 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Geometric Constraints on Dense Trajectories for Motion Saliency
Sep 29, 2019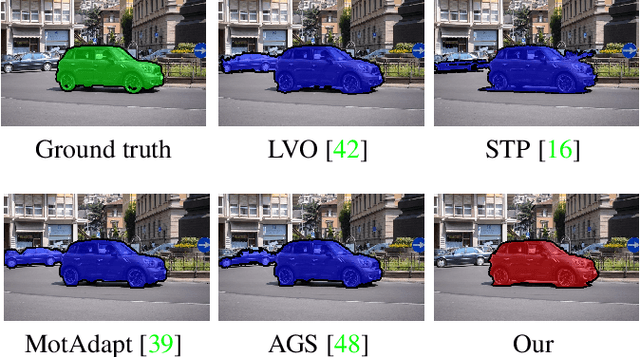

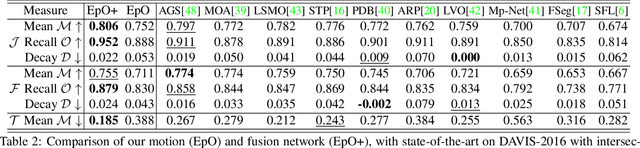
The existing approaches for salient motion segmentation are unable to explicitly learn geometric cues and often give false detections on prominent static objects. We exploit multiview geometric constraints to avoid such mistakes. To handle nonrigid background like sea, we also propose a robust fusion mechanism between motion and appearance-based features. We find dense trajectories, covering every pixel in the video, and propose trajectory-based epipolar distances to distinguish between background and foreground regions. Trajectory epipolar distances are data-independent and can be readily computed given a few features' correspondences in the images. We show that by combining epipolar distances with optical flow, a powerful motion network can be learned. Enabling the network to leverage both of these information, we propose a simple mechanism, we call input-dropout. We outperform the previous motion network on DAVIS-2016 dataset by 5.2% in mean IoU score. By robustly fusing our motion network with an appearance network using the proposed input-dropout, we also outperform the previous methods on DAVIS-2016, 2017 and Segtrackv2 dataset.
Super-Trajectories: A Compact Yet Rich Video Representation
Jan 22, 2019



We propose a new video representation in terms of an over-segmentation of dense trajectories covering the whole video. Trajectories are often used to encode long-temporal information in several computer vision applications. Similar to temporal superpixels, a temporal slice of super-trajectories are superpixels, but the later contains more information because it maintains the long dense pixel-wise tracking information as well. The main challenge in using trajectories for any application, is the accumulation of tracking error in the trajectory construction. For our problem, this results in disconnected superpixels. We exploit constraints for edges in addition to trajectory based color and position similarity. Analogous to superpixels as a preprocessing tool for images, the proposed representation has its applications for videos, especially in trajectory based video analysis.
Towards Accurate Markerless Human Shape and Pose Estimation over Time
Apr 30, 2018



Existing marker-less motion capture methods often assume known backgrounds, static cameras, and sequence specific motion priors, which narrows its application scenarios. Here we propose a fully automatic method that given multi-view video, estimates 3D human motion and body shape. We take recent SMPLify \cite{bogo2016keep} as the base method, and extend it in several ways. First we fit the body to 2D features detected in multi-view images. Second, we use a CNN method to segment the person in each image and fit the 3D body model to the contours to further improves accuracy. Third we utilize a generic and robust DCT temporal prior to handle the left and right side swapping issue sometimes introduced by the 2D pose estimator. Validation on standard benchmarks shows our results are comparable to the state of the art and also provide a realistic 3D shape avatar. We also demonstrate accurate results on HumanEva and on challenging dance sequences from YouTube in monocular case.