 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Audio Modeling with CLAP and Multi-Objective Learning
Paper and Code
Jan 29, 2024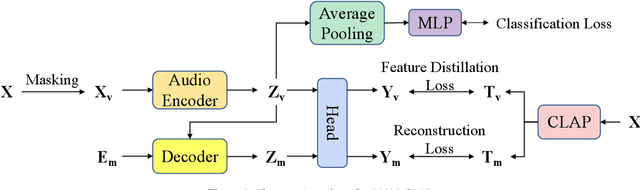
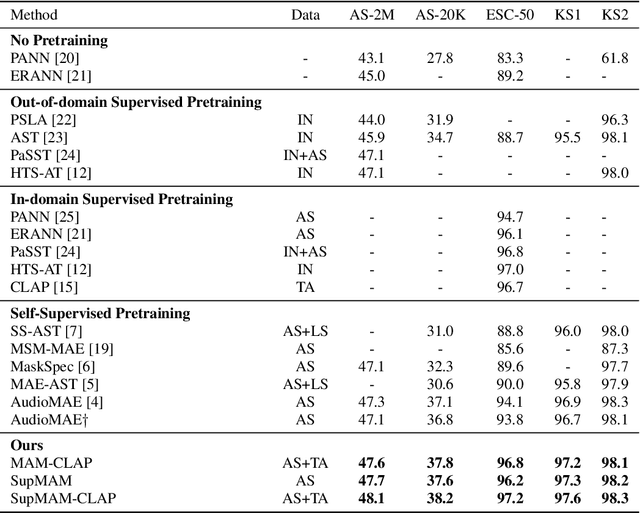
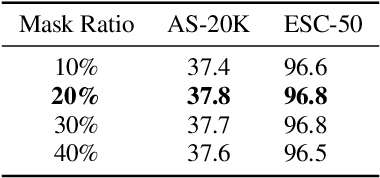
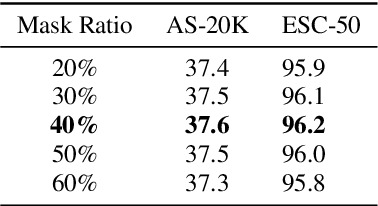
Most existing masked audio modeling (MAM) methods learn audio representations by masking and reconstructing local spectrogram patches. However, the reconstruction loss mainly accounts for the signal-level quality of the reconstructed spectrogram and is still limited in extracting high-level audio semantics. In this paper, we propose to enhance the semantic modeling of MAM by distilling cross-modality knowledge from contrastive language-audio pretraining (CLAP) representations for both masked and unmasked regions (MAM-CLAP) and leveraging a multi-objective learning strategy with a supervised classification branch (SupMAM), thereby providing more semantic knowledge for MAM and enabling it to effectively learn global features from labels. Experiments show that our methods significantly improve the performance on multiple downstream tasks. Furthermore, by combining our MAM-CLAP with SupMAM, we can achieve new state-of-the-art results on various audio and speech classification tasks, exceeding previous self-supervised learning and supervised pretraining methods.