 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Polynomial-time Algorithm for Online Sparse Linear Regression with Improved Regret Bound under Weaker Conditions
Oct 31, 2025In this paper, we study the problem of online sparse linear regression (OSLR) where the algorithms are restricted to accessing only $k$ out of $d$ attributes per instance for prediction, which was proved to be NP-hard. Previous work gave polynomial-time algorithms assuming the data matrix satisfies the linear independence of features, the compatibility condition, or the restricted isometry property. We introduce a new polynomial-time algorithm, which significantly improves previous regret bounds (Ito et al., 2017) under the compatibility condition that is weaker than the other two assumptions. The improvements benefit from a tighter convergence rate of the $\ell_1$-norm error of our estimators. Our algorithm leverages the well-studied Dantzig Selector, but importantly with several novel techniques, including an algorithm-dependent sampling scheme for estimating the covariance matrix, an adaptive parameter tuning scheme, and a batching online Newton step with careful initializations. We also give novel and non-trivial analyses, including an induction method for analyzing the $\ell_1$-norm error, careful analyses on the covariance of non-independent random variables, and a decomposition on the regret. We further extend our algorithm to OSLR with additional observations where the algorithms can observe additional $k_0$ attributes after each prediction, and improve previous regret bounds (Kale et al., 2017; Ito et al., 2017).
Learnability in Online Kernel Selection with Memory Constraint via Data-dependent Regret Analysis
Jul 01, 2024
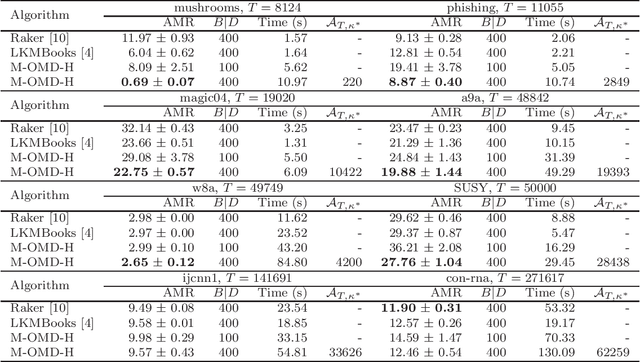
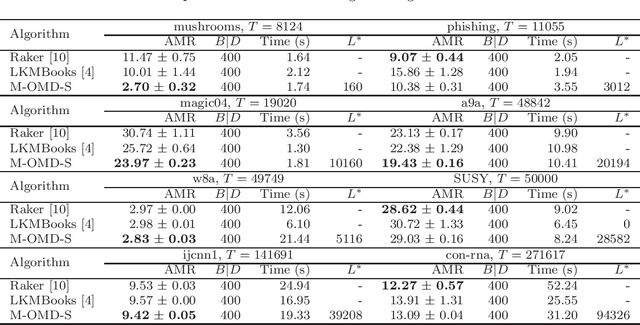
Online kernel selection is a fundamental problem of online kernel methods. In this paper, we study online kernel selection with memory constraint in which the memory of kernel selection and online prediction procedures is limited to a fixed budget. An essential question is what is the intrinsic relationship among online learnability, memory constraint and data complexity? To answer the question, it is necessary to show the trade-offs between regret bound and memory constraint. Previous work gives a worst-case lower bound depending on the data size,and shows learning is impossible within a small memory constraint. In contrast, we present a different result by providing data-dependent upper bounds depending on two data complexities, namely kernel alignment and the cumulative losses of competitive hypothesis. We propose an algorithmic framework giving data-dependent upper bounds for two types of loss functions. For the hinge loss function, our algorithm achieves an expected upper bound depending on kernel alignment. For smooth loss functions,our algorithm achieves a high-probability upper bound depending on the cumulative losses of competitive hypothesis. We also prove a matching lower bound for smooth loss functions. Our results show that if the two data complexities are sub-linear, then learning is possible within a small memory constraint. Our algorithmic framework depends on a new buffer maintaining framework and a reduction from online kernel selection to prediction with expert advice.Finally, we empirically verify the prediction performance of our algorithms on benchmark datasets.
Ahpatron: A New Budgeted Online Kernel Learning Machine with Tighter Mistake Bound
Dec 12, 2023
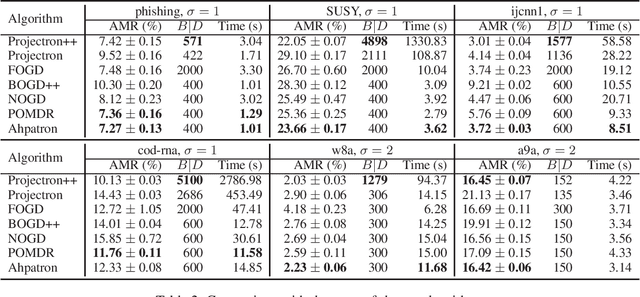


In this paper, we study the mistake bound of online kernel learning on a budget. We propose a new budgeted online kernel learning model, called Ahpatron, which significantly improves the mistake bound of previous work and resolves the open problem posed by Dekel, Shalev-Shwartz, and Singer (2005). We first present an aggressive variant of Perceptron, named AVP, a model without budget, which uses an active updating rule. Then we design a new budget maintenance mechanism, which removes a half of examples,and projects the removed examples onto a hypothesis space spanned by the remaining examples. Ahpatron adopts the above mechanism to approximate AVP. Theoretical analyses prove that Ahpatron has tighter mistake bounds, and experimental results show that Ahpatron outperforms the state-of-the-art algorithms on the same or a smaller budget.
Nearly Optimal Algorithms with Sublinear Computational Complexity for Online Kernel Regression
Jun 14, 2023The trade-off between regret and computational cost is a fundamental problem for online kernel regression, and previous algorithms worked on the trade-off can not keep optimal regret bounds at a sublinear computational complexity. In this paper, we propose two new algorithms, AOGD-ALD and NONS-ALD, which can keep nearly optimal regret bounds at a sublinear computational complexity, and give sufficient conditions under which our algorithms work. Both algorithms dynamically maintain a group of nearly orthogonal basis used to approximate the kernel mapping, and keep nearly optimal regret bounds by controlling the approximate error. The number of basis depends on the approximate error and the decay rate of eigenvalues of the kernel matrix. If the eigenvalues decay exponentially, then AOGD-ALD and NONS-ALD separately achieves a regret of $O(\sqrt{L(f)})$ and $O(\mathrm{d}_{\mathrm{eff}}(\mu)\ln{T})$ at a computational complexity in $O(\ln^2{T})$. If the eigenvalues decay polynomially with degree $p\geq 1$, then our algorithms keep the same regret bounds at a computational complexity in $o(T)$ in the case of $p>4$ and $p\geq 10$, respectively. $L(f)$ is the cumulative losses of $f$ and $\mathrm{d}_{\mathrm{eff}}(\mu)$ is the effective dimension of the problem. The two regret bounds are nearly optimal and are not comparable.
Improved Regret Bounds for Online Kernel Selection under Bandit Feedback
Mar 09, 2023



In this paper, we improve the regret bound for online kernel selection under bandit feedback. Previous algorithm enjoys a $O((\Vert f\Vert^2_{\mathcal{H}_i}+1)K^{\frac{1}{3}}T^{\frac{2}{3}})$ expected bound for Lipschitz loss functions. We prove two types of regret bounds improving the previous bound. For smooth loss functions, we propose an algorithm with a $O(U^{\frac{2}{3}}K^{-\frac{1}{3}}(\sum^K_{i=1}L_T(f^\ast_i))^{\frac{2}{3}})$ expected bound where $L_T(f^\ast_i)$ is the cumulative losses of optimal hypothesis in $\mathbb{H}_{i}=\{f\in\mathcal{H}_i:\Vert f\Vert_{\mathcal{H}_i}\leq U\}$. The data-dependent bound keeps the previous worst-case bound and is smaller if most of candidate kernels match well with the data. For Lipschitz loss functions, we propose an algorithm with a $O(U\sqrt{KT}\ln^{\frac{2}{3}}{T})$ expected bound asymptotically improving the previous bound. We apply the two algorithms to online kernel selection with time constraint and prove new regret bounds matching or improving the previous $O(\sqrt{T\ln{K}} +\Vert f\Vert^2_{\mathcal{H}_i}\max\{\sqrt{T},\frac{T}{\sqrt{\mathcal{R}}}\})$ expected bound where $\mathcal{R}$ is the time budget. Finally, we empirically verify our algorithms on online regression and classification tasks.
Improved Kernel Alignment Regret Bound for Online Kernel Learning
Dec 26, 2022In this paper, we improve the kernel alignment regret bound for online kernel learning in the regime of the Hinge loss function. Previous algorithm achieves a regret of $O((\mathcal{A}_TT\ln{T})^{\frac{1}{4}})$ at a computational complexity (space and per-round time) of $O(\sqrt{\mathcal{A}_TT\ln{T}})$, where $\mathcal{A}_T$ is called \textit{kernel alignment}. We propose an algorithm whose regret bound and computational complexity are better than previous results. Our results depend on the decay rate of eigenvalues of the kernel matrix. If the eigenvalues of the kernel matrix decay exponentially, then our algorithm enjoys a regret of $O(\sqrt{\mathcal{A}_T})$ at a computational complexity of $O(\ln^2{T})$. Otherwise, our algorithm enjoys a regret of $O((\mathcal{A}_TT)^{\frac{1}{4}})$ at a computational complexity of $O(\sqrt{\mathcal{A}_TT})$. We extend our algorithm to batch learning and obtain a $O(\frac{1}{T}\sqrt{\mathbb{E}[\mathcal{A}_T]})$ excess risk bound which improves the previous $O(1/\sqrt{T})$ bound.