 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRescan: Inductive Instance Segmentation for Indoor RGBD Scans
Sep 25, 2019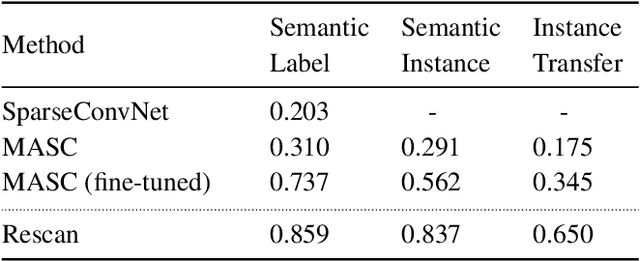
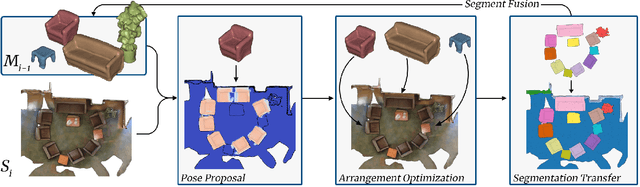
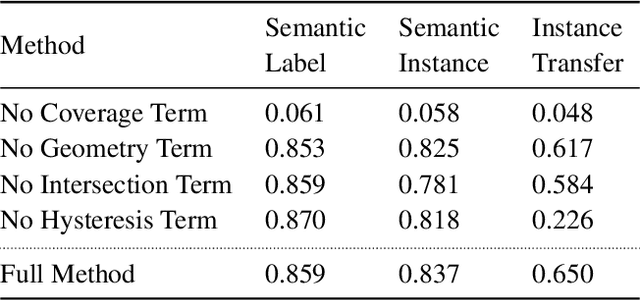
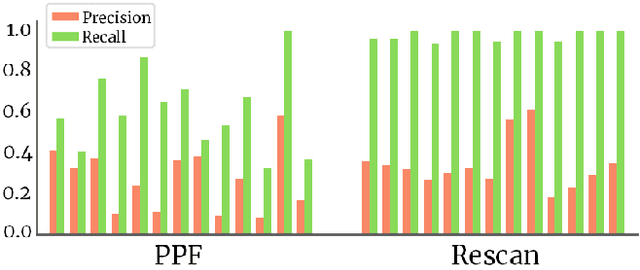
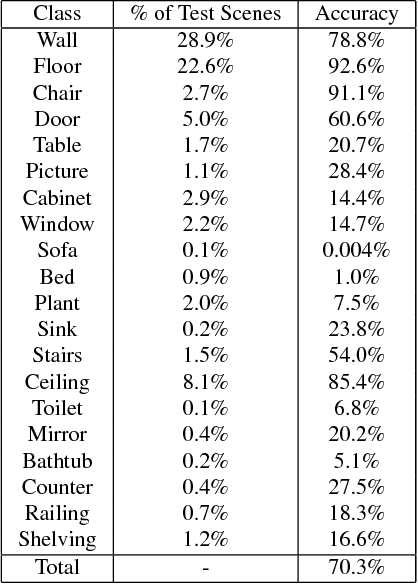
In depth-sensing applications ranging from home robotics to AR/VR, it will be common to acquire 3D scans of interior spaces repeatedly at sparse time intervals (e.g., as part of regular daily use). We propose an algorithm that analyzes these "rescans" to infer a temporal model of a scene with semantic instance information. Our algorithm operates inductively by using the temporal model resulting from past observations to infer an instance segmentation of a new scan, which is then used to update the temporal model. The model contains object instance associations across time and thus can be used to track individual objects, even though there are only sparse observations. During experiments with a new benchmark for the new task, our algorithm outperforms alternate approaches based on state-of-the-art networks for semantic instance segmentation.
Accelerating Large-Kernel Convolution Using Summed-Area Tables
Jun 26, 2019
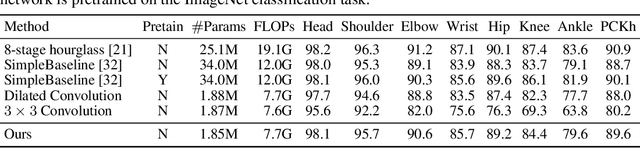
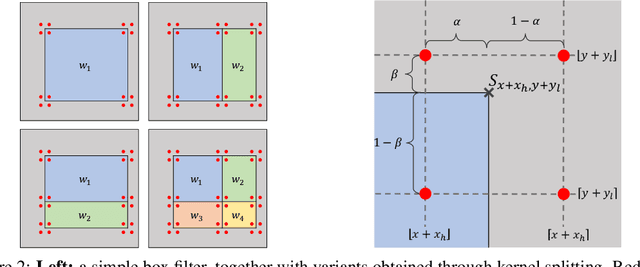
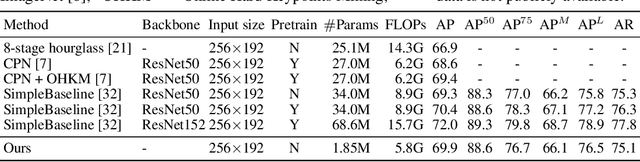
Expanding the receptive field to capture large-scale context is key to obtaining good performance in dense prediction tasks, such as human pose estimation. While many state-of-the-art fully-convolutional architectures enlarge the receptive field by reducing resolution using strided convolution or pooling layers, the most straightforward strategy is adopting large filters. This, however, is costly because of the quadratic increase in the number of parameters and multiply-add operations. In this work, we explore using learnable box filters to allow for convolution with arbitrarily large kernel size, while keeping the number of parameters per filter constant. In addition, we use precomputed summed-area tables to make the computational cost of convolution independent of the filter size. We adapt and incorporate the box filter as a differentiable module in a fully-convolutional neural network, and demonstrate its competitive performance on popular benchmarks for the task of human pose estimation.
Matterport3D: Learning from RGB-D Data in Indoor Environments
Sep 18, 2017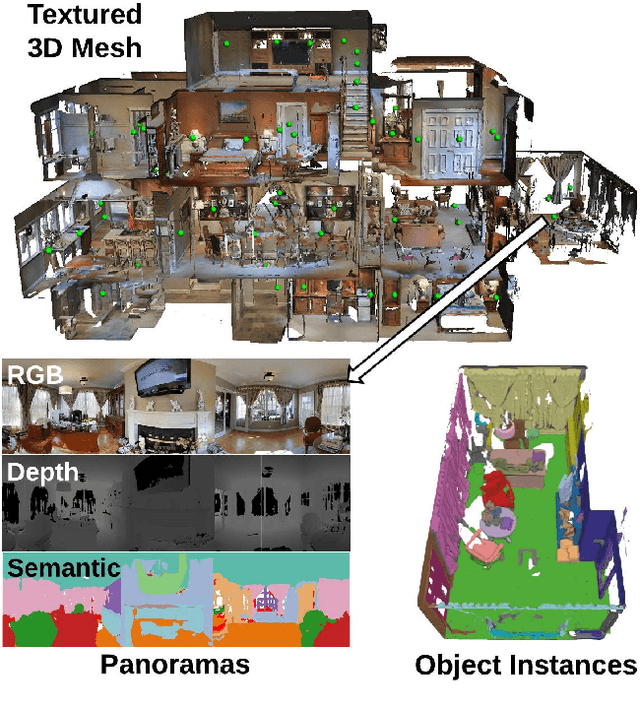


Access to large, diverse RGB-D datasets is critical for training RGB-D scene understanding algorithms. However, existing datasets still cover only a limited number of views or a restricted scale of spaces. In this paper, we introduce Matterport3D, a large-scale RGB-D dataset containing 10,800 panoramic views from 194,400 RGB-D images of 90 building-scale scenes. Annotations are provided with surface reconstructions, camera poses, and 2D and 3D semantic segmentations. The precise global alignment and comprehensive, diverse panoramic set of views over entire buildings enable a variety of supervised and self-supervised computer vision tasks, including keypoint matching, view overlap prediction, normal prediction from color, semantic segmentation, and region classification.
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
Apr 11, 2017



A key requirement for leveraging supervised deep learning methods is the availability of large, labeled datasets. Unfortunately, in the context of RGB-D scene understanding, very little data is available -- current datasets cover a small range of scene views and have limited semantic annotations. To address this issue, we introduce ScanNet, an RGB-D video dataset containing 2.5M views in 1513 scenes annotated with 3D camera poses, surface reconstructions, and semantic segmentations. To collect this data, we designed an easy-to-use and scalable RGB-D capture system that includes automated surface reconstruction and crowdsourced semantic annotation. We show that using this data helps achieve state-of-the-art performance on several 3D scene understanding tasks, including 3D object classification, semantic voxel labeling, and CAD model retrieval. The dataset is freely available at http://www.scan-net.org.
Fine-To-Coarse Global Registration of RGB-D Scans
Nov 23, 2016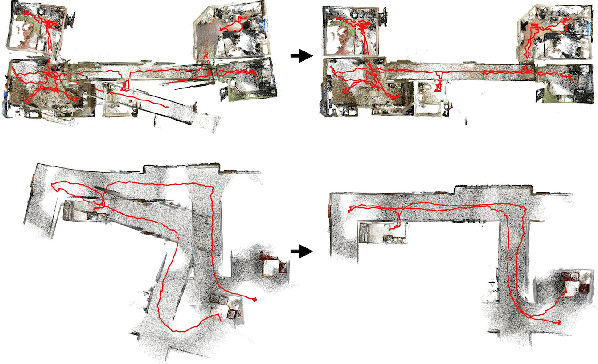
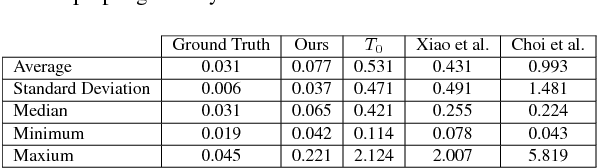
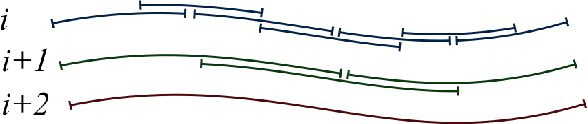

RGB-D scanning of indoor environments is important for many applications, including real estate, interior design, and virtual reality. However, it is still challenging to register RGB-D images from a hand-held camera over a long video sequence into a globally consistent 3D model. Current methods often can lose tracking or drift and thus fail to reconstruct salient structures in large environments (e.g., parallel walls in different rooms). To address this problem, we propose a "fine-to-coarse" global registration algorithm that leverages robust registrations at finer scales to seed detection and enforcement of new correspondence and structural constraints at coarser scales. To test global registration algorithms, we provide a benchmark with 10,401 manually-clicked point correspondences in 25 scenes from the SUN3D dataset. During experiments with this benchmark, we find that our fine-to-coarse algorithm registers long RGB-D sequences better than previous methods.