 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient Training of LLMs with Larger Mini-batches
Paper and Code
Jul 28, 2024

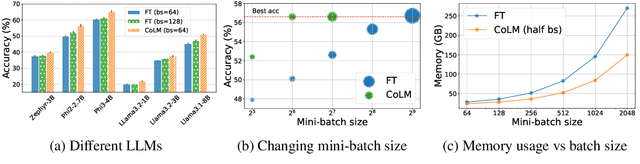

Training with larger mini-batches improves the performance and convergence rate of training machine learning models. However, training with large mini-batches becomes prohibitive for Large Language Models (LLMs) with billions of parameters, due to the large GPU memory requirement. To address this problem, we propose finding small mini-batches that simulate the dynamics of training with larger mini-batches. Specifically, we formulate selecting smaller mini-batches of examples that closely capture gradients of large mini-batches as a submodular maximization problem. Nevertheless, the very large dimensionality of the gradients makes the problem very challenging to solve. To address this, we leverage ideas from zeroth-order optimization and neural network pruning to find lower-dimensional gradient estimates that allow finding high-quality subsets effectively with a limited amount of memory. We prove the superior convergence rate of training on the small mini-batches found by our method and empirically show its effectiveness. Our method can effectively reduce the memory requirement by 2x and speed up training by 1.3x, as we confirm for fine-tuning Phi-2 on MathInstruct. Our method can be easily stacked with LoRA and other memory-efficient methods to further reduce the memory requirements of training LLMs.