 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Focused Feature Selection Using a Bayesian Approach
Sep 15, 2019

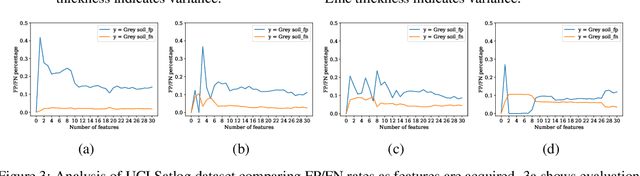
In many real-world scenarios where data is high dimensional, test time acquisition of features is a non-trivial task due to costs associated with feature acquisition and evaluating feature value. The need for highly confident models with an extremely frugal acquisition of features can be addressed by allowing a feature selection method to become target aware. We introduce an approach to feature selection that is based on Bayesian learning, allowing us to report target-specific levels of uncertainty, false positive, and false negative rates. In addition, measuring uncertainty lifts the restriction on feature selection being target agnostic, allowing for feature acquisition based on a single target of focus out of many. We show that acquiring features for a specific target is at least as good as common linear feature selection approaches for small non-sparse datasets, and surpasses these when faced with real-world healthcare data that is larger in scale and in sparseness.
Generative Imputation and Stochastic Prediction
May 22, 2019
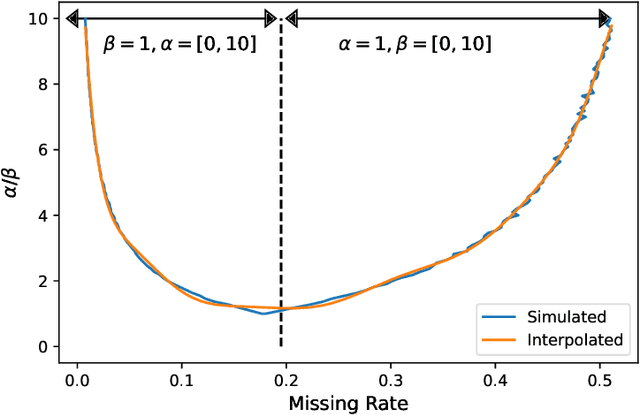
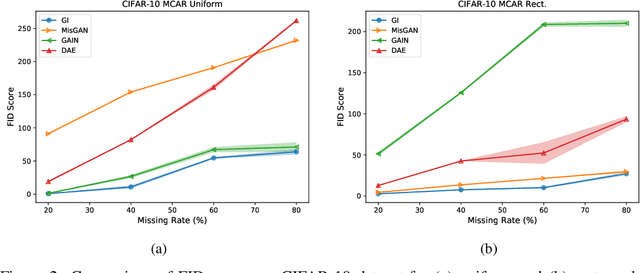
In many machine learning applications, we are faced with incomplete datasets. In the literature, missing data imputation techniques have been mostly concerned with filling missing values. However, the existence of missing values is synonymous with uncertainties not only over the distribution of missing values but also over target class assignments that require careful consideration. The objectives of this paper are twofold. First, we proposed a method for generating imputations from the conditional distribution of missing values given observed values. Second, we use the generated samples to estimate the distribution of target assignments given incomplete data. In order to generate imputations, we train a simple and effective generator network to generate imputations that a discriminator network is tasked to distinguish. Following this, a predictor network is trained using imputed samples from the generator network to capture the classification uncertainties and make predictions accordingly. The proposed method is evaluated on CIFAR-10 image dataset as well as two real-world tabular classification datasets, under various missingness rates and structures. Our experimental results show the effectiveness of the proposed method in generating imputations, as well as providing estimates for the class uncertainties in a classification task when faced with missing values.
Nutrition and Health Data for Cost-Sensitive Learning
Feb 19, 2019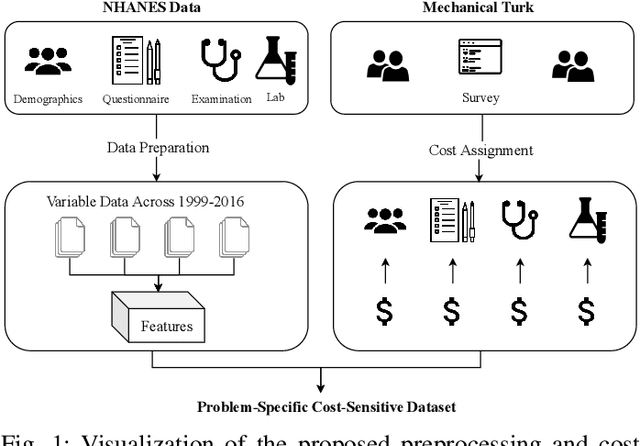



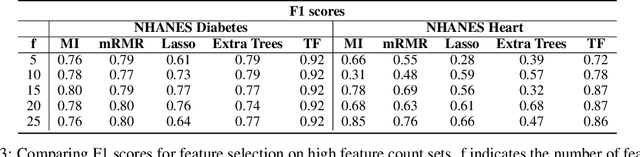
Traditionally, machine learning algorithms have been focused on modeling dynamics of a certain dataset at hand for which all features are available for free. However, there are many concerns such as monetary data collection costs, patient discomfort in medical procedures, and privacy impacts of data collection that require careful consideration in any health analytics system. An efficient solution would only acquire a subset of features based on the value it provides whilst considering acquisition costs. Moreover, datasets that provide feature costs are very limited, especially in healthcare. In this paper, we provide a health dataset as well as a method for assigning feature costs based on the total level of inconvenience asking for each feature entails. Furthermore, based on the suggested dataset, we provide a comparison of recent and state-of-the-art approaches to cost-sensitive feature acquisition and learning. Specifically, we analyze the performance of major sensitivity-based and reinforcement learning based methods in the literature on three different problems in the health domain, including diabetes, heart disease, and hypertension classification.
Opportunistic Learning: Budgeted Cost-Sensitive Learning from Data Streams
Jan 02, 2019

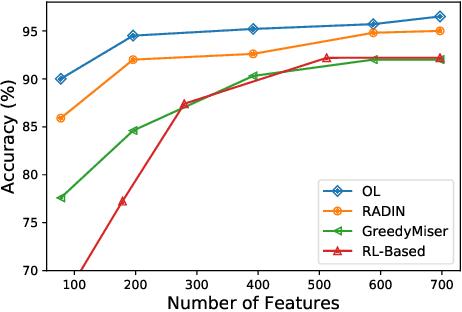

In many real-world learning scenarios, features are only acquirable at a cost constrained under a budget. In this paper, we propose a novel approach for cost-sensitive feature acquisition at the prediction-time. The suggested method acquires features incrementally based on a context-aware feature-value function. We formulate the problem in the reinforcement learning paradigm, and introduce a reward function based on the utility of each feature. Specifically, MC dropout sampling is used to measure expected variations of the model uncertainty which is used as a feature-value function. Furthermore, we suggest sharing representations between the class predictor and value function estimator networks. The suggested approach is completely online and is readily applicable to stream learning setups. The solution is evaluated on three different datasets including the well-known MNIST dataset as a benchmark as well as two cost-sensitive datasets: Yahoo Learning to Rank and a dataset in the medical domain for diabetes classification. According to the results, the proposed method is able to efficiently acquire features and make accurate predictions.
* https://openreview.net/forum?id=S1eOHo09KX