 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Training Data for Denoising Real RGB Images via Camera Pipeline Simulation
Apr 18, 2019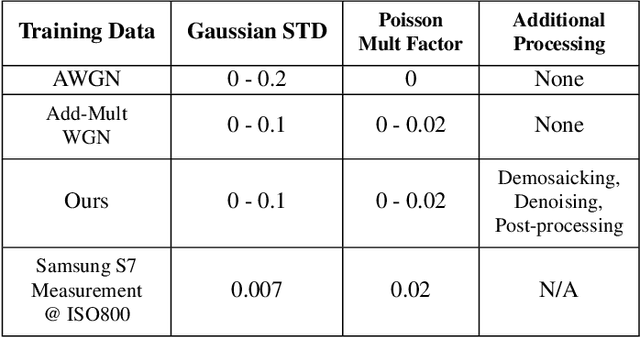

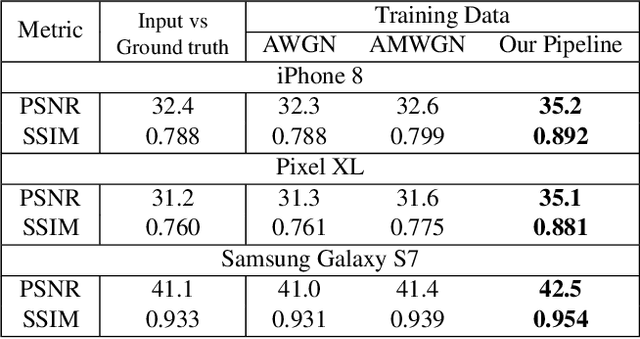

Image reconstruction techniques such as denoising often need to be applied to the RGB output of cameras and cellphones. Unfortunately, the commonly used additive white noise (AWGN) models do not accurately reproduce the noise and the degradation encountered on these inputs. This is particularly important for learning-based techniques, because the mismatch between training and real world data will hurt their generalization. This paper aims to accurately simulate the degradation and noise transformation performed by camera pipelines. This allows us to generate realistic degradation in RGB images that can be used to train machine learning models. We use our simulation to study the importance of noise modeling for learning-based denoising. Our study shows that a realistic noise model is required for learning to denoise real JPEG images. A neural network trained on realistic noise outperforms the one trained with AWGN by 3 dB. An ablation study of our pipeline shows that simulating denoising and demosaicking is important to this improvement and that realistic demosaicking algorithms, which have been rarely considered, is needed. We believe this simulation will also be useful for other image reconstruction tasks, and we will distribute our code publicly.
Learning-based Video Motion Magnification
Aug 01, 2018

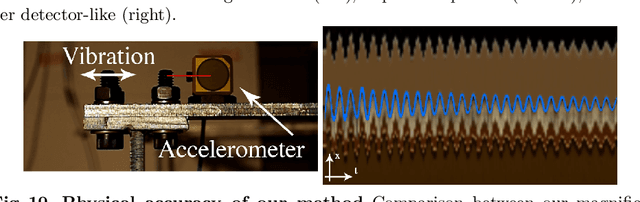

Video motion magnification techniques allow us to see small motions previously invisible to the naked eyes, such as those of vibrating airplane wings, or swaying buildings under the influence of the wind. Because the motion is small, the magnification results are prone to noise or excessive blurring. The state of the art relies on hand-designed filters to extract representations that may not be optimal. In this paper, we seek to learn the filters directly from examples using deep convolutional neural networks. To make training tractable, we carefully design a synthetic dataset that captures small motion well, and use two-frame input for training. We show that the learned filters achieve high-quality results on real videos, with less ringing artifacts and better noise characteristics than previous methods. While our model is not trained with temporal filters, we found that the temporal filters can be used with our extracted representations up to a moderate magnification, enabling a frequency-based motion selection. Finally, we analyze the learned filters and show that they behave similarly to the derivative filters used in previous works. Our code, trained model, and datasets will be available online.
A Video-Based Method for Objectively Rating Ataxia
Sep 07, 2017
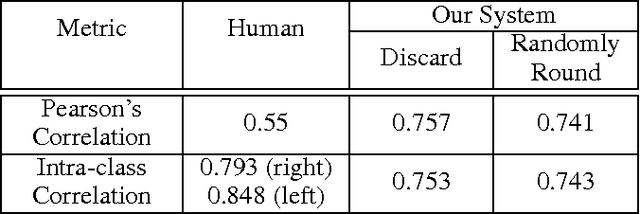
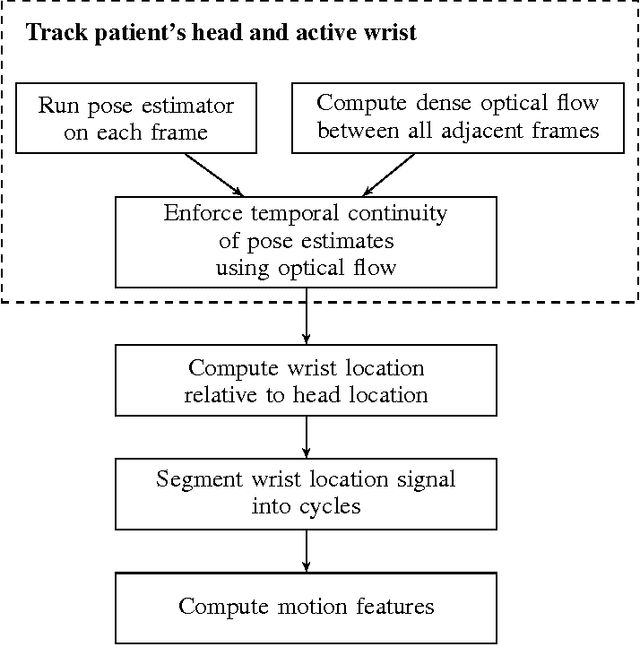
For many movement disorders, such as Parkinson's disease and ataxia, disease progression is visually assessed by a clinician using a numerical disease rating scale. These tests are subjective, time-consuming, and must be administered by a professional. This can be problematic where specialists are not available, or when a patient is not consistently evaluated by the same clinician. We present an automated method for quantifying the severity of motion impairment in patients with ataxia, using only video recordings. We consider videos of the finger-to-nose test, a common movement task used as part of the assessment of ataxia progression during the course of routine clinical checkups. Our method uses neural network-based pose estimation and optical flow techniques to track the motion of the patient's hand in a video recording. We extract features that describe qualities of the motion such as speed and variation in performance. Using labels provided by an expert clinician, we train a supervised learning model that predicts severity according to the Brief Ataxia Rating Scale (BARS). The performance of our system is comparable to that of a group of ataxia specialists in terms of mean error and correlation, and our system's predictions were consistently within the range of inter-rater variability. This work demonstrates the feasibility of using computer vision and machine learning to produce consistent and clinically useful measures of motor impairment.