectively. To address the optimization problem inherent in Wave-SVM, we utilize the adaptive moment estimation (Adam) algorithm. It is noteworthy that this paper marks the first instance of the Adam algorithm application to solve an SVM model. Further, we devise an iterative algorithm to solve the optimization problems of Wave-TSVM. To empirically showcase the effectiveness of the proposed Wave-SVM and Wave-TSVM, we evaluate them on benchmark UCI and KEEL datasets (with and without feature noise) from diverse domains. Moreover, to exemplify the applicability of Wave-SVM in the biomedical domain, we evaluate it on the Alzheimer Disease Neuroimaging Initiative (ADNI) dataset. The experimental outcomes unequivocally reveal the prowess of Wave-SVM and Wave-TSVM in achieving superior prediction accuracy against the baseline models.
Enhancing Efficiency and Robustness in Support Vector Regression with HawkEye Loss
Jan 30, 2024



Support vector regression (SVR) has garnered significant popularity over the past two decades owing to its wide range of applications across various fields. Despite its versatility, SVR encounters challenges when confronted with outliers and noise, primarily due to the use of the $\varepsilon$-insensitive loss function. To address this limitation, SVR with bounded loss functions has emerged as an appealing alternative, offering enhanced generalization performance and robustness. Notably, recent developments focus on designing bounded loss functions with smooth characteristics, facilitating the adoption of gradient-based optimization algorithms. However, it's crucial to highlight that these bounded and smooth loss functions do not possess an insensitive zone. In this paper, we address the aforementioned constraints by introducing a novel symmetric loss function named the HawkEye loss function. It is worth noting that the HawkEye loss function stands out as the first loss function in SVR literature to be bounded, smooth, and simultaneously possess an insensitive zone. Leveraging this breakthrough, we integrate the HawkEye loss function into the least squares framework of SVR and yield a new fast and robust model termed HE-LSSVR. The optimization problem inherent to HE-LSSVR is addressed by harnessing the adaptive moment estimation (Adam) algorithm, known for its adaptive learning rate and efficacy in handling large-scale problems. To our knowledge, this is the first time Adam has been employed to solve an SVR problem. To empirically validate the proposed HE-LSSVR model, we evaluate it on UCI, synthetic, and time series datasets. The experimental outcomes unequivocally reveal the superiority of the HE-LSSVR model both in terms of its remarkable generalization performance and its efficiency in training time.
RoBoSS: A Robust, Bounded, Sparse, and Smooth Loss Function for Supervised Learning
Sep 05, 2023



In the domain of machine learning algorithms, the significance of the loss function is paramount, especially in supervised learning tasks. It serves as a fundamental pillar that profoundly influences the behavior and efficacy of supervised learning algorithms. Traditional loss functions, while widely used, often struggle to handle noisy and high-dimensional data, impede model interpretability, and lead to slow convergence during training. In this paper, we address the aforementioned constraints by proposing a novel robust, bounded, sparse, and smooth (RoBoSS) loss function for supervised learning. Further, we incorporate the RoBoSS loss function within the framework of support vector machine (SVM) and introduce a new robust algorithm named $\mathcal{L}_{rbss}$-SVM. For the theoretical analysis, the classification-calibrated property and generalization ability are also presented. These investigations are crucial for gaining deeper insights into the performance of the RoBoSS loss function in the classification tasks and its potential to generalize well to unseen data. To empirically demonstrate the effectiveness of the proposed $\mathcal{L}_{rbss}$-SVM, we evaluate it on $88$ real-world UCI and KEEL datasets from diverse domains. Additionally, to exemplify the effectiveness of the proposed $\mathcal{L}_{rbss}$-SVM within the biomedical realm, we evaluated it on two medical datasets: the electroencephalogram (EEG) signal dataset and the breast cancer (BreaKHis) dataset. The numerical results substantiate the superiority of the proposed $\mathcal{L}_{rbss}$-SVM model, both in terms of its remarkable generalization performance and its efficiency in training time.