 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Focused Feature Selection Using a Bayesian Approach
Paper and Code
Sep 15, 2019

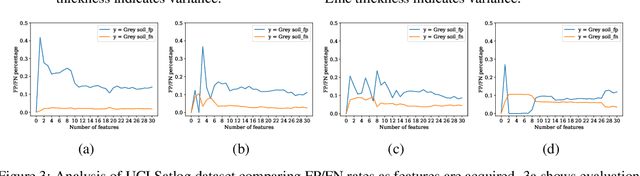
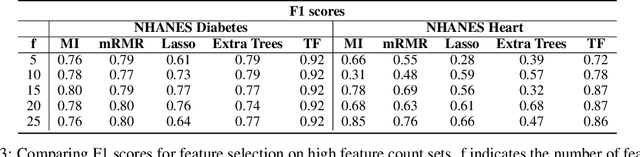
In many real-world scenarios where data is high dimensional, test time acquisition of features is a non-trivial task due to costs associated with feature acquisition and evaluating feature value. The need for highly confident models with an extremely frugal acquisition of features can be addressed by allowing a feature selection method to become target aware. We introduce an approach to feature selection that is based on Bayesian learning, allowing us to report target-specific levels of uncertainty, false positive, and false negative rates. In addition, measuring uncertainty lifts the restriction on feature selection being target agnostic, allowing for feature acquisition based on a single target of focus out of many. We show that acquiring features for a specific target is at least as good as common linear feature selection approaches for small non-sparse datasets, and surpasses these when faced with real-world healthcare data that is larger in scale and in sparseness.