 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 and Big Data: Multi-faceted Analysis for Spatio-temporal Understanding of the Pandemic with Social Media Conversations
Apr 22, 2021COVID-19 has been devastating the world since the end of 2019 and has continued to play a significant role in major national and worldwide events, and consequently, the news. In its wake, it has left no life unaffected. Having earned the world's attention, social media platforms have served as a vehicle for the global conversation about COVID-19. In particular, many people have used these sites in order to express their feelings, experiences, and observations about the pandemic. We provide a multi-faceted analysis of critical properties exhibited by these conversations on social media regarding the novel coronavirus pandemic. We present a framework for analysis, mining, and tracking the critical content and characteristics of social media conversations around the pandemic. Focusing on Twitter and Reddit, we have gathered a large-scale dataset on COVID-19 social media conversations. Our analyses cover tracking potential reports on virus acquisition, symptoms, conversation topics, and language complexity measures through time and by region across the United States. We also present a BERT-based model for recognizing instances of hateful tweets in COVID-19 conversations, which achieves a lower error-rate than the state-of-the-art performance. Our results provide empirical validation for the effectiveness of our proposed framework and further demonstrate that social media data can be efficiently leveraged to provide public health experts with inexpensive but thorough insight over the course of an outbreak.
Nutrition and Health Data for Cost-Sensitive Learning
Feb 19, 2019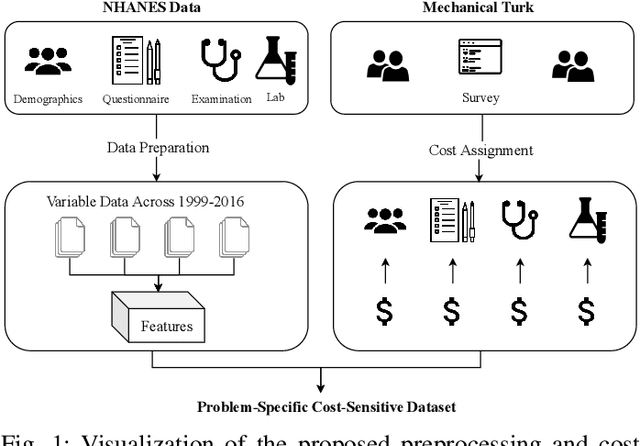



Traditionally, machine learning algorithms have been focused on modeling dynamics of a certain dataset at hand for which all features are available for free. However, there are many concerns such as monetary data collection costs, patient discomfort in medical procedures, and privacy impacts of data collection that require careful consideration in any health analytics system. An efficient solution would only acquire a subset of features based on the value it provides whilst considering acquisition costs. Moreover, datasets that provide feature costs are very limited, especially in healthcare. In this paper, we provide a health dataset as well as a method for assigning feature costs based on the total level of inconvenience asking for each feature entails. Furthermore, based on the suggested dataset, we provide a comparison of recent and state-of-the-art approaches to cost-sensitive feature acquisition and learning. Specifically, we analyze the performance of major sensitivity-based and reinforcement learning based methods in the literature on three different problems in the health domain, including diabetes, heart disease, and hypertension classification.