 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFTer-UNet: Axial Fusion Transformer UNet for Medical Image Segmentation
Paper and Code
Oct 20, 2021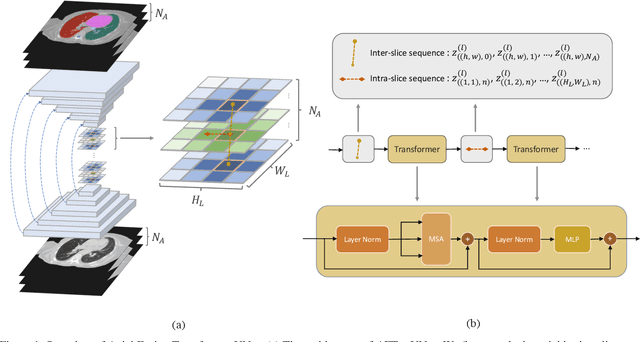
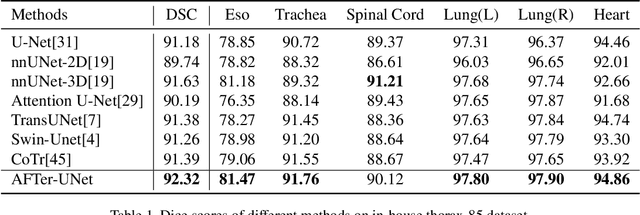

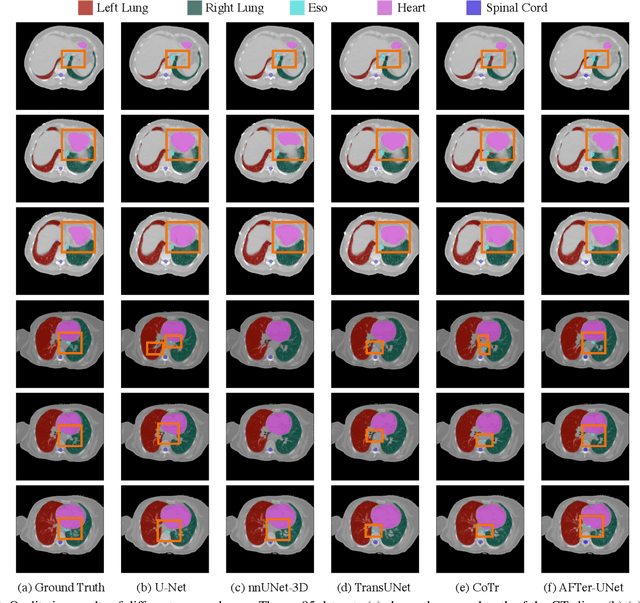
Recent advances in transformer-based models have drawn attention to exploring these techniques in medical image segmentation, especially in conjunction with the U-Net model (or its variants), which has shown great success in medical image segmentation, under both 2D and 3D settings. Current 2D based methods either directly replace convolutional layers with pure transformers or consider a transformer as an additional intermediate encoder between the encoder and decoder of U-Net. However, these approaches only consider the attention encoding within one single slice and do not utilize the axial-axis information naturally provided by a 3D volume. In the 3D setting, convolution on volumetric data and transformers both consume large GPU memory. One has to either downsample the image or use cropped local patches to reduce GPU memory usage, which limits its performance. In this paper, we propose Axial Fusion Transformer UNet (AFTer-UNet), which takes both advantages of convolutional layers' capability of extracting detailed features and transformers' strength on long sequence modeling. It considers both intra-slice and inter-slice long-range cues to guide the segmentation. Meanwhile, it has fewer parameters and takes less GPU memory to train than the previous transformer-based models. Extensive experiments on three multi-organ segmentation datasets demonstrate that our method outperforms current state-of-the-art methods.