 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
Apr 14, 2026Current LLM agent benchmarks, which predominantly focus on binary pass/fail tasks such as code generation or search-based question answering, often neglect the value of real-world engineering that is often captured through the iterative optimization of feasible designs. To this end, we introduce Frontier-Eng, a human-verified benchmark for generative optimization -- an iterative propose-execute-evaluate loop in which an agent generates candidate artifacts, receives executable verifier feedback, and revises them under a fixed interaction budget -- spanning $47$ tasks across five broad engineering categories. Unlike previous suites, Frontier-Eng tasks are grounded in industrial-grade simulators and verifiers that provide continuous reward signals and enforce hard feasibility constraints under constrained budgets. We evaluate eight frontier language models using representative search frameworks, finding that while Claude 4.6 Opus achieves the most robust performance, the benchmark remains challenging for all models. Our analysis suggests a dual power-law decay in improvement frequency ($\sim$ 1/iteration) and magnitude ($\sim$ 1/improvement count). We further show that although width improves parallelism and diversity, depth remains crucial for hard-won improvements under a fixed budget. Frontier-Eng establishes a new standard for assessing the capacity of AI agents to integrate domain knowledge with executable feedback to solve complex, open-ended engineering problems.
ST4VLA: Spatially Guided Training for Vision-Language-Action Models
Feb 10, 2026Large vision-language models (VLMs) excel at multimodal understanding but fall short when extended to embodied tasks, where instructions must be transformed into low-level motor actions. We introduce ST4VLA, a dual-system Vision-Language-Action framework that leverages Spatial Guided Training to align action learning with spatial priors in VLMs. ST4VLA includes two stages: (i) spatial grounding pre-training, which equips the VLM with transferable priors via scalable point, box, and trajectory prediction from both web-scale and robot-specific data, and (ii) spatially guided action post-training, which encourages the model to produce richer spatial priors to guide action generation via spatial prompting. This design preserves spatial grounding during policy learning and promotes consistent optimization across spatial and action objectives. Empirically, ST4VLA achieves substantial improvements over vanilla VLA, with performance increasing from 66.1 -> 84.6 on Google Robot and from 54.7 -> 73.2 on WidowX Robot, establishing new state-of-the-art results on SimplerEnv. It also demonstrates stronger generalization to unseen objects and paraphrased instructions, as well as robustness to long-horizon perturbations in real-world settings. These results highlight scalable spatially guided training as a promising direction for robust, generalizable robot learning. Source code, data and models are released at https://internrobotics.github.io/internvla-m1.github.io/
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025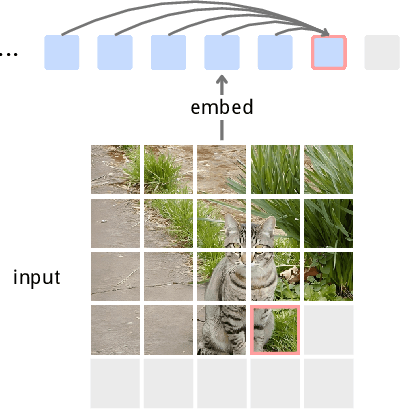
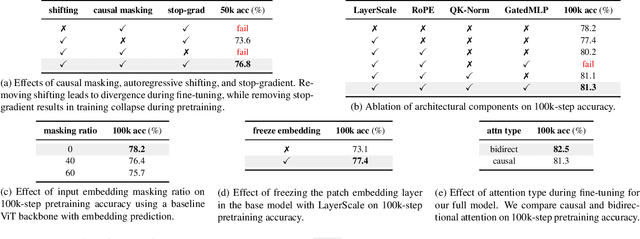
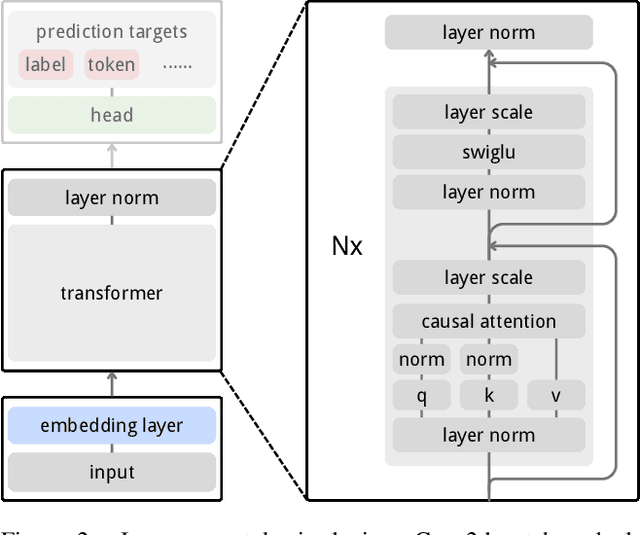
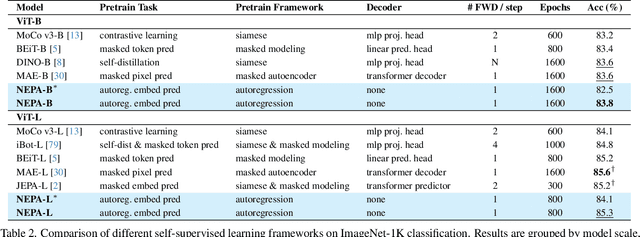
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
SRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
Oct 14, 2025Recently, remarkable progress has been made in Unified Multimodal Models (UMMs), which integrate vision-language generation and understanding capabilities within a single framework. However, a significant gap exists where a model's strong visual understanding often fails to transfer to its visual generation. A model might correctly understand an image based on user instructions, yet be unable to generate a faithful image from text prompts. This phenomenon directly raises a compelling question: Can a model achieve self-improvement by using its understanding module to reward its generation module? To bridge this gap and achieve self-improvement, we introduce SRUM, a self-rewarding post-training framework that can be directly applied to existing UMMs of various designs. SRUM creates a feedback loop where the model's own understanding module acts as an internal ``evaluator'', providing corrective signals to improve its generation module, without requiring additional human-labeled data. To ensure this feedback is comprehensive, we designed a global-local dual reward system. To tackle the inherent structural complexity of images, this system offers multi-scale guidance: a \textbf{global reward} ensures the correctness of the overall visual semantics and layout, while a \textbf{local reward} refines fine-grained, object-level fidelity. SRUM leads to powerful capabilities and shows strong generalization, boosting performance on T2I-CompBench from 82.18 to \textbf{88.37} and on T2I-ReasonBench from 43.82 to \textbf{46.75}. Overall, our work establishes a powerful new paradigm for enabling a UMMs' understanding module to guide and enhance its own generation via self-rewarding.
Unveiling the Backbone-Optimizer Coupling Bias in Visual Representation Learning
Oct 08, 2024



This paper delves into the interplay between vision backbones and optimizers, unvealing an inter-dependent phenomenon termed \textit{\textbf{b}ackbone-\textbf{o}ptimizer \textbf{c}oupling \textbf{b}ias} (BOCB). We observe that canonical CNNs, such as VGG and ResNet, exhibit a marked co-dependency with SGD families, while recent architectures like ViTs and ConvNeXt share a tight coupling with the adaptive learning rate ones. We further show that BOCB can be introduced by both optimizers and certain backbone designs and may significantly impact the pre-training and downstream fine-tuning of vision models. Through in-depth empirical analysis, we summarize takeaways on recommended optimizers and insights into robust vision backbone architectures. We hope this work can inspire the community to question long-held assumptions on backbones and optimizers, stimulate further explorations, and thereby contribute to more robust vision systems. The source code and models are publicly available at https://bocb-ai.github.io/.
Switch EMA: A Free Lunch for Better Flatness and Sharpness
Feb 14, 2024Exponential Moving Average (EMA) is a widely used weight averaging (WA) regularization to learn flat optima for better generalizations without extra cost in deep neural network (DNN) optimization. Despite achieving better flatness, existing WA methods might fall into worse final performances or require extra test-time computations. This work unveils the full potential of EMA with a single line of modification, i.e., switching the EMA parameters to the original model after each epoch, dubbed as Switch EMA (SEMA). From both theoretical and empirical aspects, we demonstrate that SEMA can help DNNs to reach generalization optima that better trade-off between flatness and sharpness. To verify the effectiveness of SEMA, we conduct comparison experiments with discriminative, generative, and regression tasks on vision and language datasets, including image classification, self-supervised learning, object detection and segmentation, image generation, video prediction, attribute regression, and language modeling. Comprehensive results with popular optimizers and networks show that SEMA is a free lunch for DNN training by improving performances and boosting convergence speeds.
SemiReward: A General Reward Model for Semi-supervised Learning
Oct 04, 2023



Semi-supervised learning (SSL) has witnessed great progress with various improvements in the self-training framework with pseudo labeling. The main challenge is how to distinguish high-quality pseudo labels against the confirmation bias. However, existing pseudo-label selection strategies are limited to pre-defined schemes or complex hand-crafted policies specially designed for classification, failing to achieve high-quality labels, fast convergence, and task versatility simultaneously. To these ends, we propose a Semi-supervised Reward framework (SemiReward) that predicts reward scores to evaluate and filter out high-quality pseudo labels, which is pluggable to mainstream SSL methods in wide task types and scenarios. To mitigate confirmation bias, SemiReward is trained online in two stages with a generator model and subsampling strategy. With classification and regression tasks on 13 standard SSL benchmarks of three modalities, extensive experiments verify that SemiReward achieves significant performance gains and faster convergence speeds upon Pseudo Label, FlexMatch, and Free/SoftMatch.
Multi-scale Fusion Fault Diagnosis Method Based on Two-Dimensionaliztion Sequence in Complex Scenarios
Apr 11, 2023Rolling bearings are critical components in rotating machinery, and their faults can cause severe damage. Early detection of abnormalities is crucial to prevent catastrophic accidents. Traditional and intelligent methods have been used to analyze time series data, but in real-life scenarios, sensor data is often noisy and cannot be accurately characterized in the time domain, leading to mode collapse in trained models. Two-dimensionalization methods such as the Gram angle field method (GAF) or interval sampling have been proposed, but they lack mathematical derivation and interpretability. This paper proposes an improved GAF combined with grayscale images for convolution scenarios. The main contributions include illustrating the feasibility of the approach in complex scenarios, widening the data set, and introducing an improved convolutional neural network method with a multi-scale feature fusion diffusion model and deep learning compression techniques for deployment in industrial scenarios.
Interpretable ODE-style Generative Diffusion Model via Force Field Construction
Mar 15, 2023For a considerable time, researchers have focused on developing a method that establishes a deep connection between the generative diffusion model and mathematical physics. Despite previous efforts, progress has been limited to the pursuit of a single specialized method. In order to advance the interpretability of diffusion models and explore new research directions, it is essential to establish a unified ODE-style generative diffusion model. Such a model should draw inspiration from physical models and possess a clear geometric meaning. This paper aims to identify various physical models that are suitable for constructing ODE-style generative diffusion models accurately from a mathematical perspective. We then summarize these models into a unified method. Additionally, we perform a case study where we use the theoretical model identified by our method to develop a range of new diffusion model methods, and conduct experiments. Our experiments on CIFAR-10 demonstrate the effectiveness of our approach. We have constructed a computational framework that attains highly proficient results with regards to image generation speed, alongside an additional model that demonstrates exceptional performance in both Inception score and FID score. These results underscore the significance of our method in advancing the field of diffusion models.