 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-fidelity Singing Voice Conversion with Acoustic Reference and Contrastive Predictive Coding
Oct 10, 2021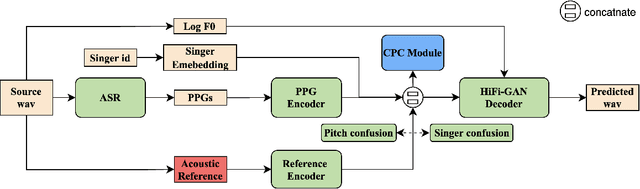
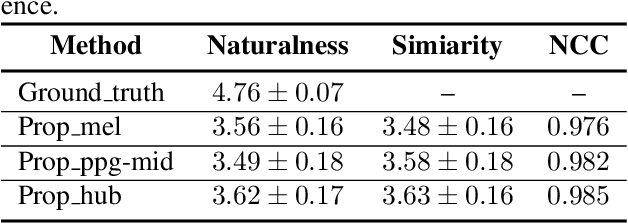
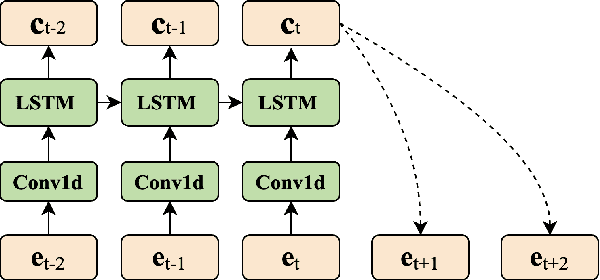

Recently, phonetic posteriorgrams (PPGs) based methods have been quite popular in non-parallel singing voice conversion systems. However, due to the lack of acoustic information in PPGs, style and naturalness of the converted singing voices are still limited. To solve these problems, in this paper, we utilize an acoustic reference encoder to implicitly model singing characteristics. We experiment with different auxiliary features, including mel spectrograms, HuBERT, and the middle hidden feature (PPG-Mid) of pretrained automatic speech recognition (ASR) model, as the input of the reference encoder, and finally find the HuBERT feature is the best choice. In addition, we use contrastive predictive coding (CPC) module to further smooth the voices by predicting future observations in latent space. Experiments show that, compared with the baseline models, our proposed model can significantly improve the naturalness of converted singing voices and the similarity with the target singer. Moreover, our proposed model can also make the speakers with just speech data sing.