 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrion-14B: Open-source Multilingual Large Language Models
Jan 20, 2024In this study, we introduce Orion-14B, a collection of multilingual large language models with 14 billion parameters. We utilize a data scheduling approach to train a foundational model on a diverse corpus of 2.5 trillion tokens, sourced from texts in English, Chinese, Japanese, Korean, and other languages. Additionally, we fine-tuned a series of models tailored for conversational applications and other specific use cases. Our evaluation results demonstrate that Orion-14B achieves state-of-the-art performance across a broad spectrum of tasks. We make the Orion-14B model family and its associated code publicly accessible https://github.com/OrionStarAI/Orion, aiming to inspire future research and practical applications in the field.
Hazy Re-ID: An Interference Suppression Model For Domain Adaptation Person Re-identification Under Inclement Weather Condition
Apr 22, 2021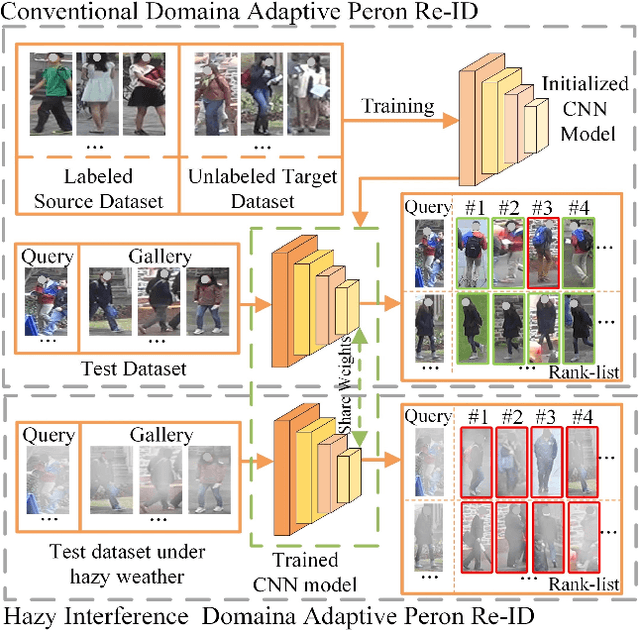
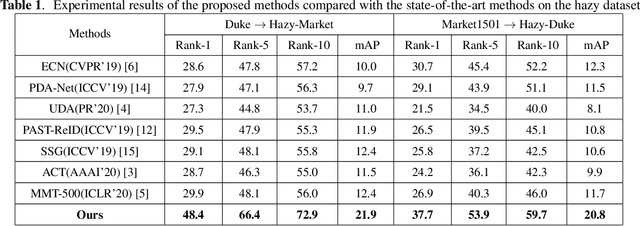
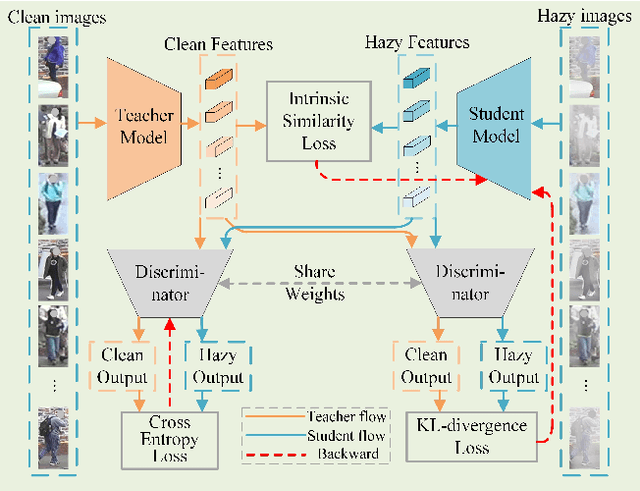
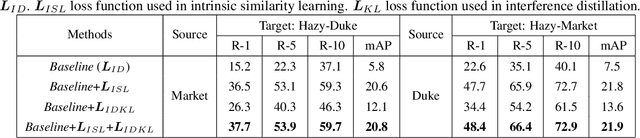
In a conventional domain adaptation person Re-identification (Re-ID) task, both the training and test images in target domain are collected under the sunny weather. However, in reality, the pedestrians to be retrieved may be obtained under severe weather conditions such as hazy, dusty and snowing, etc. This paper proposes a novel Interference Suppression Model (ISM) to deal with the interference caused by the hazy weather in domain adaptation person Re-ID. A teacherstudent model is used in the ISM to distill the interference information at the feature level by reducing the discrepancy between the clear and the hazy intrinsic similarity matrix. Furthermore, in the distribution level, the extra discriminator is introduced to assist the student model make the interference feature distribution more clear. The experimental results show that the proposed method achieves the superior performance on two synthetic datasets than the stateof-the-art methods. The related code will be released online https://github.com/pangjian123/ISM-ReID.