 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Boosting Low-Resource Event Extraction by Structure-to-Text Data Generation with Large Language Models
Paper and Code
May 24, 2023
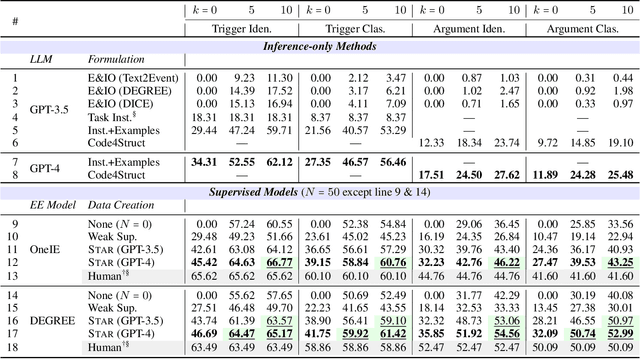

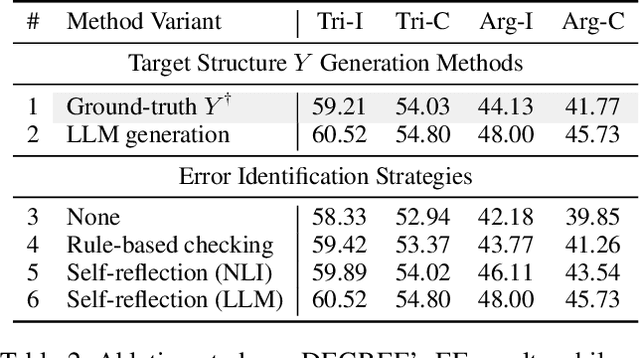
Structure prediction tasks such as event extraction require an in-depth understanding of the output structure and sub-task dependencies, thus they still heavily rely on task-specific training data to obtain reasonable performance. Due to the high cost of human annotation, low-resource event extraction, which requires minimal human cost, is urgently needed in real-world information extraction applications. We propose to synthesize data instances given limited seed demonstrations to boost low-resource event extraction performance. We propose STAR, a structure-to-text data generation method that first generates complicated event structures (Y) and then generates input passages (X), all with Large Language Models. We design fine-grained step-by-step instructions and the error cases and quality issues identified through self-reflection can be self-refined. Our experiments indicate that data generated by STAR can significantly improve the low-resource event extraction performance and they are even more effective than human-curated data points in some cases.