 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeMusic-Agent: Efficient Conversational Music Recommendation via Knowledge Internalization and Agentic Boundary Learning
Dec 18, 2025Personalized music recommendation in conversational scenarios usually requires a deep understanding of user preferences and nuanced musical context, yet existing methods often struggle with balancing specialized domain knowledge and flexible tool integration. This paper proposes WeMusic-Agent, a training framework for efficient LLM-based conversational music recommendation. By integrating the knowledge internalization and agentic boundary learning, the framework aims to teach the model to intelligently decide when to leverage internalized knowledge and when to call specialized tools (e.g., music retrieval APIs, music recommendation systems). Under this framework, we present WeMusic-Agent-M1, an agentic model that internalizes extensive musical knowledge via continued pretraining on 50B music-related corpus while acquiring the ability to invoke external tools when necessary. Additionally, considering the lack of open-source benchmarks for conversational music recommendation, we also construct a benchmark for personalized music recommendations derived from real-world data in WeChat Listen. This benchmark enables comprehensive evaluation across multiple dimensions, including relevance, personalization, and diversity of the recommendations. Experiments on real-world data demonstrate that WeMusic-Agent achieves significant improvements over existing models.
MuCPT: Music-related Natural Language Model Continued Pretraining
Nov 18, 2025
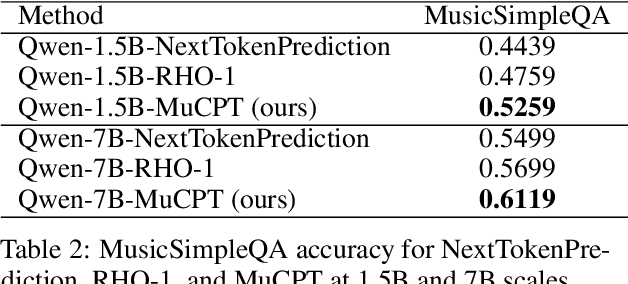
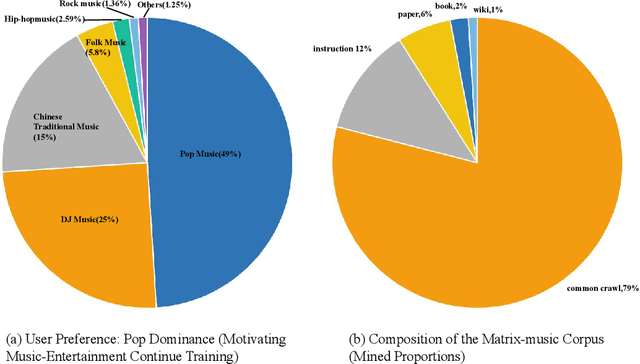
Large language models perform strongly on general tasks but remain constrained in specialized settings such as music, particularly in the music-entertainment domain, where corpus scale, purity, and the match between data and training objectives are critical. We address this by constructing a large, music-related natural language corpus (40B tokens) that combines open source and in-house data, and by implementing a domain-first data pipeline: a lightweight classifier filters and weights in-domain text, followed by multi-stage cleaning, de-duplication, and privacy-preserving masking. We further integrate multi-source music text with associated metadata to form a broader, better-structured foundation of domain knowledge. On the training side, we introduce reference-model (RM)-based token-level soft scoring for quality control: a unified loss-ratio criterion is used both for data selection and for dynamic down-weighting during optimization, reducing noise gradients and amplifying task-aligned signals, thereby enabling more effective music-domain continued pretraining and alignment. To assess factuality, we design the MusicSimpleQA benchmark, which adopts short, single-answer prompts with automated agreement scoring. Beyond the benchmark design, we conduct systematic comparisons along the axes of data composition. Overall, this work advances both the right corpus and the right objective, offering a scalable data-training framework and a reusable evaluation tool for building domain LLMs in the music field.
Bridged-GNN: Knowledge Bridge Learning for Effective Knowledge Transfer
Aug 18, 2023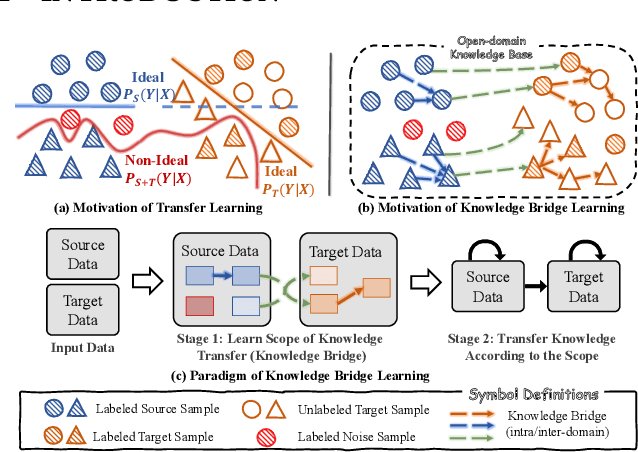



The data-hungry problem, characterized by insufficiency and low-quality of data, poses obstacles for deep learning models. Transfer learning has been a feasible way to transfer knowledge from high-quality external data of source domains to limited data of target domains, which follows a domain-level knowledge transfer to learn a shared posterior distribution. However, they are usually built on strong assumptions, e.g., the domain invariant posterior distribution, which is usually unsatisfied and may introduce noises, resulting in poor generalization ability on target domains. Inspired by Graph Neural Networks (GNNs) that aggregate information from neighboring nodes, we redefine the paradigm as learning a knowledge-enhanced posterior distribution for target domains, namely Knowledge Bridge Learning (KBL). KBL first learns the scope of knowledge transfer by constructing a Bridged-Graph that connects knowledgeable samples to each target sample and then performs sample-wise knowledge transfer via GNNs.KBL is free from strong assumptions and is robust to noises in the source data. Guided by KBL, we propose the Bridged-GNN} including an Adaptive Knowledge Retrieval module to build Bridged-Graph and a Graph Knowledge Transfer module. Comprehensive experiments on both un-relational and relational data-hungry scenarios demonstrate the significant improvements of Bridged-GNN compared with SOTA methods
Homophily-oriented Heterogeneous Graph Rewiring
Feb 24, 2023With the rapid development of the World Wide Web (WWW), heterogeneous graphs (HG) have explosive growth. Recently, heterogeneous graph neural network (HGNN) has shown great potential in learning on HG. Current studies of HGNN mainly focus on some HGs with strong homophily properties (nodes connected by meta-path tend to have the same labels), while few discussions are made in those that are less homophilous. Recently, there have been many works on homogeneous graphs with heterophily. However, due to heterogeneity, it is non-trivial to extend their approach to deal with HGs with heterophily. In this work, based on empirical observations, we propose a meta-path-induced metric to measure the homophily degree of a HG. We also find that current HGNNs may have degenerated performance when handling HGs with less homophilous properties. Thus it is essential to increase the generalization ability of HGNNs on non-homophilous HGs. To this end, we propose HDHGR, a homophily-oriented deep heterogeneous graph rewiring approach that modifies the HG structure to increase the performance of HGNN. We theoretically verify HDHGR. In addition, experiments on real-world HGs demonstrate the effectiveness of HDHGR, which brings at most more than 10% relative gain.
Predicting the Silent Majority on Graphs: Knowledge Transferable Graph Neural Network
Feb 02, 2023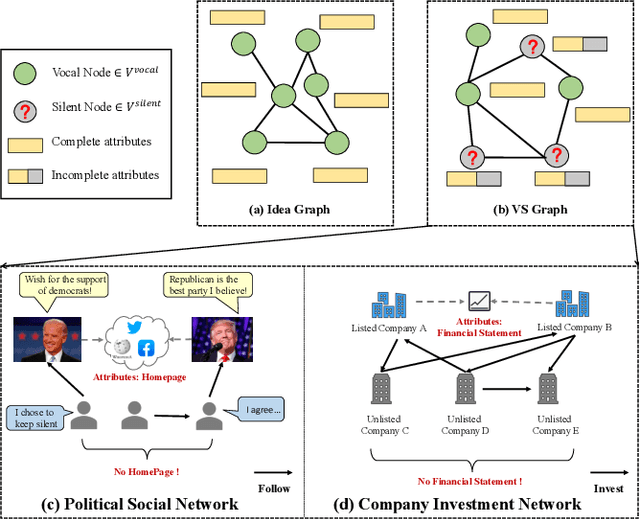

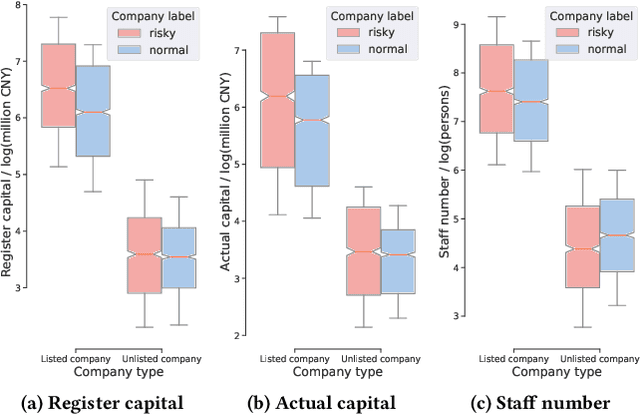
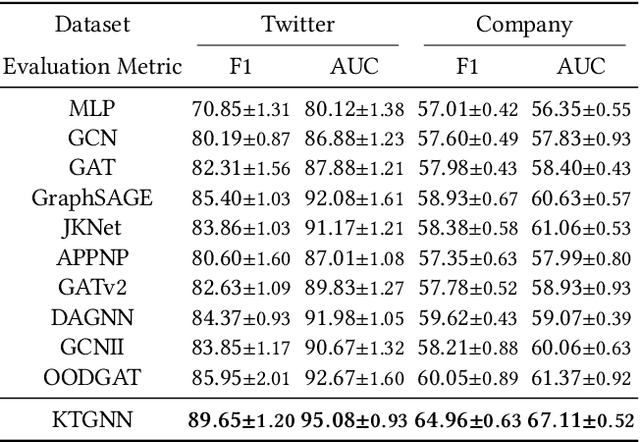
Graphs consisting of vocal nodes ("the vocal minority") and silent nodes ("the silent majority"), namely VS-Graph, are ubiquitous in the real world. The vocal nodes tend to have abundant features and labels. In contrast, silent nodes only have incomplete features and rare labels, e.g., the description and political tendency of politicians (vocal) are abundant while not for ordinary people (silent) on the twitter's social network. Predicting the silent majority remains a crucial yet challenging problem. However, most existing message-passing based GNNs assume that all nodes belong to the same domain, without considering the missing features and distribution-shift between domains, leading to poor ability to deal with VS-Graph. To combat the above challenges, we propose Knowledge Transferable Graph Neural Network (KT-GNN), which models distribution shifts during message passing and representation learning by transferring knowledge from vocal nodes to silent nodes. Specifically, we design the domain-adapted "feature completion and message passing mechanism" for node representation learning while preserving domain difference. And a knowledge transferable classifier based on KL-divergence is followed. Comprehensive experiments on real-world scenarios (i.e., company financial risk assessment and political elections) demonstrate the superior performance of our method. Our source code has been open sourced.
Company-as-Tribe: Company Financial Risk Assessment on Tribe-Style Graph with Hierarchical Graph Neural Networks
Jan 31, 2023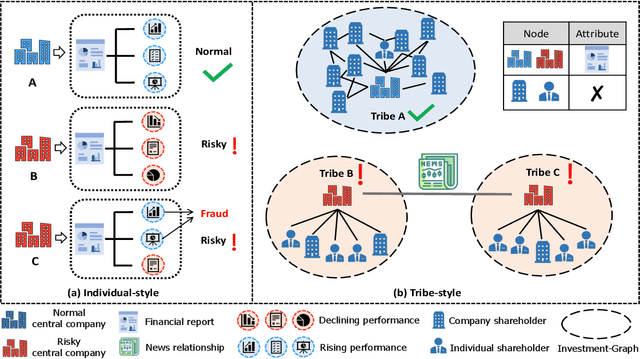
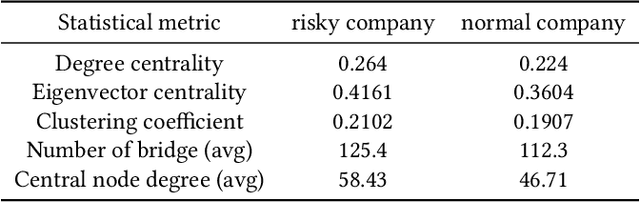
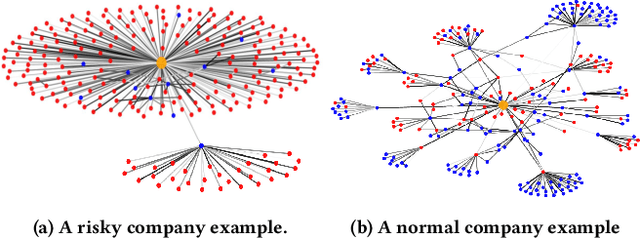

Company financial risk is ubiquitous and early risk assessment for listed companies can avoid considerable losses. Traditional methods mainly focus on the financial statements of companies and lack the complex relationships among them. However, the financial statements are often biased and lagged, making it difficult to identify risks accurately and timely. To address the challenges, we redefine the problem as \textbf{company financial risk assessment on tribe-style graph} by taking each listed company and its shareholders as a tribe and leveraging financial news to build inter-tribe connections. Such tribe-style graphs present different patterns to distinguish risky companies from normal ones. However, most nodes in the tribe-style graph lack attributes, making it difficult to directly adopt existing graph learning methods (e.g., Graph Neural Networks(GNNs)). In this paper, we propose a novel Hierarchical Graph Neural Network (TH-GNN) for Tribe-style graphs via two levels, with the first level to encode the structure pattern of the tribes with contrastive learning, and the second level to diffuse information based on the inter-tribe relations, achieving effective and efficient risk assessment. Extensive experiments on the real-world company dataset show that our method achieves significant improvements on financial risk assessment over previous competing methods. Also, the extensive ablation studies and visualization comprehensively show the effectiveness of our method.
Make Heterophily Graphs Better Fit GNN: A Graph Rewiring Approach
Sep 17, 2022



Graph Neural Networks (GNNs) are popular machine learning methods for modeling graph data. A lot of GNNs perform well on homophily graphs while having unsatisfactory performance on heterophily graphs. Recently, some researchers turn their attention to designing GNNs for heterophily graphs by adjusting the message passing mechanism or enlarging the receptive field of the message passing. Different from existing works that mitigate the issues of heterophily from model design perspective, we propose to study heterophily graphs from an orthogonal perspective by rewiring the graph structure to reduce heterophily and making the traditional GNNs perform better. Through comprehensive empirical studies and analysis, we verify the potential of the rewiring methods. To fully exploit its potential, we propose a method named Deep Heterophily Graph Rewiring (DHGR) to rewire graphs by adding homophilic edges and pruning heterophilic edges. The detailed way of rewiring is determined by comparing the similarity of label/feature-distribution of node neighbors. Besides, we design a scalable implementation for DHGR to guarantee high efficiency. DHRG can be easily used as a plug-in module, i.e., a graph pre-processing step, for any GNNs, including both GNN for homophily and heterophily, to boost their performance on the node classification task. To the best of our knowledge, it is the first work studying graph rewiring for heterophily graphs. Extensive experiments on 11 public graph datasets demonstrate the superiority of our proposed methods.
MM-GNN: Mix-Moment Graph Neural Network towards Modeling Neighborhood Feature Distribution
Aug 15, 2022



Graph Neural Networks (GNNs) have shown expressive performance on graph representation learning by aggregating information from neighbors. Recently, some studies have discussed the importance of modeling neighborhood distribution on the graph. However, most existing GNNs aggregate neighbors' features through single statistic (e.g., mean, max, sum), which loses the information related to neighbor's feature distribution and therefore degrades the model performance. In this paper, inspired by the method of moment in statistical theory, we propose to model neighbor's feature distribution with multi-order moments. We design a novel GNN model, namely Mix-Moment Graph Neural Network (MM-GNN), which includes a Multi-order Moment Embedding (MME) module and an Element-wise Attention-based Moment Adaptor module. MM-GNN first calculates the multi-order moments of the neighbors for each node as signatures, and then use an Element-wise Attention-based Moment Adaptor to assign larger weights to important moments for each node and update node representations. We conduct extensive experiments on 15 real-world graphs (including social networks, citation networks and web-page networks etc.) to evaluate our model, and the results demonstrate the superiority of MM-GNN over existing state-of-the-art models.
HTGN-BTW: Heterogeneous Temporal Graph Network with Bi-Time-Window Training Strategy for Temporal Link Prediction
Feb 25, 2022
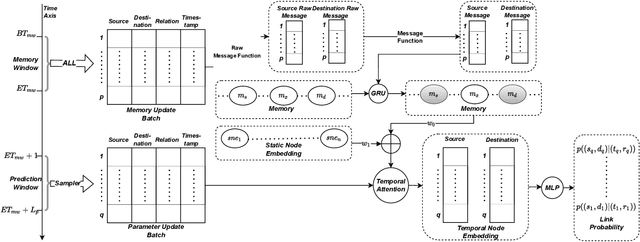

With the development of temporal networks such as E-commerce networks and social networks, the issue of temporal link prediction has attracted increasing attention in recent years. The Temporal Link Prediction task of WSDM Cup 2022 expects a single model that can work well on two kinds of temporal graphs simultaneously, which have quite different characteristics and data properties, to predict whether a link of a given type will occur between two given nodes within a given time span. Our team, named as nothing here, regards this task as a link prediction task in heterogeneous temporal networks and proposes a generic model, i.e., Heterogeneous Temporal Graph Network (HTGN), to solve such temporal link prediction task with the unfixed time intervals and the diverse link types. That is, HTGN can adapt to the heterogeneity of links and the prediction with unfixed time intervals within an arbitrary given time period. To train the model, we design a Bi-Time-Window training strategy (BTW) which has two kinds of mini-batches from two kinds of time windows. As a result, for the final test, we achieved an AUC of 0.662482 on dataset A, an AUC of 0.906923 on dataset B, and won 2nd place with an Average T-scores of 0.628942.
Bridging Disentanglement with Independence and Conditional Independence via Mutual Information for Representation Learning
Nov 26, 2019



Existing works on disentangled representation learning usually lie on a common assumption: all factors in disentangled representations should be independent. This assumption is about the inner property of disentangled representations, while ignoring their relation with external data. To tackle this problem, we propose another assumption to establish an important relation between data and its disentangled representations via mutual information: the mutual information between each factor of disentangled representations and data should be invariant to other factors. We formulate this assumption into mathematical equations, and theoretically bridge it with independence and conditional independence of factors. Meanwhile, we show that conditional independence is satisfied in encoders of VAEs due to factorized noise in reparameterization. To highlight the importance of our proposed assumption, we show in experiments that violating the assumption leads to dramatic decline of disentanglement. Based on this assumption, we further propose to split the deeper layers in encoder to ensure parameters in these layers are not shared for different factors. The proposed encoder, called Split Encoder, can be applied into models that penalize total correlation, and shows significant improvement in unsupervised learning of disentangled representations and reconstructions.