 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Emergency Disposal Decision-making Method with Human--Machine Collaboration
May 29, 2023Rapid developments in artificial intelligence technology have led to unmanned systems replacing human beings in many fields requiring high-precision predictions and decisions. In modern operational environments, all job plans are affected by emergency events such as equipment failures and resource shortages, making a quick resolution critical. The use of unmanned systems to assist decision-making can improve resolution efficiency, but their decision-making is not interpretable and may make the wrong decisions. Current unmanned systems require human supervision and control. Based on this, we propose a collaborative human--machine method for resolving unplanned events using two phases: task filtering and task scheduling. In the task filtering phase, we propose a human--machine collaborative decision-making algorithm for dynamic tasks. The GACRNN model is used to predict the state of the job nodes, locate the key nodes, and generate a machine-predicted resolution task list. A human decision-maker supervises the list in real time and modifies and confirms the machine-predicted list through the human--machine interface. In the task scheduling phase, we propose a scheduling algorithm that integrates human experience constraints. The steps to resolve an event are inserted into the normal job sequence to schedule the resolution. We propose several human--machine collaboration methods in each phase to generate steps to resolve an unplanned event while minimizing the impact on the original job plan.
Look Before You Leap: Improving Text-based Person Retrieval by Learning A Consistent Cross-modal Common Manifold
Sep 13, 2022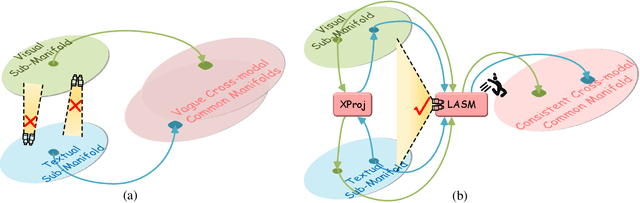
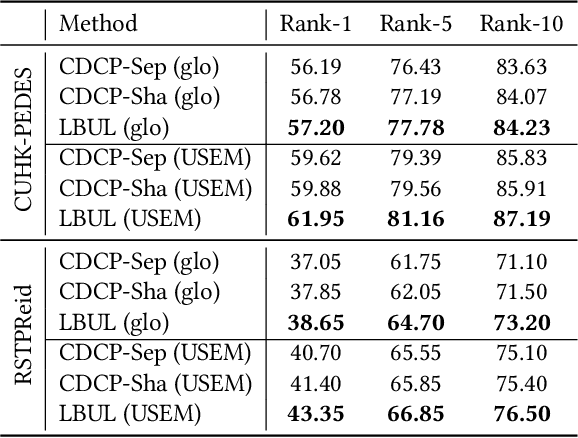
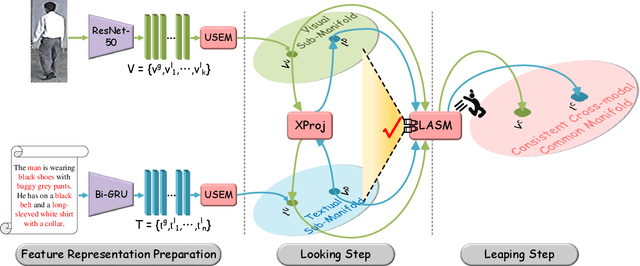
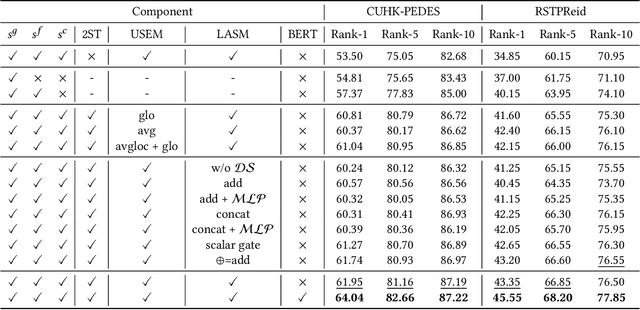
The core problem of text-based person retrieval is how to bridge the heterogeneous gap between multi-modal data. Many previous approaches contrive to learning a latent common manifold mapping paradigm following a \textbf{cross-modal distribution consensus prediction (CDCP)} manner. When mapping features from distribution of one certain modality into the common manifold, feature distribution of the opposite modality is completely invisible. That is to say, how to achieve a cross-modal distribution consensus so as to embed and align the multi-modal features in a constructed cross-modal common manifold all depends on the experience of the model itself, instead of the actual situation. With such methods, it is inevitable that the multi-modal data can not be well aligned in the common manifold, which finally leads to a sub-optimal retrieval performance. To overcome this \textbf{CDCP dilemma}, we propose a novel algorithm termed LBUL to learn a Consistent Cross-modal Common Manifold (C$^{3}$M) for text-based person retrieval. The core idea of our method, just as a Chinese saying goes, is to `\textit{san si er hou xing}', namely, to \textbf{Look Before yoU Leap (LBUL)}. The common manifold mapping mechanism of LBUL contains a looking step and a leaping step. Compared to CDCP-based methods, LBUL considers distribution characteristics of both the visual and textual modalities before embedding data from one certain modality into C$^{3}$M to achieve a more solid cross-modal distribution consensus, and hence achieve a superior retrieval accuracy. We evaluate our proposed method on two text-based person retrieval datasets CUHK-PEDES and RSTPReid. Experimental results demonstrate that the proposed LBUL outperforms previous methods and achieves the state-of-the-art performance.
CAIBC: Capturing All-round Information Beyond Color for Text-based Person Retrieval
Sep 13, 2022
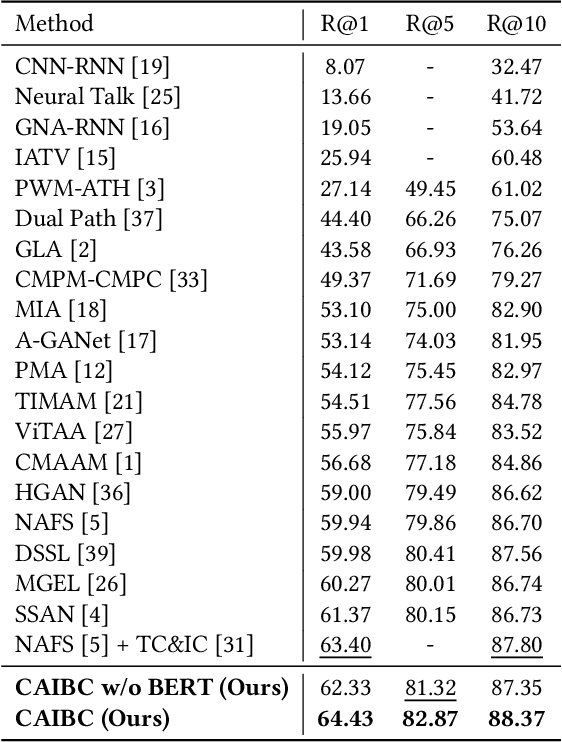
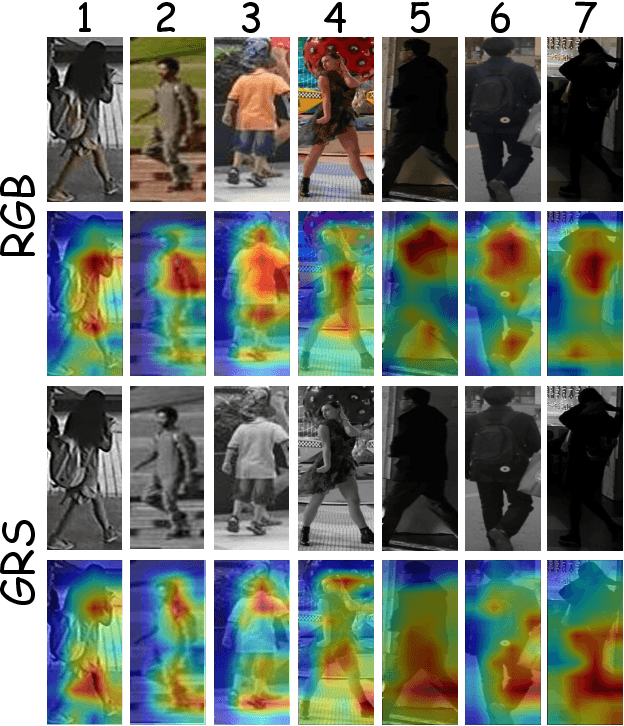
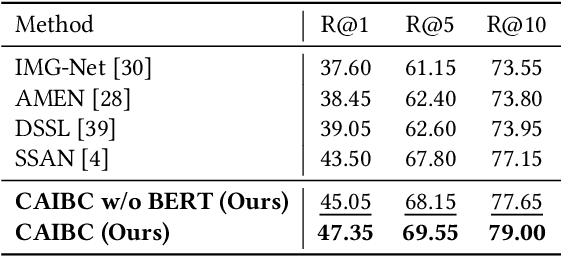
Given a natural language description, text-based person retrieval aims to identify images of a target person from a large-scale person image database. Existing methods generally face a \textbf{color over-reliance problem}, which means that the models rely heavily on color information when matching cross-modal data. Indeed, color information is an important decision-making accordance for retrieval, but the over-reliance on color would distract the model from other key clues (e.g. texture information, structural information, etc.), and thereby lead to a sub-optimal retrieval performance. To solve this problem, in this paper, we propose to \textbf{C}apture \textbf{A}ll-round \textbf{I}nformation \textbf{B}eyond \textbf{C}olor (\textbf{CAIBC}) via a jointly optimized multi-branch architecture for text-based person retrieval. CAIBC contains three branches including an RGB branch, a grayscale (GRS) branch and a color (CLR) branch. Besides, with the aim of making full use of all-round information in a balanced and effective way, a mutual learning mechanism is employed to enable the three branches which attend to varied aspects of information to communicate with and learn from each other. Extensive experimental analysis is carried out to evaluate our proposed CAIBC method on the CUHK-PEDES and RSTPReid datasets in both \textbf{supervised} and \textbf{weakly supervised} text-based person retrieval settings, which demonstrates that CAIBC significantly outperforms existing methods and achieves the state-of-the-art performance on all the three tasks.
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022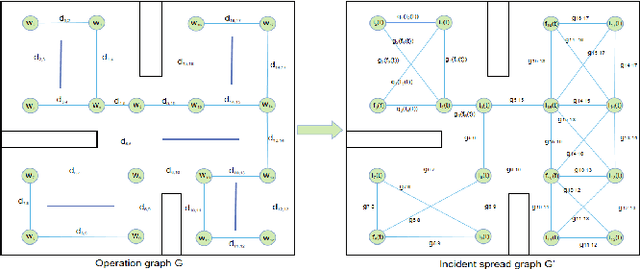
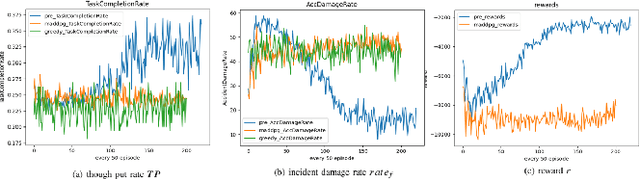
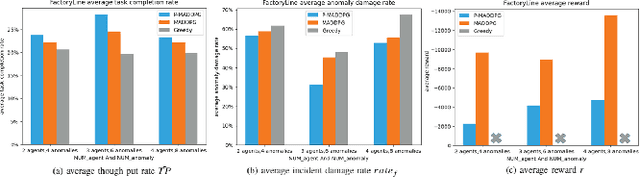

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.