 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPG-based singing voice conversion with adversarial representation learning
Paper and Code
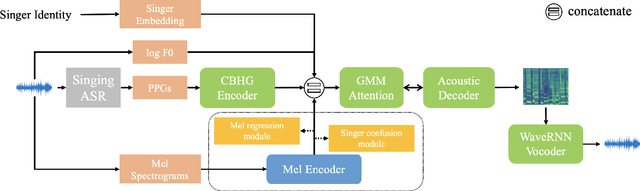
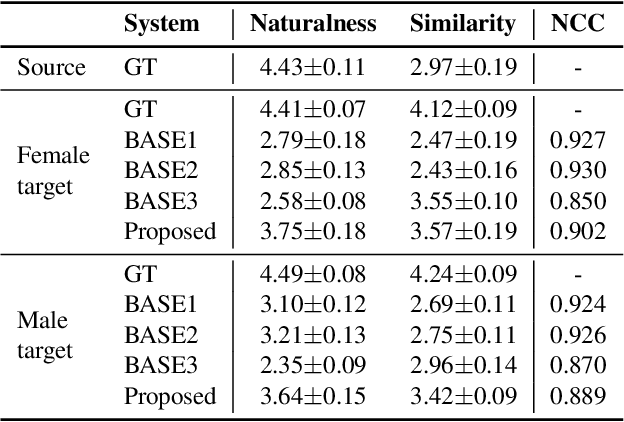
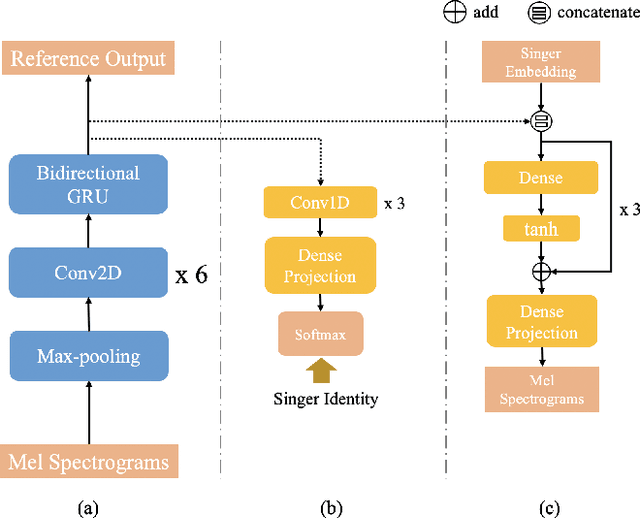
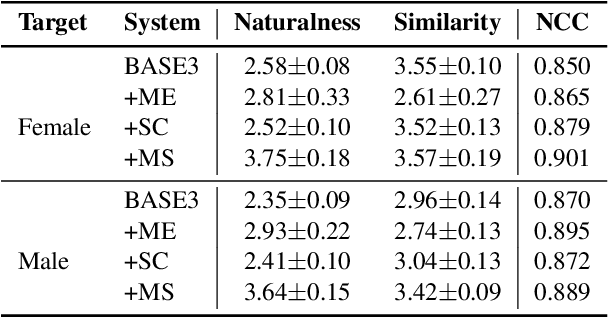
Singing voice conversion (SVC) aims to convert the voice of one singer to that of other singers while keeping the singing content and melody. On top of recent voice conversion works, we propose a novel model to steadily convert songs while keeping their naturalness and intonation. We build an end-to-end architecture, taking phonetic posteriorgrams (PPGs) as inputs and generating mel spectrograms. Specifically, we implement two separate encoders: one encodes PPGs as content, and the other compresses mel spectrograms to supply acoustic and musical information. To improve the performance on timbre and melody, an adversarial singer confusion module and a mel-regressive representation learning module are designed for the model. Objective and subjective experiments are conducted on our private Chinese singing corpus. Comparing with the baselines, our methods can significantly improve the conversion performance in terms of naturalness, melody, and voice similarity. Moreover, our PPG-based method is proved to be robust for noisy sources.