 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMKD: Improving Feature-based Knowledge Distillation for Object Detection Via Dual Masking Augmentation
Sep 07, 2023



Recent mainstream masked distillation methods function by reconstructing selectively masked areas of a student network from the feature map of its teacher counterpart. In these methods, the masked regions need to be properly selected, such that reconstructed features encode sufficient discrimination and representation capability like the teacher feature. However, previous masked distillation methods only focus on spatial masking, making the resulting masked areas biased towards spatial importance without encoding informative channel clues. In this study, we devise a Dual Masked Knowledge Distillation (DMKD) framework which can capture both spatially important and channel-wise informative clues for comprehensive masked feature reconstruction. More specifically, we employ dual attention mechanism for guiding the respective masking branches, leading to reconstructed feature encoding dual significance. Furthermore, fusing the reconstructed features is achieved by self-adjustable weighting strategy for effective feature distillation. Our experiments on object detection task demonstrate that the student networks achieve performance gains of 4.1% and 4.3% with the help of our method when RetinaNet and Cascade Mask R-CNN are respectively used as the teacher networks, while outperforming the other state-of-the-art distillation methods.
AMD: Adaptive Masked Distillation for Object Detection
Feb 10, 2023


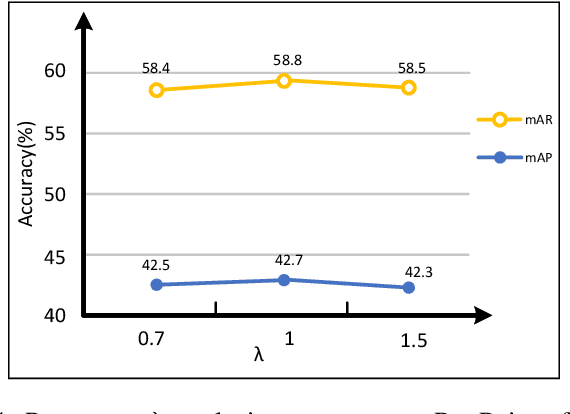
As a general model compression paradigm, feature-based knowledge distillation allows the student model to learn expressive features from the teacher counterpart. In this paper, we mainly focus on designing an effective feature-distillation framework and propose a spatial-channel adaptive masked distillation (AMD) network for object detection. More specifically, in order to accurately reconstruct important feature regions, we first perform attention-guided feature masking on the feature map of the student network, such that we can identify the important features via spatially adaptive feature masking instead of random masking in the previous methods. In addition, we employ a simple and efficient module to allow the student network channel to be adaptive, improving its model capability in object perception and detection. In contrast to the previous methods, more crucial object-aware features can be reconstructed and learned from the proposed network, which is conducive to accurate object detection. The empirical experiments demonstrate the superiority of our method: with the help of our proposed distillation method, the student networks report 41.3%, 42.4%, and 42.7% mAP scores when RetinaNet, Cascade Mask-RCNN and RepPoints are respectively used as the teacher framework for object detection, which outperforms the previous state-of-the-art distillation methods including FGD and MGD.
Look Before You Leap: Improving Text-based Person Retrieval by Learning A Consistent Cross-modal Common Manifold
Sep 13, 2022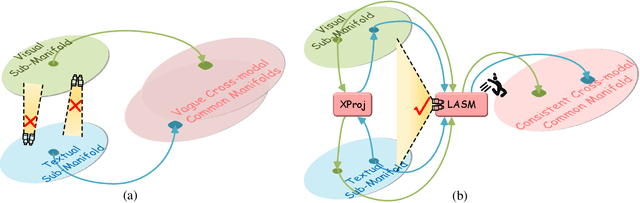
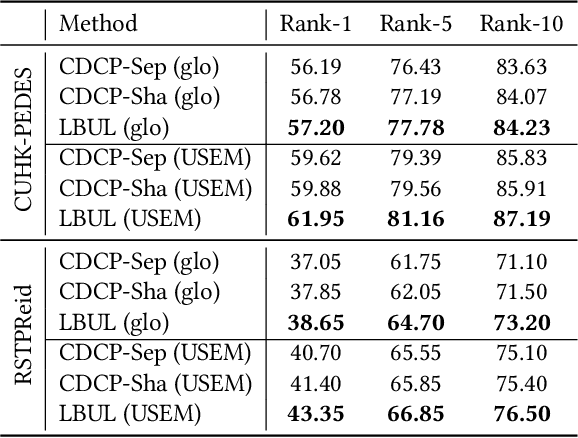
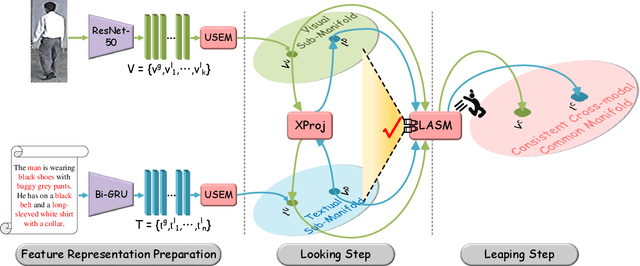
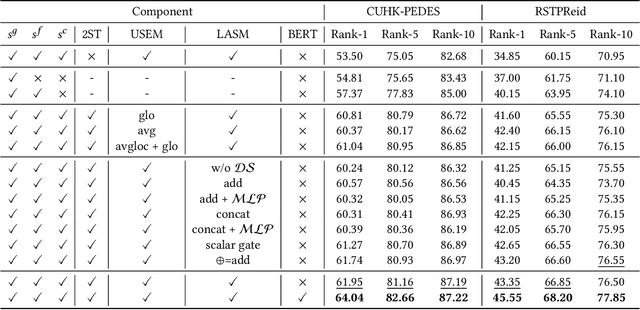
The core problem of text-based person retrieval is how to bridge the heterogeneous gap between multi-modal data. Many previous approaches contrive to learning a latent common manifold mapping paradigm following a \textbf{cross-modal distribution consensus prediction (CDCP)} manner. When mapping features from distribution of one certain modality into the common manifold, feature distribution of the opposite modality is completely invisible. That is to say, how to achieve a cross-modal distribution consensus so as to embed and align the multi-modal features in a constructed cross-modal common manifold all depends on the experience of the model itself, instead of the actual situation. With such methods, it is inevitable that the multi-modal data can not be well aligned in the common manifold, which finally leads to a sub-optimal retrieval performance. To overcome this \textbf{CDCP dilemma}, we propose a novel algorithm termed LBUL to learn a Consistent Cross-modal Common Manifold (C$^{3}$M) for text-based person retrieval. The core idea of our method, just as a Chinese saying goes, is to `\textit{san si er hou xing}', namely, to \textbf{Look Before yoU Leap (LBUL)}. The common manifold mapping mechanism of LBUL contains a looking step and a leaping step. Compared to CDCP-based methods, LBUL considers distribution characteristics of both the visual and textual modalities before embedding data from one certain modality into C$^{3}$M to achieve a more solid cross-modal distribution consensus, and hence achieve a superior retrieval accuracy. We evaluate our proposed method on two text-based person retrieval datasets CUHK-PEDES and RSTPReid. Experimental results demonstrate that the proposed LBUL outperforms previous methods and achieves the state-of-the-art performance.
CAIBC: Capturing All-round Information Beyond Color for Text-based Person Retrieval
Sep 13, 2022
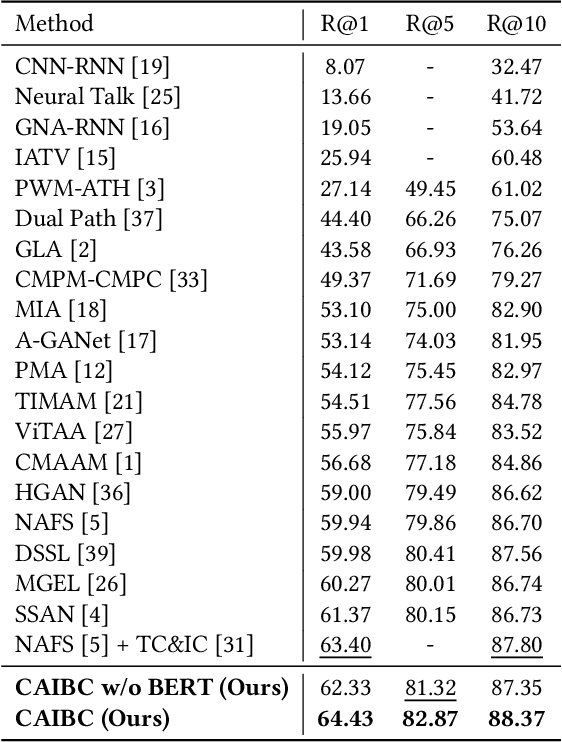
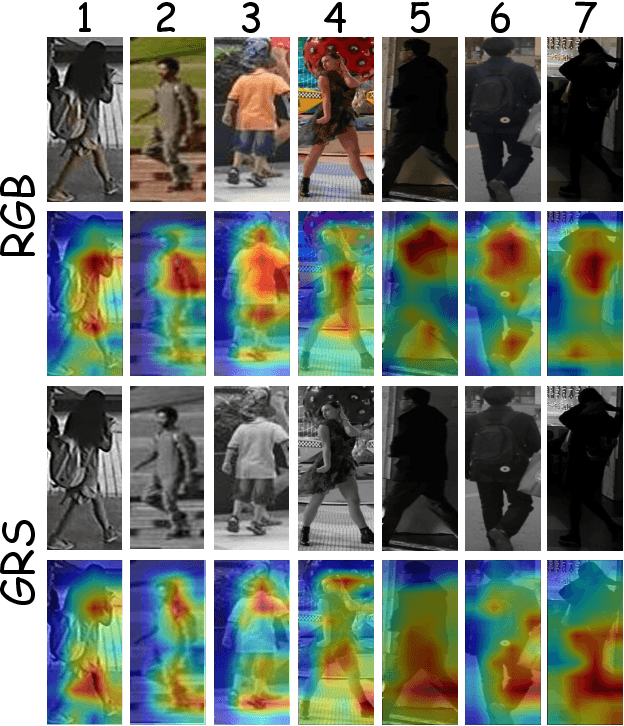
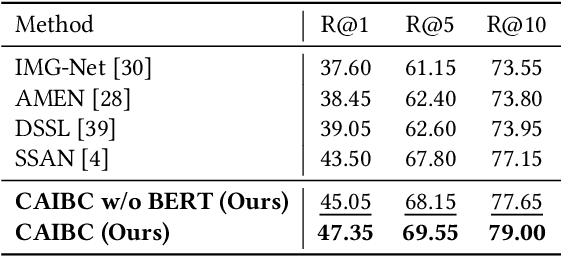
Given a natural language description, text-based person retrieval aims to identify images of a target person from a large-scale person image database. Existing methods generally face a \textbf{color over-reliance problem}, which means that the models rely heavily on color information when matching cross-modal data. Indeed, color information is an important decision-making accordance for retrieval, but the over-reliance on color would distract the model from other key clues (e.g. texture information, structural information, etc.), and thereby lead to a sub-optimal retrieval performance. To solve this problem, in this paper, we propose to \textbf{C}apture \textbf{A}ll-round \textbf{I}nformation \textbf{B}eyond \textbf{C}olor (\textbf{CAIBC}) via a jointly optimized multi-branch architecture for text-based person retrieval. CAIBC contains three branches including an RGB branch, a grayscale (GRS) branch and a color (CLR) branch. Besides, with the aim of making full use of all-round information in a balanced and effective way, a mutual learning mechanism is employed to enable the three branches which attend to varied aspects of information to communicate with and learn from each other. Extensive experimental analysis is carried out to evaluate our proposed CAIBC method on the CUHK-PEDES and RSTPReid datasets in both \textbf{supervised} and \textbf{weakly supervised} text-based person retrieval settings, which demonstrates that CAIBC significantly outperforms existing methods and achieves the state-of-the-art performance on all the three tasks.
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval
Sep 12, 2021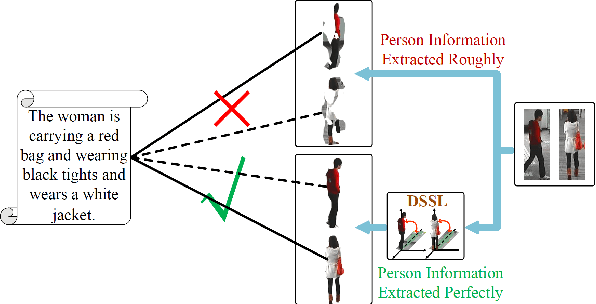
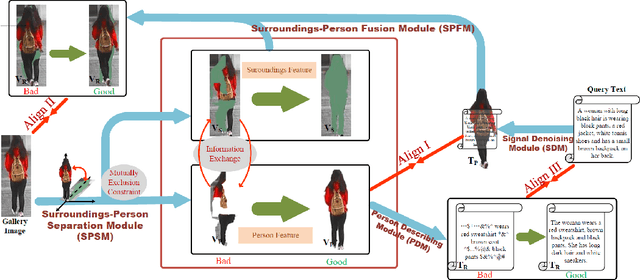
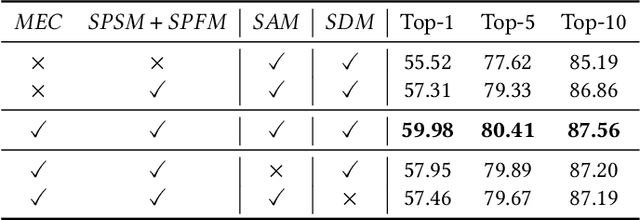
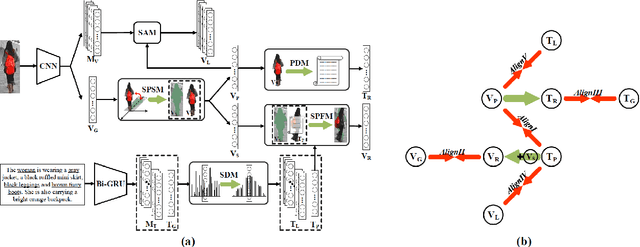
Many previous methods on text-based person retrieval tasks are devoted to learning a latent common space mapping, with the purpose of extracting modality-invariant features from both visual and textual modality. Nevertheless, due to the complexity of high-dimensional data, the unconstrained mapping paradigms are not able to properly catch discriminative clues about the corresponding person while drop the misaligned information. Intuitively, the information contained in visual data can be divided into person information (PI) and surroundings information (SI), which are mutually exclusive from each other. To this end, we propose a novel Deep Surroundings-person Separation Learning (DSSL) model in this paper to effectively extract and match person information, and hence achieve a superior retrieval accuracy. A surroundings-person separation and fusion mechanism plays the key role to realize an accurate and effective surroundings-person separation under a mutually exclusion constraint. In order to adequately utilize multi-modal and multi-granular information for a higher retrieval accuracy, five diverse alignment paradigms are adopted. Extensive experiments are carried out to evaluate the proposed DSSL on CUHK-PEDES, which is currently the only accessible dataset for text-base person retrieval task. DSSL achieves the state-of-the-art performance on CUHK-PEDES. To properly evaluate our proposed DSSL in the real scenarios, a Real Scenarios Text-based Person Reidentification (RSTPReid) dataset is constructed to benefit future research on text-based person retrieval, which will be publicly available.